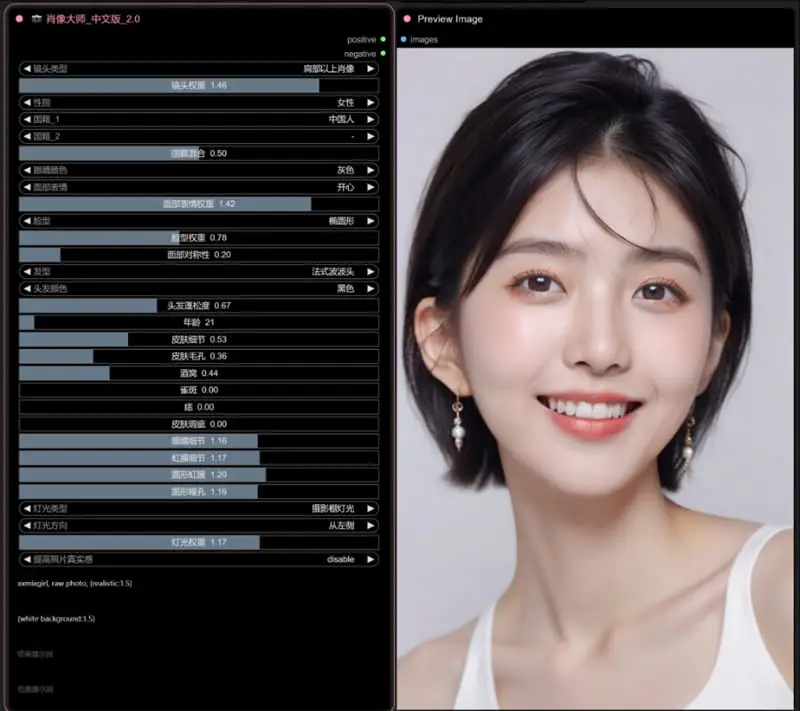
由澳门大学、Dzine.ai 与大湾区大学提出的 PersonaLive,是目前少有的能在扩散模型框架下实现低延迟、高保真肖像动画的模型。开发者okdalto打造的 ComfyUI-PersonaLive 插件,将该模型正式集成到 ComfyUI 生态中。
用户只需两张静态图像——一张源人像(ref_image)、一张姿态参考图(driving_image)——即可生成表情丰富、身份一致的动态肖像视频,推理仅需 4 步去噪,在 H100 上可达 15.8 FPS,平均延迟仅 0.25 秒。
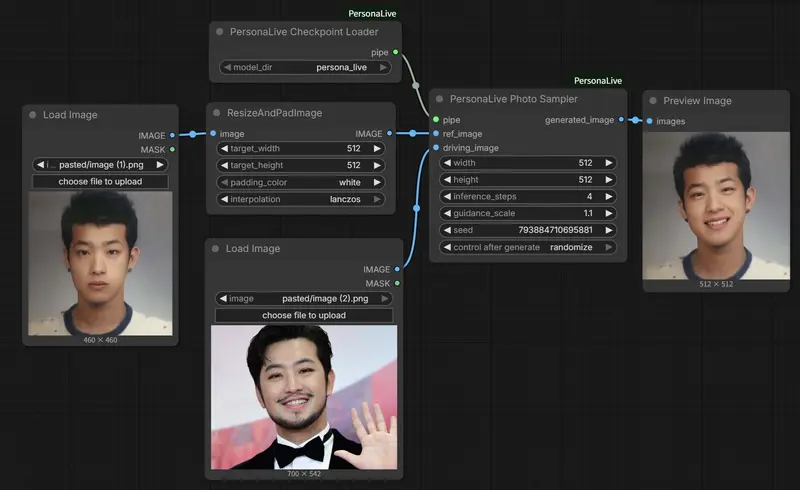
⚠️ 当前限制:仅支持图像驱动(单帧姿态参考),视频驱动功能将在后续版本中加入。
快速上手:三步完成部署
1️⃣ 安装插件
cd ComfyUI/custom_nodes/
git clone https://github.com/okdalto/ComfyUI-PersonaLive
cd ComfyUI-PersonaLive
pip install -r requirements.txt
2️⃣ 模型准备(推荐自动下载)
首次使用 PersonaLiveCheckpointLoader 节点时,插件将自动从 Hugging Face 下载以下模型(总计约 15–20GB):
- 基础扩散模型:
lambdalabs/sd-image-variations-diffusers - VAE:
stabilityai/sd-vae-ft-mse - PersonaLive 权重:
huaichang/PersonaLive
✅ 模型会缓存至本地,后续加载无需重复下载。
📂 手动下载路径(如需离线部署):
ComfyUI/models/persona_live/
├── sd-image-variations-diffusers/
├── sd-vae-ft-mse/
└── persona_live/pretrained_weights/personalive/
├── denoising_unet.pth
├── motion_encoder.pth
├── motion_extractor.pth
├── pose_guider.pth
├── reference_unet.pth
└── temporal_module.pth
3️⃣ 构建工作流
- 使用 PersonaLiveCheckpointLoader 加载模型(指定
model_dir = persona_live); - 连接至 PersonaLivePhotoSampler;
- 输入
ref_image(你的肖像)和driving_image(提供表情/姿态的参考图); - 设置分辨率(默认 512×512),节点会自动处理缩放与输出还原。
📌 提示:强烈建议输入 1:1 正方形图像,以获得最佳人脸对齐与生成质量。
关键使用技巧
- 推理步数:模型针对 4 步 优化。若需更高精度,可设为 8、12、16(必须为 4 的倍数),否则可能报错。
- 分辨率处理:输入图像会被自动缩放到 512×512 进行推理,输出时恢复原始尺寸,兼顾速度与画质。
- 示例工作流:项目
example/目录提供.json文件,可直接拖入 ComfyUI 快速复现效果。
技术亮点回顾
PersonaLive 的核心优势在于:
- 混合隐式信号控制:通过 3D 隐式关键点与隐式面部表示,精细驱动表情与头部运动;
- 微块流式生成:保障长时间动画的身份稳定性,避免“脸崩”;
- 4 步蒸馏推理:大幅降低计算开销,使扩散模型首次具备直播可行性。
ComfyUI-PersonaLive 将这一前沿能力开放给广大创作者,无需代码即可在可视化流程中调用。
未来展望
当前版本仅支持单帧图像驱动,但开发者已明确视频驱动(即用一段视频作为姿态源)将在后续更新中加入。这将进一步释放 PersonaLive 在虚拟直播、实时数字人等场景的潜力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











