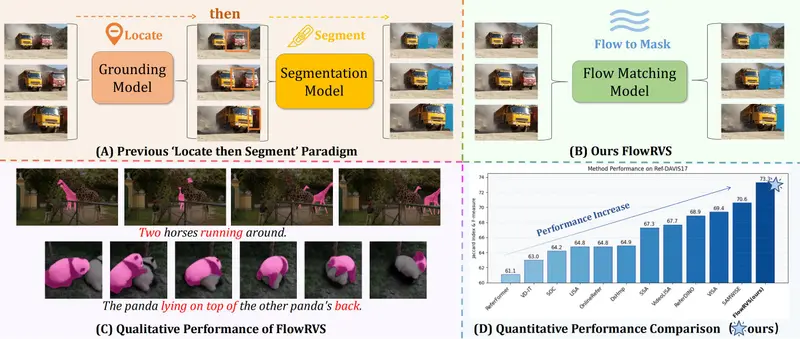
想象这样一个场景:视频里有两只狗在玩耍,你对 AI 说:“帮我追踪那只正在跳的白色狗。”或者在一群人中,你指定:“锁定那个先骑自行车进画面的男人。”
这种用自然语言描述来指定视频中特定对象,并让 AI 持续追踪分割的任务,被称为指代视频对象分割(RVOS)。传统方法往往在处理复杂动作、时序关系或遮挡时“跟丢”目标。
近日,来自加州大学圣地亚哥分校、香港科技大学、浙江大学等机构的研究团队提出了一种名为 FlowRVS 的新方法。它摒弃了传统的级联架构,创造性地将 RVOS 任务重新定义为“视频向掩码流动”的生成式过程,在多个权威基准测试上刷新了最先进结果(SOTA)。
痛点:传统“两步走”为何失效?
现有的 RVOS 方法普遍采用 “先定位(检测框/点),再分割” 的级联范式。这种看似合理的流程存在致命缺陷:
- 信息瓶颈:第一步将丰富的语言描述(如“正在转圈的白色兔子”)压缩成简单的几何坐标(一个框),丢弃了动作、颜色、相对位置等关键语义信息。
- 时序断裂:分割阶段往往与最初的语言理解脱节。一旦目标被遮挡或发生剧烈形变,模型容易因缺乏语义引导而“跟丢”。
- 复杂语境无力:面对涉及时序(“先出现的那只”)、比较(“较轻的那头”)或复杂动作的描述,传统判别式模型常常束手无策。
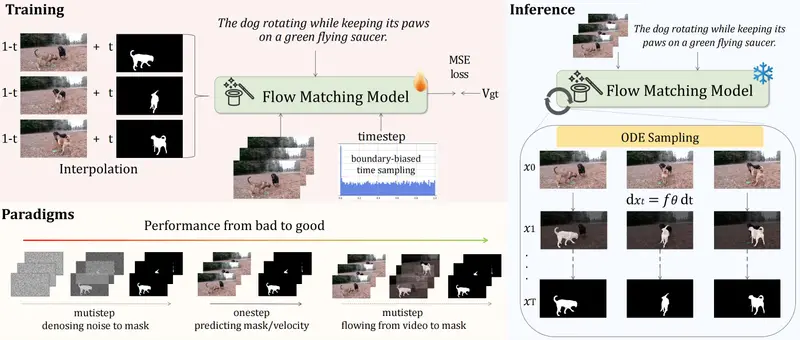
核心突破:从“判别预测”到“生成式变形”
FlowRVS 的核心思想是一次范式转移:不再直接“猜”出分割结果,而是让视频像素在语言的引导下,逐渐“流动”并“凝结”成目标的分割掩码。
1. 借鉴视频生成模型的强大能力
研究团队巧妙迁移了先进的**文本到视频生成模型(如 Wan 2.1)**的能力。
- 原生优势:这些模型天生理解文字与像素的对应关系,深知物体在时间维度上的运动规律。
- 逆向运用:FlowRVS 反其道而行之,不是从文字生成新视频,而是让现有视频流向文字描述的目标形态。
2. 端到端统一架构
FlowRVS 将“语言理解”与“视频分割”融合为一个连续的、由文本调节的流场。
- 无中间损耗:语言指令全程参与每一个变形步骤,避免了信息在模块间传递时的丢失。
- 单阶段简洁:摒弃了复杂的检测头、分割头级联,用一个统一模型完成所有任务,减少了错误累积。
关键技术:如何确保“变形”不跑偏?
为了让这个“视频变形魔术师”精准工作,FlowRVS 引入了三项原理性技术:
- 边界偏置采样(重视第一步)
- 原理:研究发现,“流动”过程的第一步方向至关重要,如同射箭初期的瞄准。
- 策略:在训练时强化初始阶段的学习权重,确保模型能根据复杂语言描述做出准确的初始判断,防止“一步错,步步错”。
- 直接视频注入(永不忘记原视频)
- 原理:在 iterative 变形过程中,模型容易逐渐偏离原始目标。
- 策略:每一步都将原始视频特征直接注入当前状态。就像追踪时不断回头参考原片,防止因记忆模糊导致的身份混淆或漂移。
- 起点增强训练(鲁棒性提升)
- 原理:现实世界的视频起始帧千差万别。
- 策略:训练时对起点施加随机微小扰动,强迫模型学会在各种不利起始条件下都能稳定启动,提升泛化能力。
实测表现:刷新纪录,泛化强劲
FlowRVS 在多个高难度基准测试中展现了统治力:
| 数据集 | 挑战点 | FlowRVS 表现 | 对比优势 |
|---|---|---|---|
| MeViS | 复杂运动理解、长视频 | J&F 51.1 | 超越前 SOTA (SAMWISE) 1.6 分 |
| Ref-DAVIS17 | 零样本泛化 | J&F 73.3 | 仅在 Ref-Youtube-VOS 训练,直接迁移超越前 SOTA 2.7 分 |
| 通用对比 | 架构效率 | 显著领先 | 比基于大视觉语言模型的 VISA 高出 7.0 分 |
- 零样本泛化:模型在一个数据集训练后,无需微调即可在全新场景(如从 YouTube 视频迁移到 DAVIS 数据集)保持高精度,证明其学到了通用的视频理解逻辑。
- 复杂语义理解:可视化结果显示,FlowRVS 能精准区分“两只打架牦牛中颜色较浅的那只”,并在严重遮挡下保持追踪连续性。
意义与展望
FlowRVS 的成功证明了生成式模型在理解任务中的巨大潜力。它打破了“生成”与“理解”的界限,展示了预训练视频大模型如何通过巧妙的范式转换,赋能下游密集预测任务。
- 技术启示:端到端的“流动”范式可能成为未来视频理解的新标准,替代繁琐的级联 Pipeline。
- 应用前景:从智能监控(“追踪那个穿红衣服逃跑的人”)到自动驾驶(“关注那辆正在变道的蓝色卡车”),再到视频编辑,FlowRVS 让 AI 真正听懂人话、看懂动态世界。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...