上海人工智能实验室和蔚蓝海岸大学的研究人员推出一种新颖的可解释肖像动画器LIA-X,旨在将驱动视频中的面部动态转移到源肖像上,并实现精细控制。
- 项目主页:https://wyhsirius.github.io/LIA-X-project
- 模型:https://huggingface.co/YaohuiW/LIA-X
- Demo:https://huggingface.co/spaces/YaohuiW/LIA-X
LIA-X 是一个自编码器,将运动转移建模为潜在空间中运动代码的线性导航。关键在于,它引入了一个新颖的稀疏运动字典,使模型能够将面部动态解构为可解释的因子。与之前的“扭曲-渲染”方法不同,稀疏运动字典的可解释性使 LIA-X 支持高度可控的“编辑-扭曲-渲染”策略,能够精确操纵源肖像中的精细面部语义。这有助于缩小与驱动视频在姿势和表情方面的初始差异。
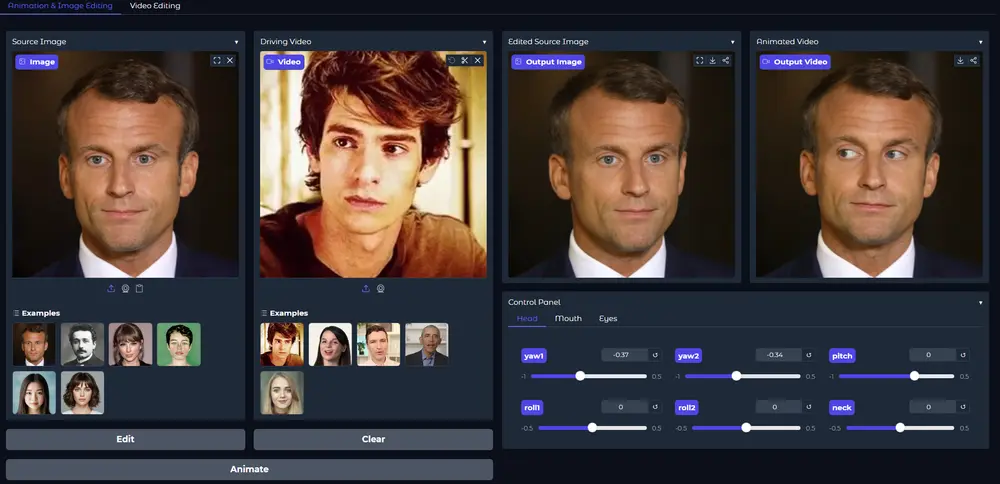
此外,研究团队展示了 LIA-X 的可扩展性,通过在大规模数据集上成功训练了一个约10亿参数的大型模型。实验结果表明,研究团队提出的方法在多个基准测试中的自我重现和跨重现任务上均优于之前的方法。此外,LIA-X 的可解释性和可控性支持实际应用,如精细的用户引导图像和视频编辑,以及3D感知的肖像视频操作。

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











