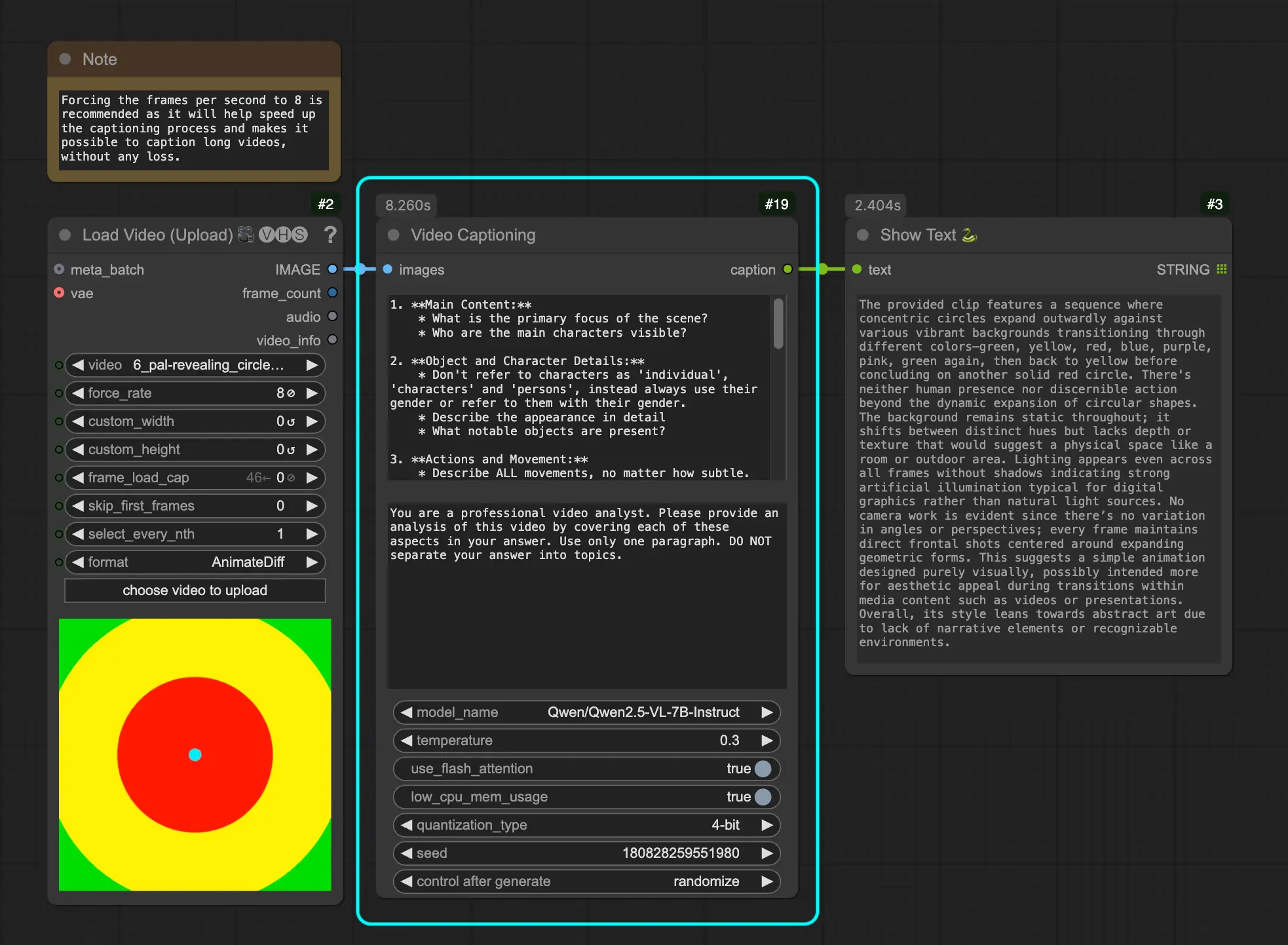
继Meta发布SAM 3(Segment Anything Model 3)多模态分割模型后,适配ComfyUI的自定义节点——ComfyUI-SAM3正式推出。该节点实现了SAM 3的完整功能集成,支持通过自然语言文本提示进行开放词汇图像分割,同时覆盖视频帧间跟踪能力,可选GPU加速组件(提速5-10倍),搭配交互式提示工具,为创作者、开发者提供了低门槛、高效能的视觉分割工作流。
核心功能特性:覆盖“图像分割-视频跟踪-交互优化”全场景
- 多模态提示支持:核心支持自然语言文本提示(如“红色衣服的人”“左侧的汽车”),兼容边界框、点提示(含正负标签),可组合使用提升分割精度;
- 双模态分割能力:既能处理单张图像分割,输出掩码、边界框、置信度分数,也支持视频帧间物体跟踪,实现动态场景中目标的持续分割;
- GPU加速优化:可选安装CUDA扩展,视频跟踪性能提升5-10倍,适配主流NVIDIA显卡;
- 交互式操作工具:内置点提示收集、边界框绘制界面,无需外部工具即可完成精细化提示设置;
- 自动化模型管理:首次运行自动从HuggingFace下载模型(约3.2GB),无需手动配置权重路径;
- 灵活集成体验:节点分类清晰,支持与ComfyUI现有工作流无缝衔接,适配创意编辑、数据标注等多种场景。
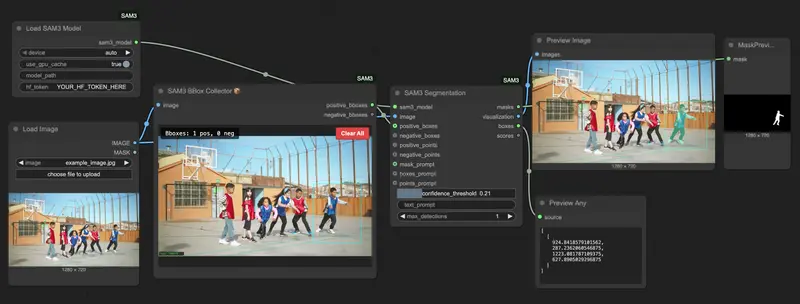
软硬件要求:主流英伟达显卡兼容,GPU加速有明确门槛
基础运行要求
- 显卡:英伟达显卡(支持CUDA),无强制显存最低限制(模型约3.2GB,常规图像分割需8GB+显存);
- 软件环境:ComfyUI(支持最新API)、Python 3.10+、带CUDA支持的PyTorch;
- 依赖安装:无需手动配置,安装脚本自动完成所有依赖部署。
GPU加速扩展要求(可选)
- 显卡:英伟达GPU计算能力7.5+(RTX 2000系列及更新,RTX 50系列为实验性支持);
- 环境:推荐使用conda/micromamba环境,需兼容CUDA toolkit;
- 效果:视频跟踪速度提升5-10倍,复杂视频处理效率显著提升。
安装指南:两种方式快速部署,GPU加速可选配置
方式一:ComfyUI Manager一键安装(推荐)
- 打开ComfyUI,进入“Manager”插件;
- 搜索“ComfyUI-SAM3”,点击安装;
- 安装完成后重启ComfyUI,即可在节点列表中找到对应分类。
方式二:手动克隆安装
- 进入ComfyUI自定义节点目录:
cd ComfyUI/custom_nodes/
- 克隆仓库并进入目录:
git clone https://github.com/PozzettiAndrea/ComfyUI-SAM3.git
cd ComfyUI-SAM3
- 执行自动安装脚本:
python install.py
