在文本到视频(T2V)生成领域,一个长期存在的难题是:如何让生成的视频中的人物始终“长成你想要的样子”?
尽管现有模型能生成流畅、高质量的视频,但在身份一致性(identity-preserving)方面仍表现不佳——人物面容在帧间漂移、与参考图像偏离严重,限制了其在个性化内容创作、虚拟人驱动等场景的应用。
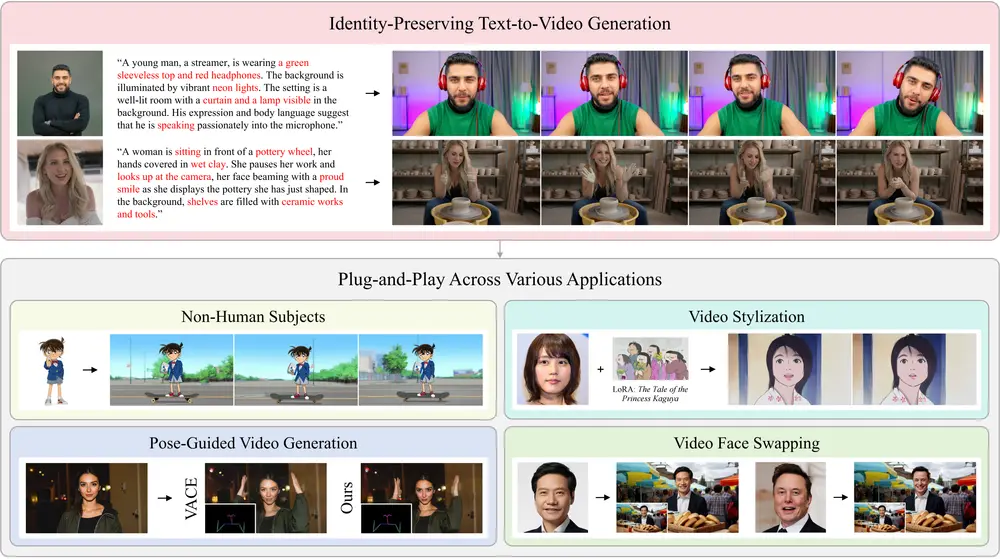
为此,腾讯微信视觉项目组推出了 Stand-In,一个轻量级、即插即用的身份保持视频生成框架。该方法仅需微调基础模型 1% 的参数,即可在面部相似度和视觉自然度上达到当前最优(SOTA)水平,甚至超越全参数微调的方案。
- 项目主页:https://www.stand-in.tech
- GitHub:https://github.com/WeChatCV/Stand-In
- 模型:https://huggingface.co/BowenXue/Stand-In
- Demo:https://huggingface.co/spaces/fffiloni/Stand-In
更重要的是,Stand-In 可无缝集成至主流 T2V 模型,并支持主体驱动、姿态控制、视频风格化、面部交换等多种下游任务。
核心目标:用最小代价实现最强身份控制
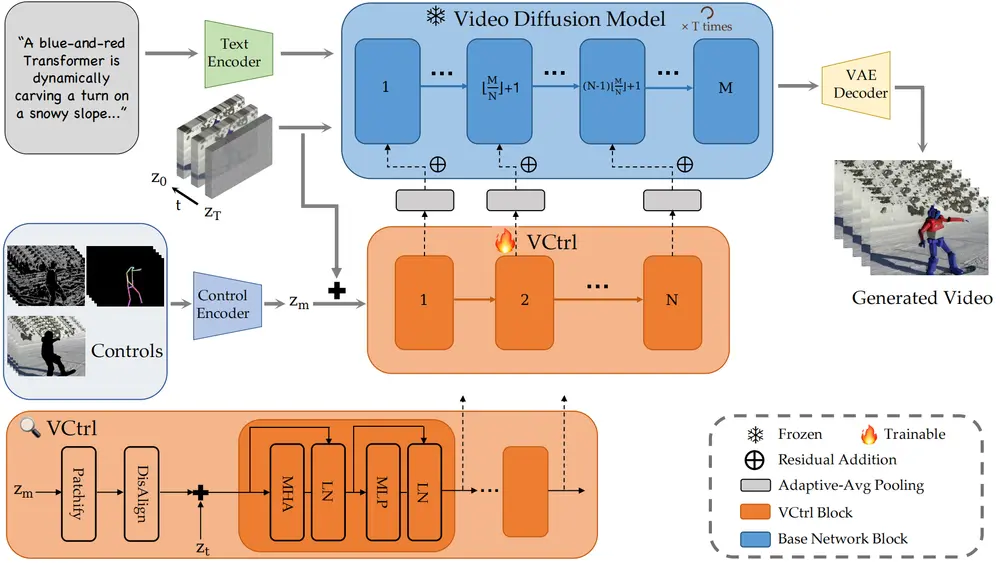
Stand-In 的设计哲学是“少即是多”。它不追求对整个视频生成模型进行重训,而是通过两个核心机制,在不破坏原有生成质量的前提下,精准注入身份信息:
- 条件图像分支(Conditional Image Branch)
- 受限自注意力机制(Restricted Self-Attention)
这两个模块共同作用,使模型在去噪过程中始终“记得”参考图像的面部特征,同时保持时间连贯性与动作自然性。
技术原理:如何实现高效身份注入?
