在AI绘画创作中,高质量的Prompt(提示词)是生成优质作品的核心,但手动打磨Prompt耗时耗力,且普通增强工具难以结合图像特征实现精准优化。针对这一痛点,ComfyUI-Z-Image-Utilities应运而生——这款专为Z-Image模型量身打造的节点合集,以“多后端适配、图像感知增强、低门槛运行”为核心,为ComfyUI用户提供了一站式的Prompt优化解决方案,覆盖从云端到本地的全场景部署需求,大幅提升AI绘画工作流效率。
核心亮点:三大维度重构Prompt增强体验
1. 多后端自由选择,部署灵活无限制
工具支持OpenRouter云端、本地API服务(Ollama/LM Studio等)、HuggingFace直接加载三种后端模式,适配不同用户的使用场景:
- 云端模式(OpenRouter):无需本地算力,免费领取API Key即可使用,一键调用qwen3-235b等大模型,适合无高端显卡的用户;
- 本地API模式:对接Ollama、vLLM等本地服务,数据隐私有保障,响应速度更快,适合有一定技术基础的开发者;
- Direct直载模式:直接从HuggingFace下载模型到本地运行,支持4bit/8bit量化,消费级显卡也能流畅运行8B级大模型,兼顾隐私与灵活性。
2. 图像感知Prompt增强,精准贴合创作需求
区别于传统文本Prompt增强工具,该节点合集内置视觉-语言模型,能实现“图像感知”的智能增强——即结合输入图像的内容特征(如构图、色彩、主体),生成更贴合画面风格与细节的Prompt,避免增强后的提示词与图像脱节。同时支持中英文双语自动识别,无需手动切换语言设置,适配全球用户创作习惯。
3. 低门槛+高稳定性,工作流无缝衔接
- 硬件友好:4bit/8bit量化技术大幅降低显存占用(8B模型4bit仅需6GB显存),普通显卡也能驾驭大模型;
- 智能优化:自动清理LLM输出中的冗余、重复内容及思考标签(如),无需手动整理,直接对接后续节点;
- 稳定可靠:内置指数退避重试机制与限流处理,有效应对云端API调用失败、本地模型卡顿等问题;
- 极简工作流:支持直接输出CLIP条件编码,跳过传统“Prompt增强→CLIP编码”步骤,简化节点连接,提升创作效率。
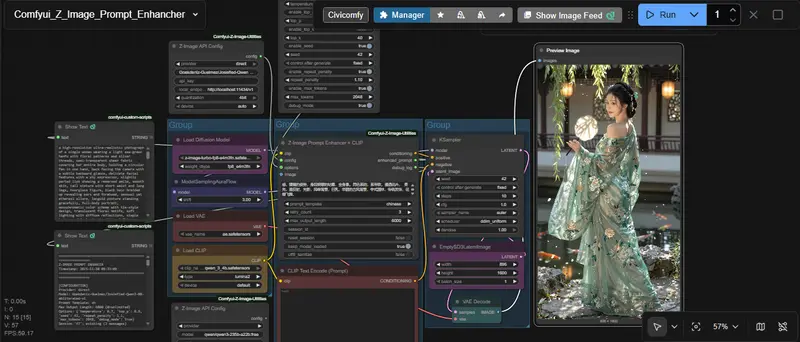
核心功能与节点详解
1. 核心功能模块
| 功能模块 | 核心价值 | 适用场景 |
|---|---|---|
| Prompt增强 | 图像感知+文本优化,生成高质量提示词 | 所有AI绘画创作,尤其适合新手用户 |
| 多后端配置 | 云端/本地/直载自由切换,适配不同硬件/隐私需求 | 无显卡(云端)、追求隐私(本地)、灵活部署(直载) |
| 会话管理 | 多轮对话+历史记录持久化,支持连续优化Prompt | 需要反复调整Prompt的精细化创作 |
| 模型卸载与清理 | 释放显存+清除对话历史,避免资源占用 | 多模型切换、长时创作场景 |
| 高级推理参数调节 | 温度、top_p、seed等参数自定义,控制生成风格 | 追求个性化Prompt的专业创作者 |
2. 关键节点用法
| 节点名称 | 核心作用 | 操作要点 |
|---|---|---|
| Z-Image API Config | 配置后端连接 | 选择Provider(openrouter/local/direct),填写API Key或Endpoint |
| Z-Image Options | 调节推理参数 | 根据需求设置温度(控制随机性)、top_p(控制多样性)、repeat_penalty(避免重复) |
| Z-Image Prompt Enhancer | 核心Prompt增强 | 输入原始Prompt+参考图像,输出优化后提示词 |
| Z-Image Prompt Enhancer + CLIP | 增强+CLIP编码一体化 | 直接输出CLIP条件编码,对接KSampler节点,简化工作流 |
| Z-Image Unload Models | 释放显存 | 多模型切换前运行,避免显存溢出 |
| Z-Image Clear Sessions | 清除对话历史 | 需重新优化Prompt时使用,避免历史记录干扰 |
快速安装与部署指南
1. 基础安装步骤
# 进入ComfyUI自定义节点目录
cd ComfyUI/custom_nodes/
