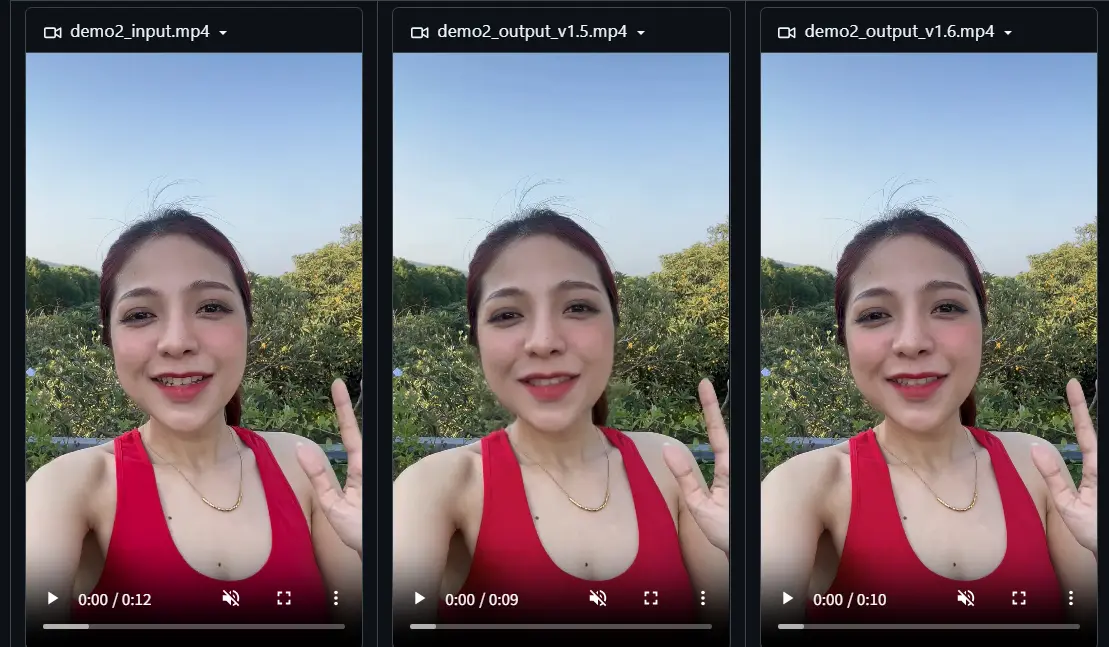
字节跳动发布了其对口型视频生成模型 LatentSync 的新版本 1.6,重点解决了此前版本中生成牙齿和嘴唇区域模糊的问题。
该更新主要通过使用更高分辨率的训练数据实现改进——与 1.5 版本相比,LatentSync 1.6 在 512 × 512 分辨率的视频上进行训练,从而显著提升了局部细节的清晰度。
无架构改动,仅升级训练数据
官方说明指出,此次更新并未对模型结构或训练策略做出任何调整,唯一的变化是将训练数据集从低分辨率升级至 512 x 512 分辨率视频。
这意味着:
- 模型整体结构保持稳定
- 训练流程无需重构
- 代码兼容 LatentSync 1.5 和 1.6
用户只需加载对应的检查点(checkpoint),并在 U-Net 配置文件中修改分辨率参数,即可在两个版本之间自由切换。
为何选择 512x512?
在视频生成任务中,人脸特别是嘴唇和牙齿等细节区域,往往容易因分辨率不足而出现模糊。这些区域对于视觉真实感至关重要,尤其在语音驱动、表情同步等应用中。
通过提升训练数据的清晰度,LatentSync 1.6 能更准确地捕捉面部动态细节,从而提升生成质量,增强用户体验。
相关
端到端唇音同步框架LatentSync:可以分析新的音频信号,并生成与音频同步的口型
ComfyUI-LatentSyncWrapper:基于字节跳动唇音同步框架LatentSync的非官方ComfyUI节点
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











