
由前微软全球副总裁、微软亚洲互联网工程院首席科学家姜大昕创办的AI公司阶跃星辰,开源了一款强大的文生视频模型——Step-Video-T2V。该模型拥有 300 亿参数,能够生成长达 204 帧的高质量视频。
- GitHub:https://github.com/stepfun-ai/Step-Video-T2V
- 模型:Step-Video-T2V|Step-Video-T2V-Turbo
- 官网:https://yuewen.cn/videos
通过深度压缩变分自编码器(Video-VAE)和基于扩散模型的架构,Step-Video-T2V 实现了高效的视频生成,并通过多种优化技术提升了生成视频的质量和多样性。此外,模型还引入了基于人类偏好的优化方法(Video-DPO),进一步提升了生成视频的视觉质量。

一、主要功能
- 文本到视频生成:用户只需输入文本提示,模型即可生成与描述匹配的视频内容。
- 多语言支持:支持中文和英文提示,能够理解不同语言的输入并生成相应的视频。
- 高质量视频生成:生成的视频具有高分辨率(544×992),在运动连贯性、视觉美感和内容一致性方面表现出色。
- 视频编辑与理解:可用于视频编辑任务,例如根据文本提示对现有视频进行修改或增强。
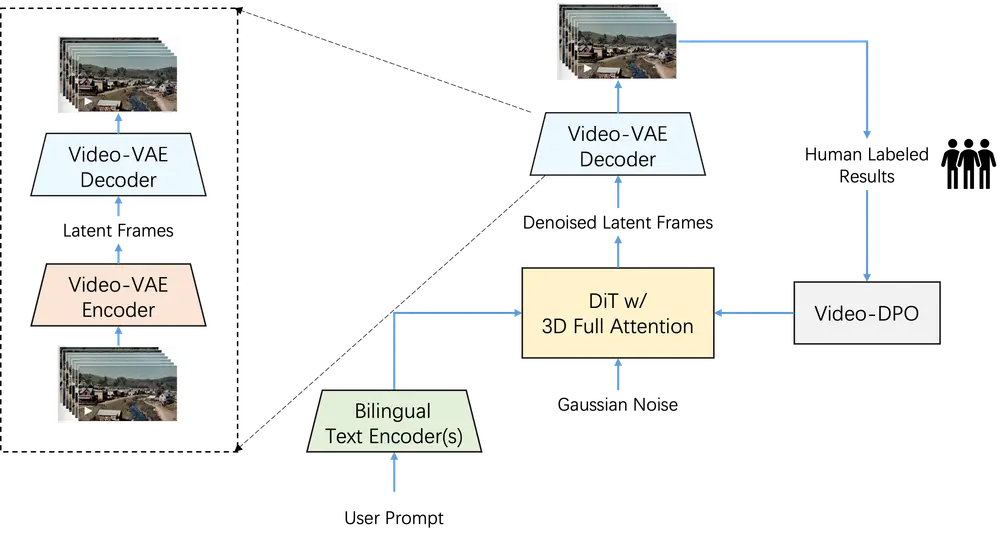
二、模型概述
1. 视频压缩与编码