# 克隆项目
git clone https://github.com/Koko-boya/ComfyUI-Z-Image-Utilities.git
安装完成后重启ComfyUI,即可在节点面板中找到“Z-Image”相关节点。
2. 额外依赖安装(仅Direct直载模式)
若需使用本地直载HuggingFace模型,需安装依赖包:
pip install torch transformers accelerate bitsandbytes huggingface-hub
3. 三种后端快速配置
方式1:OpenRouter云端(最简单)
- 访问OpenRouter官网,免费注册并领取API Key;
- 打开“Z-Image API Config”节点,设置:
- Provider:openrouter
- Model:推荐qwen/qwen3-235b-a22b:free(免费高画质)
- API Key:粘贴领取的密钥,保存即可使用。
方式2:本地API服务(以Ollama为例)
- 安装Ollama:
curl -fsSL https://ollama.ai/install.sh | sh - 拉取模型(推荐qwen2.5:14b):
ollama pull qwen2.5:14b - 节点设置:
- Provider:local
- Model:qwen2.5:14b
- Local Endpoint:http://localhost:11434/v1
方式3:Direct直载HuggingFace模型
- 节点设置:
- Provider:direct
- Model:推荐Qwen/Qwen2.5-7B-Instruct(官方纯SFW)或Goekdeniz-Guelmez/Josiefied-Qwen3-8B-abliterated-v1(支持SFW+NSFW)
- Quantization:4bit(推荐,平衡性能与显存)
- 首次使用会自动下载模型到
ComfyUI/models/LLM/Z-Image/目录,耐心等待即可。
4. 推荐工作流示例
普通工作流(适合新手)
[Z-Image API Config] → [Z-Image Options] → [Z-Image Prompt Enhancer] → [CLIP Text Encode] → [KSampler]
极简工作流(适合追求高效)
[Checkpoint Loader] → [Z-Image API Config] → [Z-Image Prompt Enhancer + CLIP] → [KSampler]
常见问题与解决方案
| 问题现象 | 排查与解决办法 |
|---|---|
| 节点不显示 | 1. 确认安装路径正确(ComfyUI/custom_nodes/);2. 重启ComfyUI;3. 设置环境变量(Linux/Mac:export SAM3_FORCE_INIT=1;Windows:set SAM3_FORCE_INIT=1) |
| 输出为空或报错 | 1. 检查API Key/Endpoint是否正确;2. 增加“Z-Image Options”中的retry_count;3. 确认模型已成功下载(Direct模式) |
| 显存溢出(OOM) | 1. 切换为4bit量化;2. 选择更小参数量模型(如7B→8B);3. 运行“Z-Image Unload Models”卸载其他缓存模型 |
| 输出仍有冗余标签(如) | 更新工具到最新版本(git pull),新版本已优化智能输出清理功能 |
| 本地API连接失败 | 1. 确认本地服务(Ollama/LM Studio)已启动;2. 检查Endpoint地址与服务默认地址一致(参考常见本地服务默认地址表) |
常见本地服务默认地址参考
| 服务名称 | 默认Endpoint |
|---|---|
| Ollama | http://localhost:11434/v1 |
| LM Studio | http://localhost:1234/v1 |
| vLLM | http://localhost:8000/v1 |
| text-generation-webui | http://localhost:5000/v1 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...