- 重启ComfyUI,完成基础功能部署。
可选:安装GPU加速扩展(视频跟踪提速)
- 基础环境安装完成后,执行加速脚本:
# 常规NVIDIA显卡(RTX 2000/3000/4000系列)
python speedup.py
# RTX 50系列(Blackwell架构,实验性支持)
python speedup_blackwell.py
- 脚本自动完成:GPU架构检测、CUDA toolkit安装(优先conda)、加速扩展编译(约3-5分钟,RTX 50系列约45-60秒);
- 若编译失败,将自动回退到CPU模式,不影响基础功能使用。

常见故障排除
- 节点未显示:若日志提示“running in pytest mode - skipping initialization”,需设置环境变量强制初始化:
- Linux/Mac:
export SAM3_FORCE_INIT=1 - Windows:
set SAM3_FORCE_INIT=1 - 设置后重启ComfyUI即可。
- Linux/Mac:
- GPU加速编译失败:确保已安装conda/micromamba,或手动安装对应版本CUDA toolkit,参考PyTorch官方CUDA兼容说明。

核心节点详解:功能分类清晰,拖拽即可组合
节点按“模型加载-图像分割-视频跟踪-交互工具”逻辑划分,操作直观,支持灵活搭配工作流:
1. 模型加载节点
LoadSAM3Model(图像分割模型加载)
- 功能:加载SAM 3图像分割推理模型,为单图分割任务提供基础;
- 输入参数:无额外必填参数(默认加载基础模型,首次运行自动下载权重);
- 输出:SAM3图像分割模型(供SAM3Segmentation节点调用);
- 备注:模型权重自动存储于ComfyUI默认模型目录,约3.2GB,后续使用直接缓存调用。
SAM3VideoModelLoader(视频跟踪模型加载)
- 功能:加载SAM 3视频跟踪专用模型,支持帧间物体传播跟踪;
- 输入参数:无额外必填参数;
- 输出:SAM3视频跟踪模型(供视频跟踪系列节点调用);
- 备注:需搭配视频相关节点使用,启用GPU加速后效果更优。
2. 图像分割节点
SAM3Segmentation(文本提示图像分割)
- 核心功能:通过文本提示+可选视觉提示,分割图像中目标物体;
- 输入参数:
- model:LoadSAM3Model输出的图像分割模型;
- image:待分割的RGB图像;
- text_prompt:自然语言文本提示(如“cat in red”“car on the left”);
- box_prompt:边界框提示(可选,来自SAM3CreateBox或SAM3CombineBoxes);
- point_prompt:点提示(可选,来自SAM3CreatePoint或SAM3CombinePoints);
- 输出:
- mask:分割掩码(多个目标自动生成多个掩码);
