
腾讯在今天正式开源了其最新的视频生成模型—混元文生视频模型HunyuanVideo。这款模型不仅在视频生成能力上与业界领先的闭源模型相匹敌,甚至在某些方面表现更为出色。作为一款综合性的框架,HunyuanVideo集成了数据处理、图像-视频联合训练以及高效的基础设施等关键组件,特别针对大规模模型训练和推理进行了优化。
- 项目主页:https://aivideo.hunyuan.tencent.com
- GitHub:https://github.com/Tencent/HunyuanVideo
- 模型:https://huggingface.co/tencent/HunyuanVideo
- 量化版本:https://huggingface.co/Kijai/HunyuanVideo_comfy
- GGUF版本:https://huggingface.co/city96/HunyuanVideo-gguf
模型规模与特性
HunyuanVideo成功训练了一个参数量超过130亿的大型视频生成模型,这使它成为当前所有开源模型中规模最大的一个。通过引入先进的模型架构设计和扩展策略,该模型能够提供高质量的视觉效果、丰富的运动多样性、精准的文本-视频对齐以及稳定的生成性能。根据专业评估团队的反馈,HunyuanVideo在多个维度上的表现优于包括Runway Gen-3、Luma 1.6在内的多个顶尖视频生成模型,尤其是中文视频生成领域。

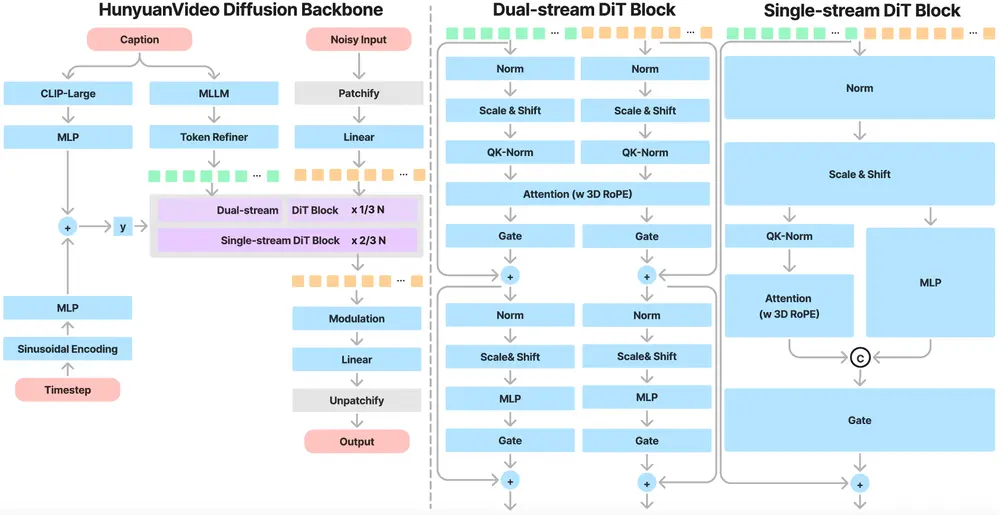
HunyuanVideo 总体架构
HunyuanVideo在时空压缩的潜在空间上进行训练,该空间通过Causal 3D VAE进行压缩。文本提示使用大型语言模型进行编码,并作为条件输入。高斯噪声和条件作为输入,我们的生成模型生成一个输出潜在变量,该变量通过3D VAE解码器解码为图像或视频。

HunyuanVideo 的核心技术
统一的图像和视频生成架构
HunyuanVideo采用了基于Transformer的“双流到单流”混合模型设计,先独立处理视频和文本令牌,再将它们融合以实现多模态信息的有效整合。这种设计有助于捕捉视觉与语义信息间的复杂关系,从而提升整体模型的表现力。
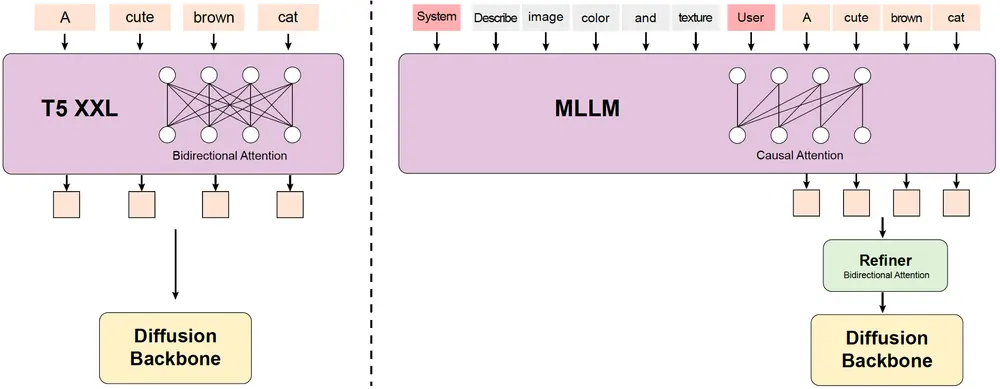
MLLM 文本编码器
不同于传统的CLIP或T5-XXL,HunyuanVideo使用了预训练的多模态大型语言模型(MLLM)作为文本编码器。MLLM具备更强的图像-文本对齐能力和更细致的图像描述功能,同时还能作为零样本学习者遵循系统指令,为视频生成提供更加精准的文本指导。
3D VAE 和时空压缩
借助于CausalConv3D,HunyuanVideo训练了一款3D VAE,能够高效地将像素空间的视频和图像压缩至紧凑的潜在空间。这种时空压缩方法显著减少了扩散Transformer模型所需的令牌数量,允许模型在原始分辨率和帧率下进行训练,确保输出视频的质量。

