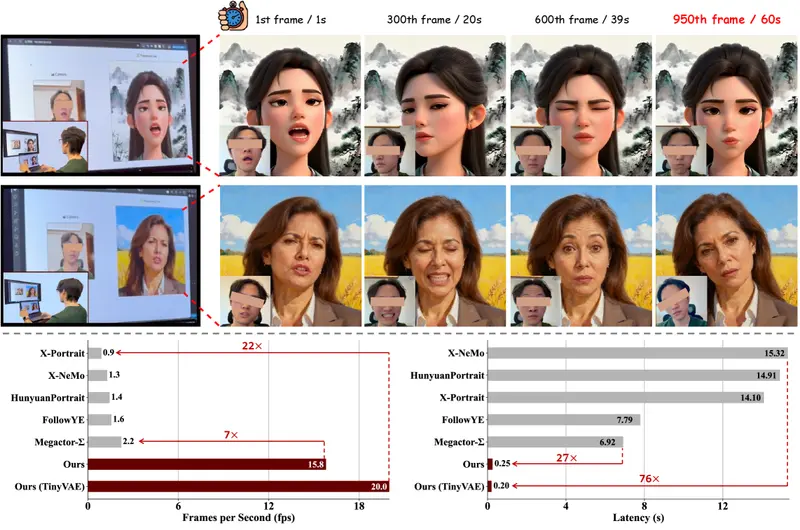
FlashPortrait:端到端生成无限长度肖像动画,6倍加速且身份一致在肖像动画(Portrait Animation)任务中,身份一致性与推理效率是两大长期瓶颈。现有扩散模型即便能生成逼真短片,也常在长序列中出现身份漂移、颜色偏移或动作断裂,且生成速度慢,难以用于实际...视频模型# FlashPortrait# 肖像动画3个月前0960
ComfyUI-PersonaLive:用一张图驱动实时肖像动画,支持 4 步高效生成由澳门大学、Dzine.ai 与大湾区大学提出的 PersonaLive,是目前少有的能在扩散模型框架下实现低延迟、高保真肖像动画的模型。开发者okdalto打造的 ComfyUI-PersonaLi...插件# ComfyUI-PersonaLive# 肖像动画3个月前0830
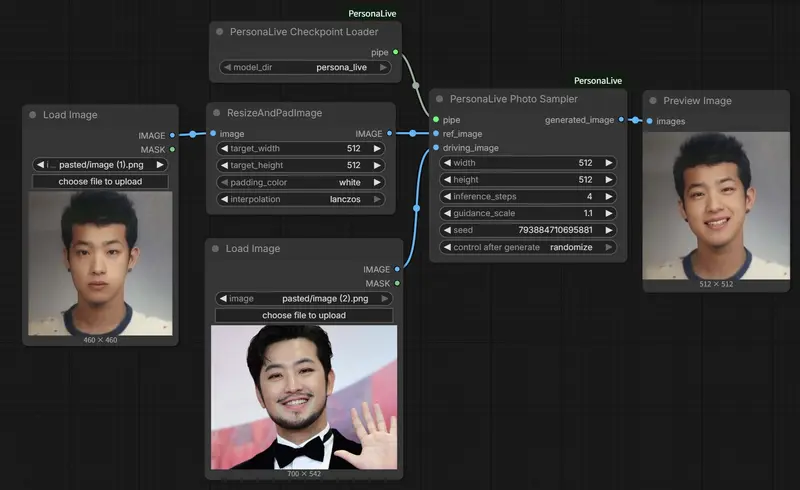
PersonaLive:基于扩散模型的实时肖像动画系统,延迟仅0.25秒在数字人、虚拟主播和直播场景中,高质量、低延迟、身份一致的肖像动画是核心需求。然而,主流扩散模型虽能生成逼真画面,却因高计算成本与多步去噪,难以满足实时交互要求——生成一段3秒视频往往需要数十秒,远不...视频模型# PersonaLive# 肖像动画3个月前0220
LIA-X:一种可解释的肖像动画方法,让面部动作“看得见、控得住”上海人工智能实验室和蔚蓝海岸大学的研究人员推出一种新颖的可解释肖像动画器LIA-X,旨在将驱动视频中的面部动态转移到源肖像上,并实现精细控制。 项目主页:https://wyhsirius.githu...视频模型# LIA-X# 肖像动画8个月前03940
MEMO:用于生成富有表情的、与音频同步的说话视频的端到端音频驱动肖像动画技术天工 AI、南洋理工大学和新加坡国立大学的研究人员提出了MEMO(Memory-Guided Emotion-Aware Diffusion),这是一种端到端的音频驱动肖像动画方法,旨在生成身份一致且...新技术# MEMO# 肖像动画1年前03510
基于扩散的肖像动画生成新方法JoyVASA:用于生成音频驱动的面部动画,包括面部动态和头部运动音频驱动的肖像动画在基于扩散模型的推动下取得了显著进展,提高了视频质量和唇同步的准确性。然而,这些模型的复杂性增加导致了训练和推理的低效,以及对视频长度和帧间连续性的限制。为了解决这些问题,京东健康国...图像模型# JoyVASA# 肖像动画1年前06690
肖像动画新技术EchoMimic:将静态的肖像照片转化为逼真的动态视频蚂蚁集团支付宝终端技术部推出肖像动画新技术EchoMimic,它可以将静态的肖像照片转化为逼真的动态视频。EchoMimic创新性地结合音频与面部标志点进行联合训练,并通过一项新颖的训练策略,使其不仅...新技术# EchoMimic# 肖像动画2年前05540