利物浦大学、蚂蚁集团、西交利物浦大学、昆山杜克大学和理光软件研究中心推出新型框架 KDTalker,用于从单张图像和音频生成自然且动态的“说话肖像”(talking portrait)视频。该框架结合了无监督的隐式 3D 关键点和时空扩散模型,显著提升了生成视频的唇部同步精度、头部姿态多样性和生成效率。
- GitHub:https://github.com/chaolongy/KDTalker
- 模型:https://huggingface.co/ChaolongYang/KDTalker
- Demo:https://kdtalker.com
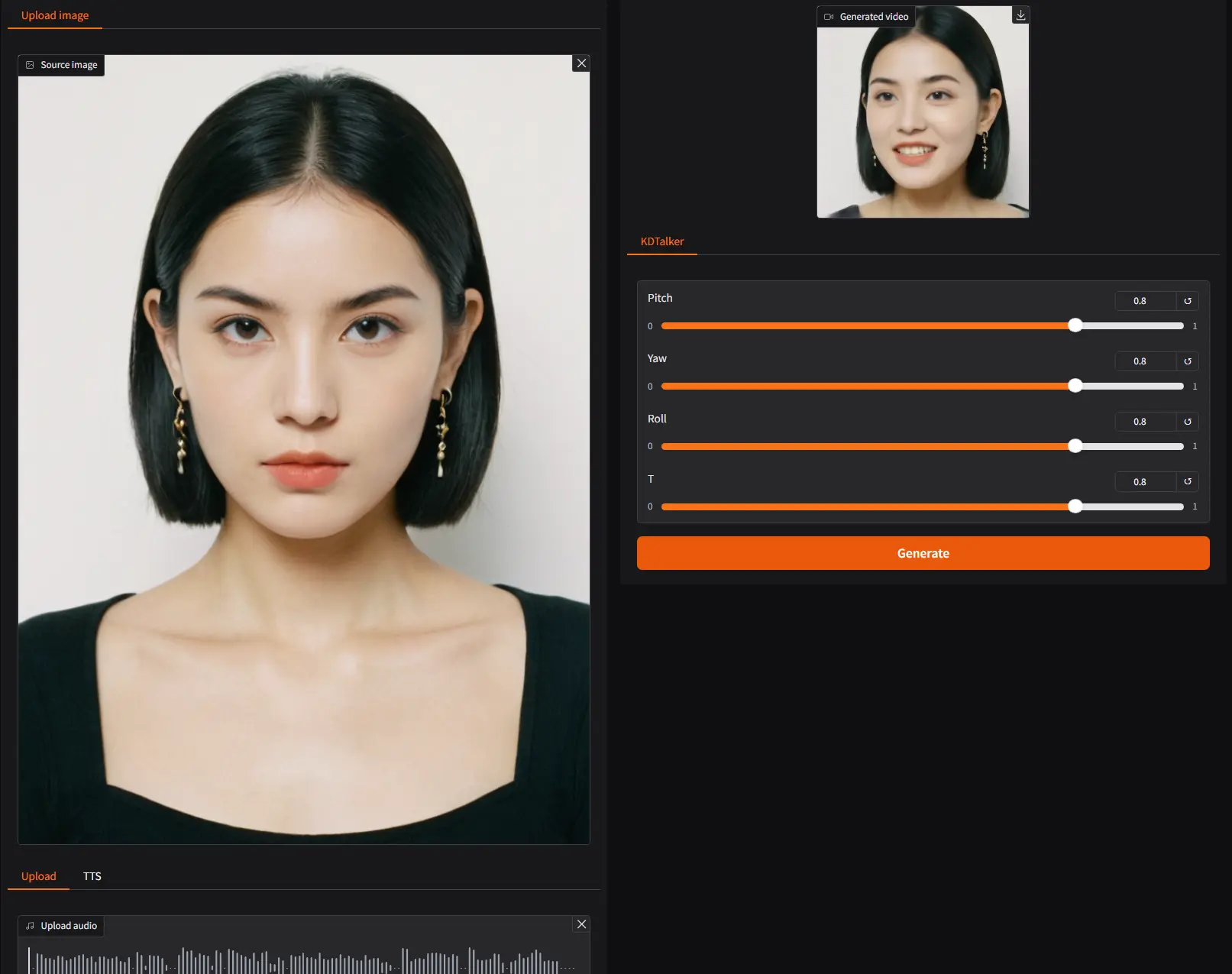
给定一张人物的单张图像和一段音频,KDTalker 可以生成该人物的视频,人物在视频中根据音频内容自然地动嘴、眨眼和改变头部姿态,生成的视频在视觉上高度逼真且与音频完美同步。不过,实测效果并不太好。
主要功能
- 唇部同步:通过精确的唇部运动与音频同步,生成自然的说话效果。
- 头部姿态多样性:生成丰富多样的头部姿态,使动画更加生动自然。
- 高效生成:在保持高质量的同时,实现快速的实时生成,适用于实时应用场景。
- 身份保留:保持输入图像中人物的身份特征,避免生成的视频中人物特征失真。
主要特点
- 无监督隐式 3D 关键点:与传统的基于固定 3D 模型关键点的方法不同,KDTalker 使用无监督隐式 3D 关键点,能够动态适应不同的面部信息密度,捕捉更细微的面部表情和头部姿态。
- 时空注意力机制:通过时空注意力机制,模型能够捕捉音频与关键点之间的长期依赖关系,确保生成的动画不仅自然流畅,而且与音频精确同步。
- 扩散模型:结合扩散模型的强大生成能力,KDTalker 在保持高效计算性能的同时,生成高质量、多样化的头部姿态和面部表情。
- 显式头部姿态控制:与基于隐式运动建模的方法(如 VASA-1)相比,KDTalker 提供了对头部姿态的显式控制,使姿态调整更加灵活。
工作原理
- 图像和音频处理:
- 使用预训练的 LivePortrait 框架从参考图像中提取运动信息,包括关键点和头部姿态参数。
- 使用 Wav2Lip 的音频编码器从音频中提取特征,作为扩散模型的条件输入。
- 参考引导的先验模块:
- 将参考图像中的关键点和运动信息与噪声序列结合,为扩散模型提供结构化的输入,确保生成的运动与原始面部结构一致。
- 基于关键点的时空扩散模型:
- 利用扩散模型预测表情变形关键点和变换参数,通过逆向扩散过程逐步去噪,生成与音频同步的面部运动关键点。
- 面部渲染:
- 使用 LivePortrait 的变形和解码模块,将预测的关键点和变换参数应用于参考图像,生成最终的视频帧。
应用场景
- 虚拟现实和增强现实:为虚拟角色生成自然的说话动画,提升沉浸感。
- 数字人创建:为数字人生成逼真的说话视频,用于客户服务、虚拟助手等场景。
- 影视制作:快速生成高质量的说话头像视频,减少动画制作的时间和成本。
- 在线教育:为在线课程生成生动的教学视频,提高学生的学习兴趣和参与度。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