提示重写机制
考虑到用户提供的提示可能存在语言风格和长度上的差异,HunyuanVideo还引入了提示重写功能。通过微调Hunyuan-Large模型,可以将原始提示调整为更适合模型理解的形式,进而提高视频生成的效果。此外,提供了普通模式和大师模式两种不同的提示重写选项,分别适用于不同场景下的需求。
工作原理
HunyuanVideo的工作流程包括以下几个关键步骤:
- 数据预处理:包括视频和图像的筛选、重标注和结构化描述。
- 模型架构设计:采用3D变分自编码器(VAE)压缩视频和图像,以及基于Transformer的统一图像和视频生成架构。
- 模型预训练:通过多个阶段的预训练,从低分辨率图像开始,逐步过渡到高分辨率视频。
- 文本提示重写:使用Hunyuan-Large模型将用户提示转换为模型更偏好的格式。
- 高性能模型微调:通过精选数据集进行微调,提高生成视频的质量和动态控制能力。
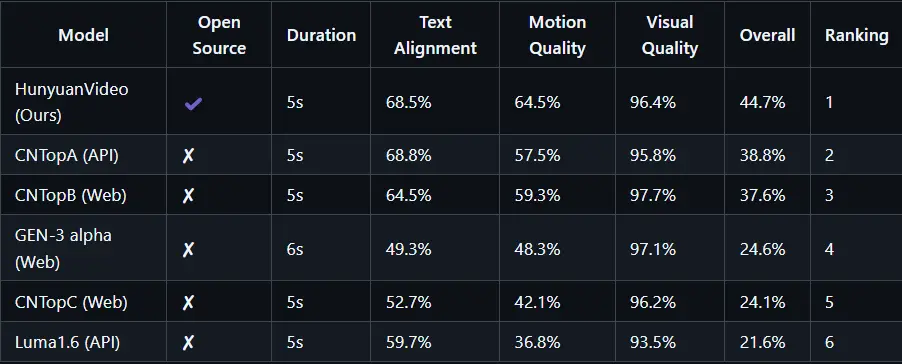
性能比较
在与五个强大的闭源视频生成模型的对比测试中,HunyuanVideo凭借其出色的文本对齐、运动质量和视觉质量脱颖而出。此次评测共收集了1,533个文本提示,并由超过60名专业人士组成的评审团进行了严格评估。结果显示,HunyuanVideo无论是在整体性能还是特定指标上均处于领先地位。
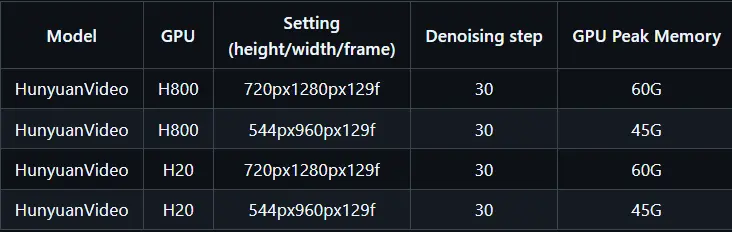
技术要求
要运行HunyuanVideo模型并生成视频,您需要一台配备有支持CUDA的英伟达GPU的计算机。具体来说:
- 最低配置:720p(1280x720)@129帧 视频生成需60GB显存;544x960 @129帧 视频生成需45GB 显存
- 推荐配置:建议使用至少80GB GPU内存的设备以获得更佳的生成效果。
- 测试操作系统:Linux
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











