由北大-兔展AIGC联合实验室共同发起的Open-Sora Plan,目标是复现OpenAI的Sora模型。这是一个开源的大型视频生成模型项目,旨在基于多种用户输入生成高分辨率、长时长的理想视频。该项目包括多个组件,涵盖了从数据预处理到模型部署的整个视频生成过程,主要组件包括Wavelet-Flow变分自编码器(VAE)、联合图像-视频Skiparse去噪器以及各种条件控制器。此外,论文还提出了一系列高效的训练和推理策略,以及一个多维数据筛选流程,以获取高质量的数据。
- GitHub:https://github.com/PKU-YuanGroup/Open-Sora-Plan
- 模型:https://huggingface.co/LanguageBind/Open-Sora-Plan-v1.3.0
例如,如果用户想要生成一个视频,描述“一只好奇的猫从一个舒适的隐藏处探出头来”,Open-Sora Plan能够根据这个文本提示生成一个视频,展示这一场景。此外,它还可以根据用户提供的特定结构信号(如边缘检测、深度图、草图等)来控制视频内容的生成。
主要功能和特点
- 多模态输入:支持文本、图像和结构信号等多种输入条件,实现精准的视频内容生成。
- 高效训练策略:包括MinMax Token策略、自适应梯度裁剪策略和提示优化策略,提高训练效率和模型性能。
- 多维数据筛选:自动化的数据筛选流程,确保数据的高质量,提升模型训练效果。
- 条件控制器:包括图像条件控制器和结构条件控制器,实现对视频生成的精细控制。
工作原理
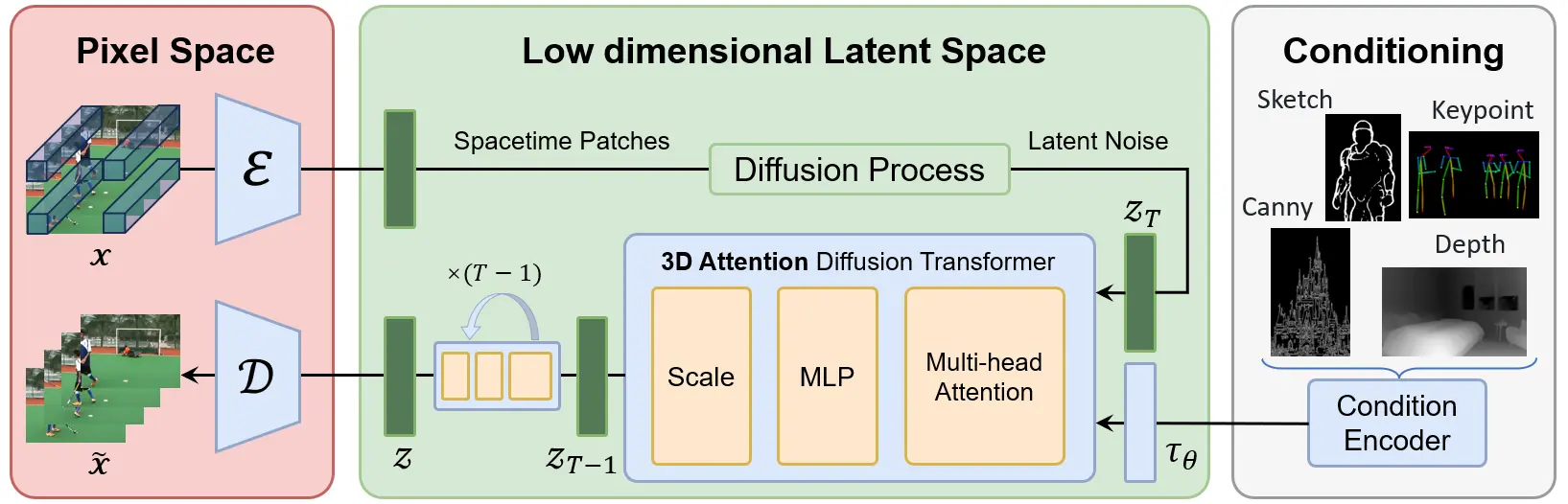
- Wavelet-Flow VAE:通过多级小波变换在频率域获取多尺度特征,并将这些特征注入到卷积网络中,以压缩视频信号并为后续的扩散模型提供输入。
- 联合图像-视频Skiparse去噪器:在低维潜在空间中学习去噪过程,将输入的潜在表示转换为清晰的视频帧。
- 条件控制器:通过特定的结构信号(如Canny边缘、深度图等)来控制视频内容的生成,实现精确的视频内容操控。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











