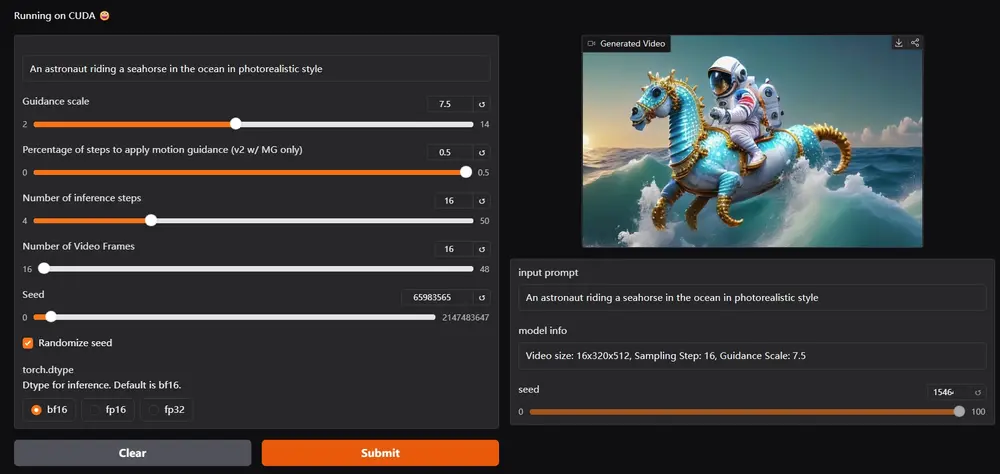
腾讯和香港中文大学的研究人员推出一项基于扩散模型(diffusion models)的创新技术TrajectoryCrafter ,重新定义单目视频中的相机轨迹,能够从单目视频中推断并生成全新的视角。该方法的核心目标是让用户能够自由地改变视频中相机的运动轨迹,同时保持视频内容的连贯性和一致性。
- 项目主页:https://trajectorycrafter.github.io
- GitHub:https://github.com/TrajectoryCrafter/TrajectoryCrafter
- Demo:https://huggingface.co/spaces/Doubiiu/TrajectoryCrafter
例如,你有一段单目视频,内容是一个人在房间里走动。传统的视频只能按照原始拍摄的视角展示内容,但使用 TrajectoryCrafter,你可以重新定义相机的运动轨迹,比如让相机围绕这个人旋转、拉近或拉远,甚至从不同的角度观察房间内的场景,生成全新的视频内容,同时保持场景的真实感和连贯性。
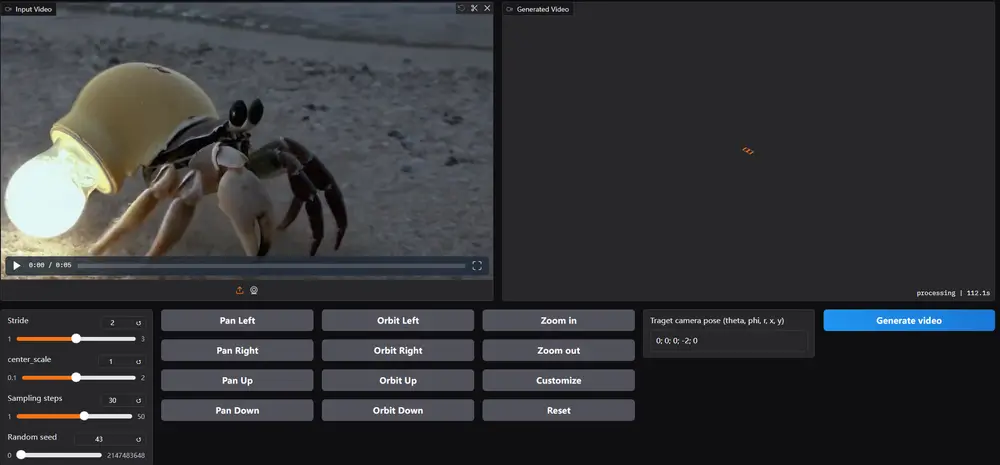
主要功能
- 相机轨迹重定向:用户可以自由定义视频中相机的运动轨迹,生成全新的视角。
- 高保真视频生成:生成的视频在视觉上与原始视频保持一致,同时具有高分辨率和高质量。
- 4D 内容一致性:生成的视频不仅在空间上连贯,还在时间上保持一致性,避免出现闪烁或内容漂移等问题。
- 适用于单目视频:输入只需普通的单目视频,无需多视角视频或复杂的深度信息。

主要特点
- 精确的轨迹控制:通过分离确定性视图变换和随机内容生成,能够精确地控制相机的运动轨迹。
- 双流条件扩散模型:结合点云渲染和原始视频作为条件,确保生成视频的精确视图变换和内容连贯性。
- 混合数据训练策略:利用大规模单目视频和静态多视角数据进行训练,显著提升了模型在不同场景下的泛化能力。
- 无需多视角数据:避免了对稀有多视角视频数据的依赖,降低了数据获取成本。
工作原理
- 点云渲染:首先,将输入的单目视频通过深度估计提升为动态点云,然后根据用户指定的相机轨迹渲染出新的视图。这些视图虽然能够提供正确的几何变换,但可能存在空洞和纹理问题。
- 双流条件扩散模型:将点云渲染和原始视频作为条件输入到扩散模型中。模型分为两部分:
- 点云分支:利用预训练的扩散层进行精确的视图变换。
- 参考视频分支:通过引入参考条件扩散模块(Ref-DiT),将原始视频的细节信息整合到生成过程中,解决点云渲染中的空洞和纹理问题。
- 混合数据训练:通过双重新投影策略从单目视频中生成训练数据,并结合静态多视角数据进行训练,提升模型的泛化能力。
应用场景
- 视频编辑与特效制作:在影视制作中,可以重新定义镜头的运动轨迹,为视频添加创意特效。
- 虚拟现实(VR)和增强现实(AR):为用户提供自由的视角交互,增强沉浸感。
- 视频会议与远程协作:在视频会议中,可以根据需要调整相机视角,提升用户体验。
- 自动驾驶与仿真:用于生成不同视角的驾驶场景,用于自动驾驶算法的训练和测试。
- 内容创作与社交媒体:创作者可以为视频添加新的视角,增加内容的趣味性和吸引力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