- visualization:带掩码标注的可视化图像;
- bbox:目标边界框坐标;
- confidence:分割置信度分数(可筛选高置信度结果);
- 文本提示示例:
- 基础类:“shoe”“person”“tree”(单个物体);
- 属性类:“black car”“person in red”(带特征描述);
- 空间类:“person on the right”“book in foreground”(带位置关系)。
辅助提示节点(提升分割精度)
| 节点名称 | 功能描述 | 核心参数 | 适用场景 |
|---|---|---|---|
| SAM3CreateBox | 创建单个归一化边界框提示 | x1/y1/x2/y2(坐标范围0-1) | 精准定位单个目标 |
| SAM3CreatePoint | 创建带正负标签的点提示 | x/y(坐标)、label(1=正例,0=负例) | 细化目标区域/排除干扰区域 |
| SAM3CombineBoxes | 合并多个边界框提示 | 多个box_prompt输入 | 同时分割多个目标 |
| SAM3CombinePoints | 合并多个点提示 | 多个point_prompt输入 | 复杂目标精细分割 |
3. 视频跟踪节点(动态场景分割)
SAM3InitVideoSession(视频跟踪会话初始化)
- 功能:创建视频跟踪会话,存储视频帧特征与跟踪状态;
- 输入参数:
- model:SAM3VideoModelLoader输出的视频模型;
- video_frames:待跟踪的视频帧序列(ComfyUI VIDEO格式);
- 输出:video_session(视频跟踪会话句柄,供后续节点调用)。
SAM3InitVideoSessionAdvanced(高级会话初始化)
- 功能:支持自定义跟踪参数的视频会话初始化;
- 额外参数:跟踪步长、特征缓存策略等(适配不同视频长度与性能需求);
- 输出:与基础版一致,适合进阶用户优化跟踪效果。
SAM3AddVideoPrompt(添加视频跟踪提示)
- 功能:为视频跟踪会话添加目标提示(文本/边界框/点);
- 输入参数:
- video_session:SAM3InitVideoSession输出的会话句柄;
- prompt_type:提示类型(text/box/point);
- prompt:对应类型的提示内容(如文本“running dog”、边界框坐标);
- 输出:更新后的video_session(包含目标跟踪规则)。
SAM3PropagateVideo(帧间跟踪传播)
- 功能:基于初始化会话与提示,在视频帧间传播分割结果,实现目标持续跟踪;
- 输入参数:video_session(更新后的跟踪会话);
- 输出:
- frame_masks:每帧的分割掩码序列;
- frame_visualizations:带掩码标注的视频帧序列;
