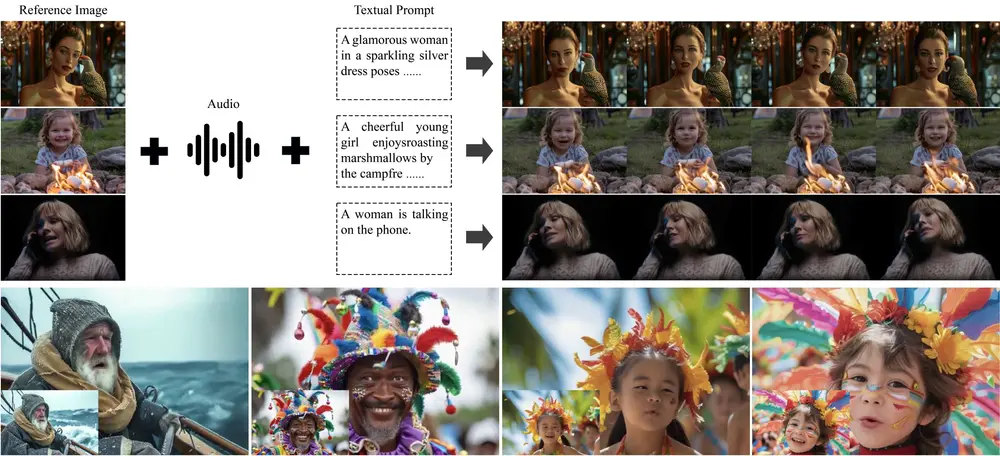
阿里达摩院、浙江大学、湖畔实验室的研究人员推出多模态扩散架构MoDA,用于生成具有任意身份和语音音频的“会说话的头像”(talking head)。
- 项目主页:https://lixinyyang.github.io/MoDA.github.io
- GitHub:https://github.com/lixinyyang/MoDA
- 模型:https://huggingface.co/lixinyizju/moda
MoDA从单张图像、音频和其他模态信息生成逼真的、会说话的人物肖像视频。例如,给定一张人物照片和一段语音音频,MoDA可以生成该人物根据音频内容“说话”的视频,不仅嘴唇动作与音频同步,还能表现出自然的面部表情和头部动作。

主要功能
- 高保真肖像动画生成:从单张图像和音频生成高质量的会说话的头像视频。
- 多模态融合:整合音频、身份、情感等多种模态信息,生成自然的面部表情和头部动作。
- 实时生成:支持实时视频生成,适用于实时交互场景。
- 细粒度表情控制:能够对生成的面部表情进行精细控制,如愤怒、快乐、悲伤等情绪的表达。
- 长视频生成:支持生成长时间的视频,而不仅仅是几秒钟的片段。
主要特点
- 多模态扩散架构:通过显式建模运动、音频和辅助条件之间的交互,增强整体面部表情和头部动态。
- 粗到细的融合策略:逐步整合不同条件,确保有效的特征融合,提高生成视频的多样性和自然度。
- 实时性与效率:通过优化的推理过程和低延迟运动生成,实现高效的实时视频生成。
- 适应性强:能够适应不同的身份、情感和音频类型,生成多样化的视频内容。
工作原理
- 多模态输入:输入包括一张参考图像(人物肖像)、音频片段以及其他可选的控制信号(如情感标签)。
- 特征提取:使用wav2vec编码器提取音频特征,使用视觉情感分类器提取情感特征,并从参考图像中提取身份特征。
- 运动生成:通过多模态扩散Transformer(MMDiT)和粗到细的融合策略,将音频特征、情感特征和身份特征与运动特征进行融合,生成运动序列。
- 视频合成:将生成的运动序列输入到预训练的面部渲染网络中,合成最终的视频帧。
- 实时推理:通过优化的推理过程,将音频特征与视频帧率对齐,并分块处理音频,实现低延迟的实时视频生成。
测试结果
- 定量评估:在HDTF和CelebV-HQ数据集上,MoDA在多个评估指标上优于现有方法,如FID(Fréchet Inception Distance)和FVD(Fréchet Video Distance)得分最低,表明生成视频的质量和自然度更高。
- 定性评估:通过视觉比较,MoDA生成的视频在面部表情、头部动作和嘴唇同步方面表现出色,优于其他方法。
- 实时性:MoDA的实时因子(RTF)小于1,表明其能够实现实时视频生成,适合实时交互场景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