1. 条件图像分支:将参考图像编码进潜在空间
Stand-In 引入一个独立的图像编码分支,利用预训练 VAE 将用户提供的参考图像映射到与视频潜变量相同的表示空间。这使得模型无需额外学习图像-视频对齐,即可提取丰富的面部细节。
该分支仅在推理时作为条件输入,训练时也仅更新少量适配参数。
2. 受限自注意力机制:精准控制信息流动
传统的交叉注意力容易导致身份信息过度干扰动作生成。为此,Stand-In 设计了受限自注意力机制,仅允许视频特征中的“主体区域”从参考图像中提取身份信息,而非全局融合。
这避免了背景混淆或动作失真,确保身份控制既精准又克制。
3. 条件位置映射:空间与时间的双重对齐
为了防止参考图像与视频帧在空间上错位,Stand-In 引入 3D 旋转位置嵌入(3D RoPE),为参考图像分配一个独立且固定的坐标空间。
这一设计使得参考图像在所有时间步上保持一致,同时与视频序列在空间结构上正确对齐。
4. KV 缓存:提升推理效率
由于参考图像的时间步固定为 0,其 Key 和 Value 矩阵在整个扩散过程中保持不变。因此,Stand-In 在推理时可缓存这些矩阵,显著减少计算开销,提升生成速度。
主要特点
| 特性 | 说明 |
|---|---|
| 轻量级 | 仅需训练约 153 万额外参数(占 Wan2.1-14B 的 1%),即可实现强大身份控制 |
| 高保真 | 在面部相似度与视觉自然度上均达到 SOTA,优于全参数微调方法 |
| 即插即用 | 支持 LoRA 等社区主流插件,可直接集成到现有 T2V 流程中 |
| 高度可扩展 | 兼容多种任务:主体驱动、姿态引导、视频风格化、换脸等 |
实验结果:全面领先
Stand-In 在多个公开基准和用户研究中表现优异:
定量评估(OpenS2V 基准)
| 指标 | Stand-In 结果 |
|---|---|
| 身份相似度 (ID Score) | 0.724(显著高于其他方法) |
| 视频自然度 (FVD ↓) | 3.922(越低越好) |
| 提示遵循 (CLIP-T ↑) | 20.594(越高越好) |
注:FVD(Fréchet Video Distance)衡量生成视频与真实视频的分布距离;CLIP-T 衡量文本-视频对齐程度。
用户研究(5 分制)
| 维度 | 平均评分 |
|---|---|
| 身份相似度 | 4.10 |
| 视频质量 | 4.08 |
两项指标均高于对比方法,表明用户对生成结果的高度认可。
应用场景
Stand-In 的灵活性使其适用于多种视频生成任务:
- 个性化视频生成:输入一张人像,生成符合描述的定制化视频
- 主体驱动视频合成:以参考图像为主体,驱动其完成指定动作
- 姿态控制生成:保持身份不变,按目标姿态生成动作序列
- 视频风格化与换脸:在保留身份的前提下,迁移风格或替换背景
开源进展(截至发布)
腾讯微信视觉团队已逐步开放相关资源,推动社区共建:
✅ 已发布:
- IP2V 推理脚本(兼容社区 LoRA)
- 与 Wan2.1-14B-T2V 兼容的模型权重:
Stand-In_Wan2.1-T2V-14B_153M_v1.0
🔜 计划开源:
- 与 Wan2.2-T2V-A14B 兼容的模型权重
- 训练数据集与预处理脚本
- 完整训练代码
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...