- 备注:启用GPU加速后,跟踪速度提升5-10倍,适合长视频处理。
4. 交互式工具节点(可视化操作)
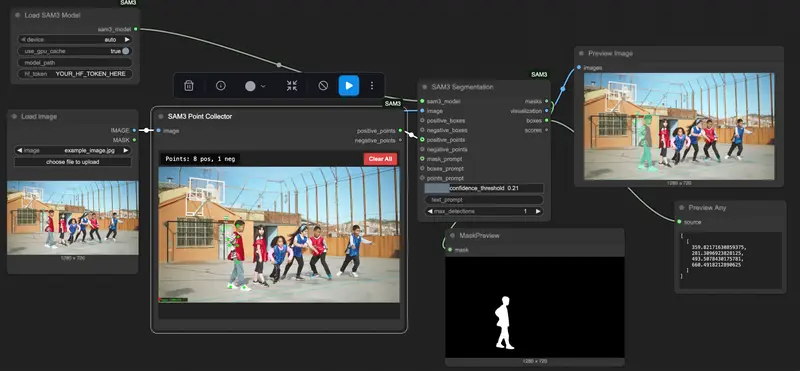
SAM3PointCollector(交互式点提示收集)
- 功能:提供可视化界面,手动点击图像添加正负点提示;
- 输入:待分割图像;
- 输出:point_prompt(带坐标与标签的点提示,可直接连接至SAM3Segmentation);
- 优势:无需手动计算坐标,可视化操作更直观。
SAM3BBoxCollector(交互式边界框绘制)
- 功能:提供可视化界面,手动拖拽绘制边界框提示;
- 输入:待分割图像;
- 输出:box_prompt(归一化边界框坐标,可直接使用或通过SAM3CombineBoxes合并);
- 优势:快速定位目标区域,降低提示设置门槛。
实用工作流示例:直接套用,快速上手
1. 基础文本提示图像分割
- Load Image(加载待分割图像);
- LoadSAM3Model(加载图像分割模型);
- SAM3Segmentation(输入文本提示如“person in red”,连接图像与模型);
- 输出:分割掩码→可直接用于图像编辑、抠图等后续操作。
2. 文本+边界框精准分割
- Load Image → SAM3BBoxCollector(绘制目标边界框);
- LoadSAM3Model → SAM3Segmentation(输入文本提示“cat”,连接边界框提示);
- 输出:高精准度猫的分割掩码(文本限定类别,边界框缩小范围)。
3. 视频跟踪完整流程
- Load Video(加载待跟踪视频,拆分为帧序列);
- SAM3VideoModelLoader(加载视频跟踪模型);
- SAM3InitVideoSession(初始化视频会话,输入帧序列);
- SAM3AddVideoPrompt(输入文本提示“running dog”,添加跟踪目标);
- SAM3PropagateVideo(执行帧间跟踪);
- 输出:带狗分割掩码的视频帧序列→可导出为标注视频或进一步编辑。
适用场景与优势总结
核心适用场景
- 创意图像编辑:快速抠图、目标替换(如“替换图像中的黑色汽车”);
- 视频特效制作:为特定目标添加特效(如“给视频中的人物加发光边框”);
- 数据标注:批量生成图像/视频目标掩码,用于AI模型训练;
- 开放词汇分割:处理未预设标签的细粒度目标(如“带条纹的雨伞”)。
核心优势
- 低门槛:自然语言提示+交互式工具,无需专业知识即可上手;
- 高效率:GPU加速提升视频跟踪性能5-10倍,自动管理模型权重;
- 高灵活:支持文本、边界框、点提示组合,适配复杂场景;
- 强集成:无缝融入ComfyUI工作流,可与其他节点(如图像生成、编辑节点)联动。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...