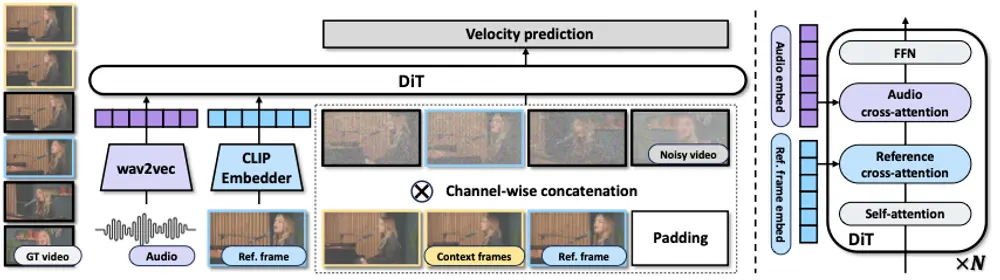
文本到视频(T2V)生成模型近年来取得了显著进展,能够生成高质量的合成视频。然而,这些模型在将合成视频与人类偏好(例如,准确反映文本描述)对齐方面仍然存在不足。复旦大学、上海人工智能科学院和阿德莱德大学澳大利亚机器学习研究所的研究人员提出了 LIFT(Learning from In-the-wild Feedback for Text-to-Video),这是一种利用人类反馈进行 T2V 模型对齐的新型微调方法。LiFT的核心功能是通过利用人类反馈来微调T2V模型,使其生成的视频更符合人类的期望和偏好。这包括提高视频与文本描述的语义一致性、视频流畅度和视频质量。
- 项目主页:https://codegoat24.github.io/LiFT
- GitHub:https://github.com/CodeGoat24/LiFT
- 模型地址:https://huggingface.co/collections/Fudan-FUXI/lift-6756e628d83c390221e02857

核心挑战
- 主观性问题:人类偏好本质上是主观的,难以形式化为客观函数。
- 对齐困难:确保生成的视频不仅在视觉上逼真,还能准确反映文本描述中的语义和情感,这是一项复杂的任务。
LIFT 的解决方案
1. 构建人类评分注释数据集 LIFTHRA
为了克服上述挑战,研究人员首先构建了一个名为 LIFTHRA 的大规模人类评分注释数据集。该数据集包含约 10,000 个人类注释,每个注释包括一个分数及其对应的原因。这些注释涵盖了多种文本到视频生成的任务,帮助模型更好地理解人类对生成视频的期望。
- 注释内容:每个注释不仅包含一个评分(通常为 1 到 5 分),还附带了详细的原因说明,解释为什么给定的分数。这种细粒度的反馈有助于模型学习到更丰富的对齐信息。
- 多样性:LIFTHRA 数据集涵盖了广泛的文本描述和生成视频类型,确保模型能够在多样化的场景中进行有效的对齐。
2. 训练奖励模型 LIFT-CRITIC
基于 LIFTHRA 数据集,研究人员训练了一个 奖励模型 LIFT-CRITIC,用于学习一个奖励函数。该奖励函数作为人类判断的代理,衡量给定视频与人类期望之间的对齐程度。
- 奖励函数的作用:LIFT-CRITIC 学习到的奖励函数能够评估生成视频的质量,特别是它是否准确反映了文本描述中的语义和情感。通过这种方式,模型可以在生成过程中不断优化,确保输出的视频更符合人类的期望。
- 训练过程:LIFT-CRITIC 通过监督学习的方式进行训练,使用 LIFTHRA 中的人类评分和原因作为标签,逐步调整模型参数,使其能够更好地预测人类的偏好。
3. 通过最大化奖励加权似然进行模型对齐
最后,研究人员利用学习到的奖励函数,通过 最大化奖励加权似然 来对齐 T2V 模型。具体来说,模型在生成视频时,会根据 LIFT-CRITIC 提供的奖励信号,动态调整生成策略,以确保生成的视频尽可能接近人类的期望。
- 优化目标:模型的目标是最大化生成视频的奖励值,即让生成的视频在 LIFT-CRITIC 的评估下获得更高的分数。这使得模型能够在生成过程中不断改进,最终生成更符合人类偏好的视频。
- 案例研究:研究人员将 LIFT 流程应用于 CogVideoX-2B 模型,并将其与未经过微调的 CogVideoX-5B 模型进行了对比。结果显示,微调后的 CogVideoX-2B 在所有 16 个指标 上均优于 CogVideoX-5B,突显了人类反馈在提高合成视频对齐和质量方面的潜力。
实验结果与优势
- 性能提升:微调后的 CogVideoX-2B 模型在多个指标上表现出显著的性能提升,特别是在视频与文本描述的对齐度、视觉质量和语义一致性方面。
- 泛化能力:LIFT 方法不仅适用于特定的 T2V 模型,还可以扩展到其他多模态生成任务,如图像生成、语音合成等。
- 可解释性:通过 LIFTHRA 数据集中的人类反馈,LIFT 模型能够生成更具解释性的视频,用户可以清楚地了解为什么某个视频获得了较高的评分。
- 灵活性:LIFT 方法可以根据不同的应用场景和用户需求进行定制化调整,适应多样化的生成任务。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











