可控的人体图像动画旨在使用驱动视频从参考图像生成视频。为了确保运动对齐,最近的工作尝试引入额外的密集条件(例如,深度图),但这些方法在参考角色的体型与驱动视频中的体型显著不同时,可能会损害生成视频的质量。这种严格的密集指导虽然有助于精确的运动对齐,但也限制了模型的泛化能力。
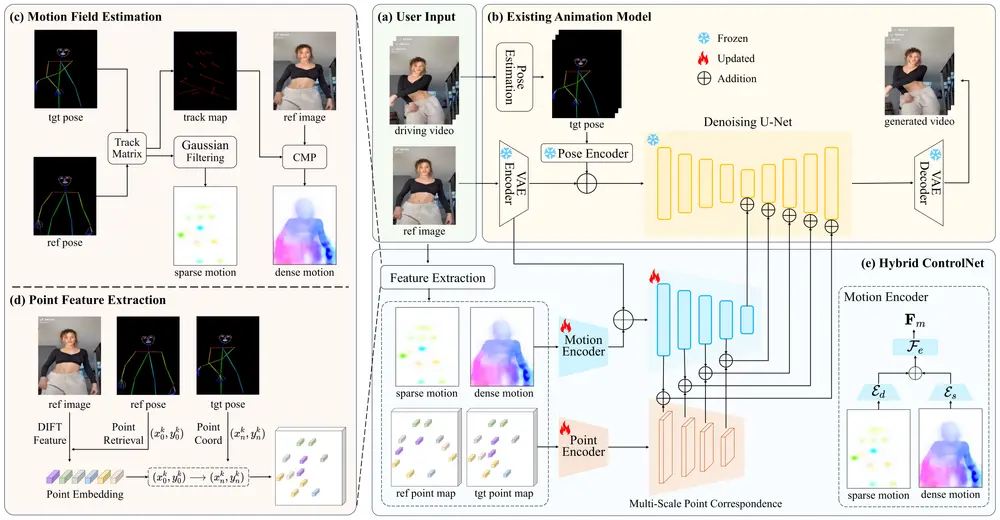
为了解决这一问题,北京大学、中国科技大学、清华大学和香港科技大学的研究人员提出了DisPose,这是一种新的方法,旨在挖掘更通用和有效的控制信号,而无需额外的密集输入。DisPose通过将稀疏骨骼姿势解耦为运动场指导和关键点对应,既提供了区域级的密集指导,又保持了稀疏姿势控制的泛化能力。DisPose旨在提高可控人物图像动画的质量。这种技术能够从参考图像和驱动视频中生成视频,同时保持人物外观的一致性,并允许对动画进行精确控制。

例如,我们有一张静态的人物照片和一个人物动作视频。DisPose技术能够将照片中的人物动画化,使其按照驱动视频中的动作进行活动,同时保持照片中人物的外貌特征。例如,我们可以将一张微笑的人物照片动画化,使其在视频中行走或跳舞,而面部表情和整体外观保持与照片中一致。
DisPose的核心创新
1. 稀疏运动场到密集运动场的生成
DisPose的关键思想是从稀疏运动场和参考图像生成密集运动场,从而提供区域级的密集指导。具体来说:
- 稀疏运动场:首先,DisPose从驱动视频中提取稀疏的骨骼姿势,生成稀疏运动场。这些稀疏运动场包含了关键关节的运动信息。
- 密集运动场生成:然后,DisPose利用这些稀疏运动场和参考图像,生成密集的运动场。密集运动场不仅包含了关键关节的运动信息,还扩展到了整个图像的各个区域,提供了更细粒度的运动指导。这种方法能够在保持稀疏姿势控制的泛化能力的同时,提供更丰富的运动信息,确保生成的视频在运动上更加自然和连贯。
2. 关键点对应的扩散特征提取与转移
为了确保生成视频中的人物身份一致,DisPose还引入了一种基于关键点对应的方法,用于提取和转移扩散特征。具体来说:
- 扩散特征提取:DisPose从参考图像中提取与姿势关键点对应的扩散特征。这些特征不仅包含了关键点的位置信息,还捕捉了局部的纹理和外观信息,确保生成的视频中的人物身份特征得以保留。
- 特征转移:然后,DisPose将这些扩散特征转移到目标姿势上,使得生成的视频在保持运动一致性的同时,也能够准确地保留人物的身份特征。这种方法有效地解决了传统方法中由于体型差异导致的身份丢失问题。
3. 即插即用的混合ControlNet
为了无缝集成到现有的生成模型中,研究人员提出了一个即插即用的混合ControlNet。该ControlNet可以在冻结现有模型参数的情况下,提升生成视频的质量和一致性。具体来说:
- 即插即用设计:混合ControlNet可以作为一个模块,直接插入到现有的生成模型中,而不需要对模型进行大规模的修改或重新训练。这使得DisPose可以轻松应用于各种现有的人体图像动画模型。
