
视频生成技术一直是AI领域的热门研究方向之一。然而,现有的视频生成模型在处理长视频时常常面临两大挑战:一是“遗忘”问题,模型难以记住早期的视频内容,导致生成的视频缺乏连贯性;二是“漂移”问题,随着视频长度的增加,误差不断累积,最终导致生成的视频质量下降。
- 项目主页:https://lllyasviel.github.io/frame_pack_gitpage
- GitHub:https://github.com/lllyasviel/FramePack
- ComfyUI插件:https://github.com/kijai/ComfyUI-FramePackWrapper
- ComfyUI插件:https://github.com/CY-CHENYUE/ComfyUI-FramePack-HY
斯坦福大学的研究人员推出了一种名为 FramePack 的神经网络结构,专门针对这些问题,高效地解决了视频生成中的“遗忘”和“漂移”难题,同时保持计算效率不变。值得注意的是,参与这项研究的人员中就有 ControlNet 的作者 Lvmin Zhang,此项研究基于腾讯开源的混元视频生成模型。
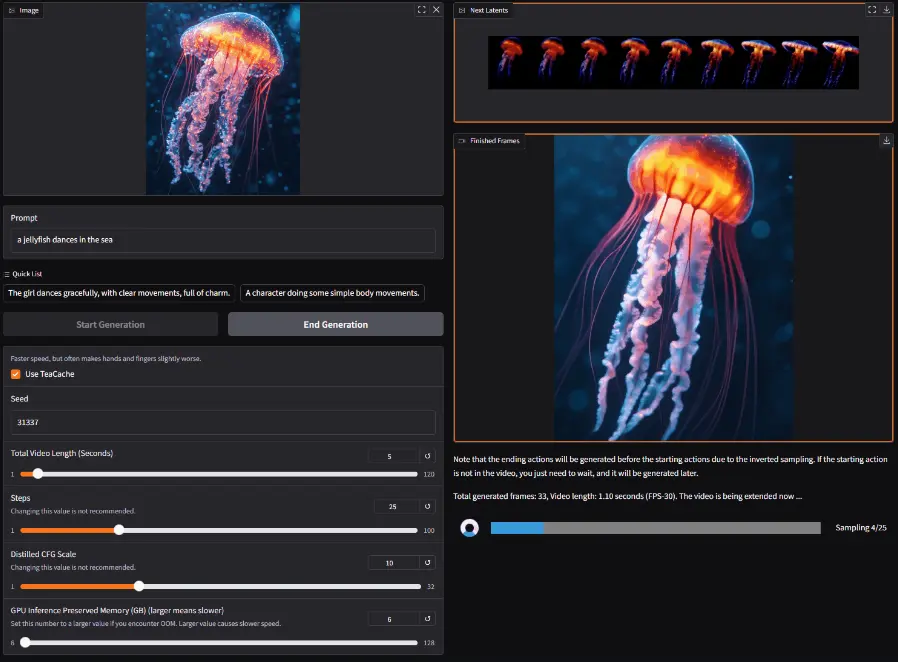
FramePack 的核心优势
FramePack 作为一种下一帧(或下一帧段)预测神经网络结构,其核心优势在于能够将输入上下文压缩至固定长度,使生成工作量不受视频长度影响。这意味着即使在笔记本 GPU 上,通过 13B 模型也能处理大量帧,支持更大的批次训练,类似于图像扩散训练的批次大小。这种高效的计算方式让视频扩散变得轻松,仿佛在进行图像扩散一般。
硬件要求
使用 FramePack 时,需要满足以下硬件要求:
- 支持 fp16 和 bf16 的英伟达RTX 30XX、40XX、50XX 系列 GPU。GTX 10XX/20XX 未经过测试
- 操作系统为 Linux 或 Windows
- 至少需要 6GB GPU 显存
以 13B 模型生成 1 分钟视频(60 秒,30fps,1800 帧)为例,最小 GPU 显存需求仅为 6GB,笔记本 GPU 也可胜任。在速度方面,RTX 4090 台式机的生成速度为 2.5 秒/帧(未优化)或 1.5 秒/帧(teacache),3070ti 或 3060 笔记本则慢 4 到 8 倍。不过,由于是下一帧(段)预测,用户可以在整个视频生成完成前,直接看到生成的帧,获得大量视觉反馈。
FramePack 的主要功能
解决遗忘问题
FramePack 通过压缩输入帧,在不增加计算瓶颈的情况下处理大量帧,从而更好地记住早期内容。这对于生成连贯的长视频至关重要。
减少漂移问题
FramePack 提出了一种反漂移采样方法,通过反向时间顺序生成帧或在生成过程中建立早期终点,避免误差累积。这使得生成的视频在长视频场景下也能保持高质量。
提升视频生成质量
通过改进的扩散调度器,FramePack 能够生成更高质量的视频,尤其是在处理长视频时。这不仅提升了视频的视觉效果,还增强了视频的整体连贯性。
兼容现有模型
FramePack 可以对现有的视频扩散模型(如 HunyuanVideo、Wan 等)进行微调,提升其性能。这意味着用户可以轻松地将 FramePack 集成到现有的工作流程中,而无需从头开始训练模型。
FramePack 的主要特点
固定上下文长度
无论视频多长,FramePack 都能将输入帧压缩到固定的上下文长度,避免上下文长度爆炸。这一特性使得 FramePack 在处理长视频时依然能够保持高效的计算性能。
高效计算
通过调整 Transformer 的 patchify 核大小,FramePack 在处理大量帧时保持了与图像扩散模型相当的计算效率。这使得 FramePack 适用于各种硬件环境,包括笔记本 GPU。
灵活的采样方法
FramePack 支持多种采样策略,包括反向时间顺序采样和双向上下文采样,有效减少漂移。这些采样方法可以根据具体任务进行优化,以达到最佳的生成效果。
可扩展性
FramePack 支持多种帧压缩变体,可以根据具体任务优化压缩策略。这使得 FramePack 在不同的应用场景中都能发挥出最佳性能。
FramePack 的工作原理
帧压缩
FramePack 根据帧的重要性进行压缩,越接近预测目标的帧越重要,压缩率越低。采用几何级数压缩策略,通过调整 Transformer 的 patchify 核大小实现不同压缩率。例如,对于 480p 分辨率的帧,压缩率可以是 2 的幂(如 2、4、8 等)。总上下文长度通过几何级数收敛到一个固定值,避免了上下文长度随输入帧数增加而爆炸的问题。
反漂移采样方法
- 反向时间顺序采样:从最后一帧开始生成,逐步向第一帧逼近,每一步都尝试接近已知的高质量帧(如输入帧)。
- 双向上下文采样:在第一次迭代中同时生成视频的起始部分和结束部分,后续迭代填充中间内容。这种方法通过提供未来帧的信息来避免漂移。
RoPE 对齐
在不同压缩率下编码输入时,需要对 RoPE(旋转位置嵌入)进行对齐。通过平均池化下采样 RoPE 相位,使其与压缩核匹配。这确保了在不同压缩率下,模型能够正确地处理帧的位置信息。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