Step-Video-T2V 使用深度压缩变分自编码器(Video-VAE),实现了 16×16 的空间压缩比和 8× 的时间压缩比,同时保持了出色的视频重建质量。这种压缩不仅加速了训练和推理,还与扩散过程对压缩表示的偏好相一致。
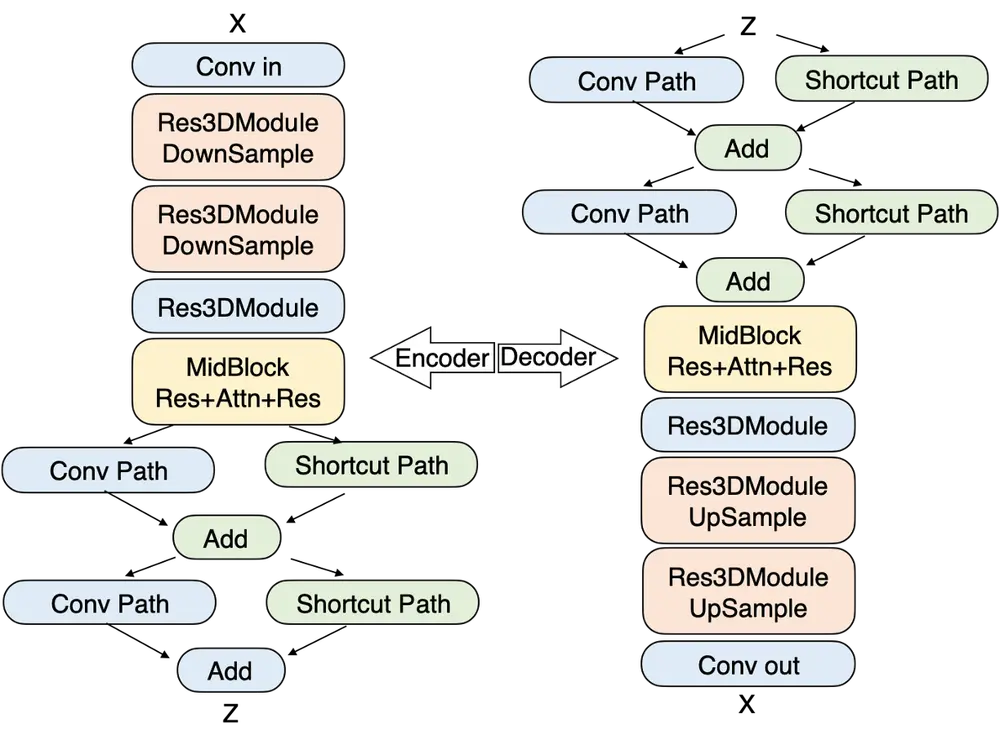
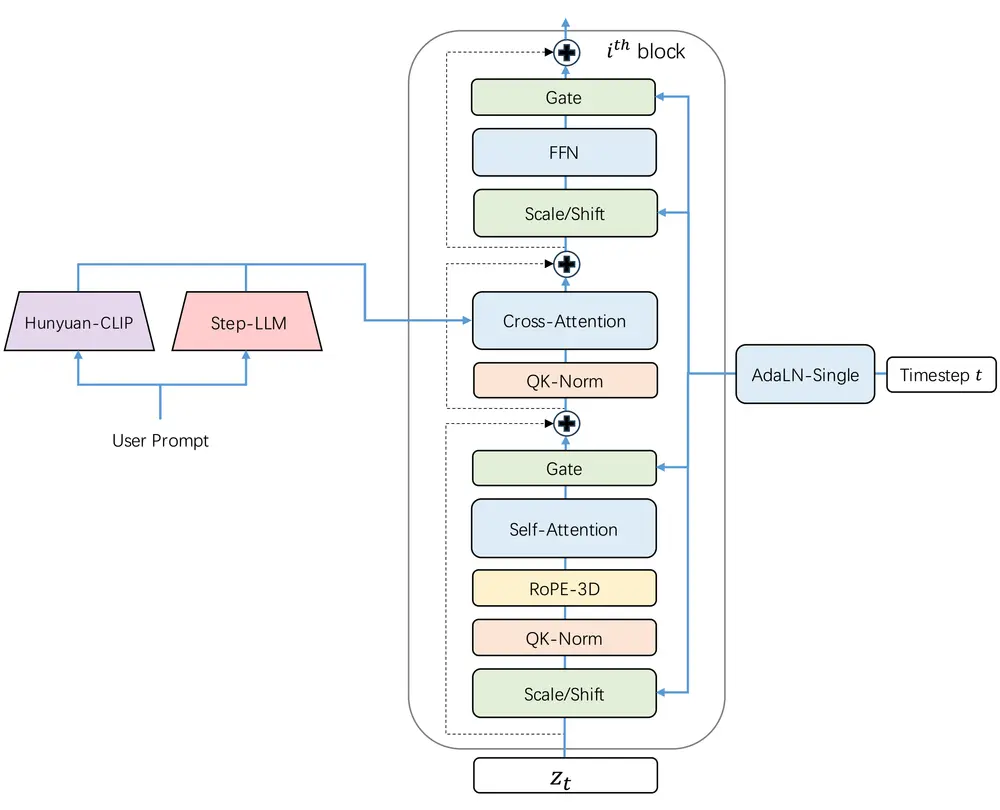
2. 3D 全注意力架构
基于 DiT 架构,Step-Video-T2V 拥有 48 层,每层包含 48 个注意力头,每个头的维度为 128。模型通过 AdaLN-Single 合并时间步长条件,并在自注意力机制中引入 QK-Norm 以确保训练稳定性。此外,3D RoPE 在处理不同视频长度和分辨率的序列中发挥了关键作用。
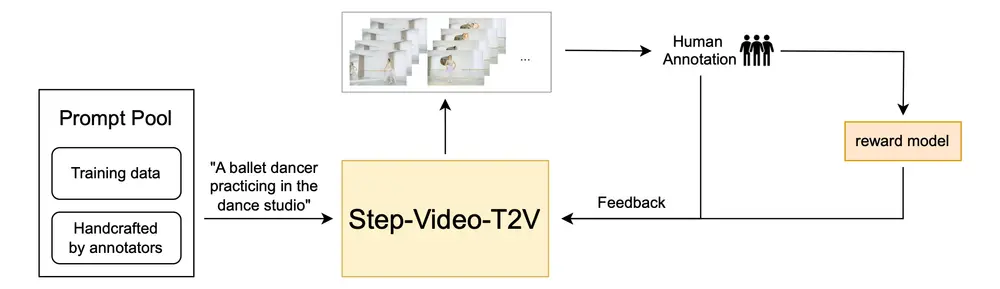
3. 基于人类偏好的优化(Video-DPO)
Step-Video-T2V 通过直接偏好优化(DPO)结合人类反馈,进一步提升生成视频的视觉质量。DPO 利用人类偏好数据微调模型,确保生成内容更贴近人类期望。
三、模型使用
1. 硬件要求
运行 Step-Video-T2V 模型需要支持 CUDA 的 NVIDIA GPU。以下是不同配置下的资源需求:
| 模型 | 分辨率 | 峰值 GPU 内存 | 50 步(带 Flash-Attn) | 50 步(不带 Flash-Attn) |
|---|---|---|---|---|
| Step-Video-T2V | 544×992×204 帧 | 77.64 GB | 743 秒 | 1232 秒 |
| Step-Video-T2V | 544×992×136 帧 | 72.48 GB | 408 秒 | 605 秒 |
建议使用 80GB 显存的 GPU 以获得更好的生成质量,测试操作系统为 Linux。
2. 推理脚本
模型采用分离策略,将文本编码器、VAE 解码和 DiT 分别处理,以优化 GPU 资源利用率。因此,需要一个专用 GPU 来处理文本编码器的嵌入和 VAE 解码的 API 服务。
3. 最佳实践推理设置
为了获得最佳生成效果,建议调整以下推理参数:
| 模型 | 推理步数(INFER_STEPS) | CFG 缩放(CFG_SCALE) | 时间偏移(TIME_SHIFT) | 帧数(NUM_FRAMES) |
|---|---|---|---|---|
| Step-Video-T2V | 30-50 | 9.0 | 13.0 | 204 |
| Step-Video-T2V-Turbo | 10-15 | 5.0 | 17.0 | 204 |
四、基准测试
为了评估模型性能,阶跃星辰发布了 Step-Video-T2V Eval 基准测试,包含 128 个真实用户的中文提示。该基准测试覆盖 11 个不同类别:体育、食物、风景、动物、节日、组合概念、超现实、人物、3D 动画、电影摄影和风格。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











