
在虚拟人、影视后期、跨语言内容本地化等场景中,理想的配音技术不仅要实现精准的唇部同步,还需让头部运动、面部表情、身体姿态自然地跟随语音节奏变化,同时保持人物身份一致性。
- 项目主页:https://meigen-ai.github.io/InfiniteTalk
- GitHub:https://github.com/bmwas/InfiniteTalk
- 模型:https://huggingface.co/MeiGen-AI/InfiniteTalk
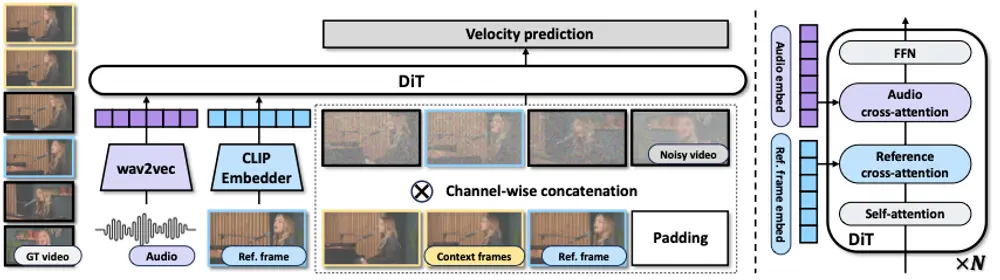
InfiniteTalk是一种新颖的稀疏帧视频配音框架,它不仅实现了高精度唇形匹配,更进一步统一建模了语音与全身动态的关联,支持从稀疏帧视频或单张图像生成无限长度的连贯说话视频。
| 模型 | 地址 | Notes |
|---|---|---|
| Wan2.1-I2V-14B-480P | Huggingface | 基础模型 |
| chinese-wav2vec2-base | Huggingface | 音频编码器 |
| MeiGen-InfiniteTalk | Huggingface | 音频条件模型 |
核心能力:超越“对口型”的全动态建模
传统音频驱动视频方法通常聚焦于唇部区域,导致生成结果出现“头不动、脸僵硬、手乱飘”等问题。InfiniteTalk 的突破在于:
✅ 多层级同步控制
- 唇部:实现帧级语音-唇动对齐
- 头部:自然摆动与点头节奏匹配语调起伏
- 表情:根据情绪语义调整微笑、皱眉等微表情
- 身体姿势:配合语义重音生成轻微手势与上身动作
✅ 稀疏帧输入支持
无需密集关键帧,仅需少量视频帧即可重建完整动态序列,降低数据采集成本。
✅ 无限时长生成
理论上支持任意长度输出,适用于长篇演讲、访谈、直播回放等场景。
✅ 身份保持稳定
在整个生成过程中,人物外貌、肤色、发型等特征高度一致,减少漂移现象。
两种主流生成模式
1. 视频到视频(V2V):基于原始视频的动态重定向
输入:一段包含说话人的视频片段(任意时长)
输出:保留原始风格的新视频,语音内容由新音频驱动
- 模型会模仿原视频的镜头运动(如缓慢推拉、轻微晃动)
- 长视频中镜头轨迹可能略有偏差,建议使用 SDEdit 增强一致性(适用于短片段)
- 当前计划优化长视频的摄像机运动控制能力
2. 图像到视频(I2V):从单张照片生成说话视频
输入:一张人物正面照 + 音频
输出:最长 1 分钟的自然说话视频
- 超过 1 分钟后可能出现颜色偏移或身份弱化
- 提示技巧:可先将图像转为带平移/缩放的短视频作为输入,提升长视频稳定性
性能表现:更准、更稳、更快
| 指标 | 表现 |
|---|---|
| 唇部同步精度 | 显著优于 MultiTalk,尤其在复杂语速和口音下保持稳定 |
| 身体稳定性 | 减少手部扭曲与身体抖动,动作更自然 |
| 推理速度 | 支持快速生成,适合批量处理 |
| 分辨率兼容性 | 支持 480P 与 720P,兼顾质量与效率 |
特别在唇部同步方面,通过调节 音频 CFG(Classifier-Free Guidance)参数(推荐值 3–5),可进一步提升同步质量。值越高,语音与唇动对齐越精确,但过高可能导致表情僵硬,需权衡使用。
使用建议与注意事项
🔊 音频 CFG 设置
- 推荐范围:3–5
- 更高值 → 更精准唇动,但可能牺牲自然度
- 可根据内容节奏动态调整(如快节奏演讲用 4.5,慢速朗读用 3.5)
🎨 关于 FusionX LoRA
- 使用后可提升生成速度与画面质量
- 但超过 60 秒视频可能出现:
- 颜色逐渐偏移(如肤色变暗)
- 身份特征弱化(五官模糊)
- 建议用于短片段;长视频建议关闭或后期调色校正
🎥 V2V 模式优化技巧
- 若需高精度镜头还原,可启用 SDEdit 进行迭代增强
- 注意:SDEdit 可能引入轻微色彩失真,适合 10–30 秒内的片段
🖼️ I2V 超长生成小技巧
想生成超过 1 分钟的高质量视频?试试这个方法:
- 将输入图像制作成一个带缓慢平移或缩放效果的 5–10 秒短视频;
- 以此视频作为 V2V 输入;
- 利用 InfiniteTalk 的无限生成能力扩展至更长时间。
此方式能显著提升身份保持与色彩稳定性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