- 质量提升:通过引入DisPose的稀疏运动场和关键点对应机制,混合ControlNet能够显著提升生成视频的质量,尤其是在处理体型差异较大的情况下。实验结果表明,DisPose在生成视频的质量和一致性方面均优于现有的方法。
主要功能:
- 运动场引导(Motion Field Guidance):从稀疏的运动场(如骨架姿态)生成密集的运动场,提供区域级别的详细指导,同时保持对不同体型的泛化能力。
- 关键点对应(Keypoint Correspondence):从参考图像中提取与姿态关键点相对应的扩散特征,并将这些特征转移到目标姿态,以提供独特的身份信息。
- 混合ControlNet:一个即插即用的模块,可以改善生成视频的质量和一致性,同时冻结现有模型参数。
主要特点:
- 无需额外的密集输入:DisPose不需要额外的密集输入,如深度图或3D模型,而是直接从骨架姿态和参考图像中提取控制信号。
- 提高动画质量:通过运动场和关键点对应,DisPose能够生成更高质量的动画视频。
- 即插即用:DisPose作为一个模块可以无缝集成到现有的动画模型中。
工作原理:
- 运动场估计:首先,使用DWPose估计骨架姿态,然后基于骨架姿态和参考图像计算稀疏运动场,再通过高斯滤波和条件运动传播(CMP)生成稀疏和密集运动场。
- 关键点特征提取:从参考图像中提取与姿态关键点相对应的扩散特征(DIFT),并将这些特征映射到目标姿态。
- 混合ControlNet:将运动场引导和关键点对应整合到一个类似于ControlNet的网络中,以便将这些控制信号注入到潜在的视频扩散模型中,生成准确的人物图像动画。
实验结果
1. 广泛的定性和定量评估
研究人员进行了广泛的定性和定量实验,验证了DisPose的有效性。具体来说:
- 定性评估:通过视觉对比,DisPose生成的视频在运动对齐和身份保留方面表现出色,尤其是在处理体型差异较大的情况下。生成的视频不仅动作自然流畅,而且人物的身份特征得到了很好的保留。
- 定量评估:在多个基准数据集上,DisPose在多种评价指标(如PSNR、SSIM、FID等)上均取得了显著的性能提升,特别是在处理复杂动作和体型差异较大的情况下,DisPose的表现尤为突出。
2. 优越性
实验结果表明,DisPose相对于当前方法具有明显的优越性:
- 更好的运动对齐:DisPose通过生成密集运动场,确保了生成视频中的动作与驱动视频中的动作高度对齐,即使在体型差异较大的情况下也能保持良好的运动一致性。
- 更强的身份保留:通过关键点对应的扩散特征提取与转移,DisPose能够有效地保留生成视频中的人物身份特征,避免了传统方法中常见的身份丢失问题。
- 更高的泛化能力:DisPose的稀疏运动场和关键点对应机制使得模型能够在不同的体型和场景下保持良好的泛化能力,适用于更广泛的应用场景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











