Comfyui_turbodiffusion 是一个专为 图生视频模型TurboDiffusion 设计的 ComfyUI 自定义节点集合,支持 双专家采样、稀疏线性注意力(SLA)加速、int8 量化模型,并在 RTX 3090/4090 级别显卡上实现 720p、77 帧视频 60–90 秒内生成。
核心功能
✅ 端到端图转视频流程
单一采样器节点完成:文本编码 → VAE 编码 → 双模型采样 → 视频解码
✅ SLA 稀疏线性注意力
推理速度提升 2–3 倍,显存占用更低(RTX 3090 实测 12–15GB)
✅ 双专家采样机制
- 高噪声模型:处理前期粗略运动结构
- 低噪声模型:优化后期细节与画质
- 自动切换:在采样 90% 处(如 4 步中的第 3.6 步)无缝交接
✅ 智能内存管理
- 自动加载/卸载模型,避免显存溢出
- 与 ComfyUI 原生模型管理系统深度集成
- VAE 支持时序视频帧(B, C, T, H, W),非普通图像 VAE
✅ 无需外部依赖
TurboDiffusion 代码已集成,无需单独安装,开箱即用
系统要求
- GPU:NVIDIA RTX 3090 / 4090 或更高(12GB+ 显存)
- 软件:Python ≥ 3.9,PyTorch ≥ 2.0,ComfyUI(最新版)
低显存用户建议使用 480 分辨率 + 49 帧;24GB+ 显存可尝试 720p + 77 帧以上
安装步骤
cd ComfyUI/custom_nodes/
git clone https://github.com/anveshane/Comfyui_turbodiffusion.git
重启 ComfyUI 使节点生效。
模型准备
将以下文件放入对应 ComfyUI 目录:
| 类型 | 文件名 | 路径 |
|---|---|---|
| 模型 | TurboWan2.2-I2V-A14B-high-720P-quant.pthTurboWan2.2-I2V-A14B-low-720P-quant.pth | ComfyUI/models/diffusion_models/ |
| VAE | wan_2.1_vae.safetensors | ComfyUI/models/vae/ |
| 文本编码器 | umt5-xxl_fp8_scaled.safetensors | ComfyUI/models/clip/ 或 text_encoders/ |
模型:
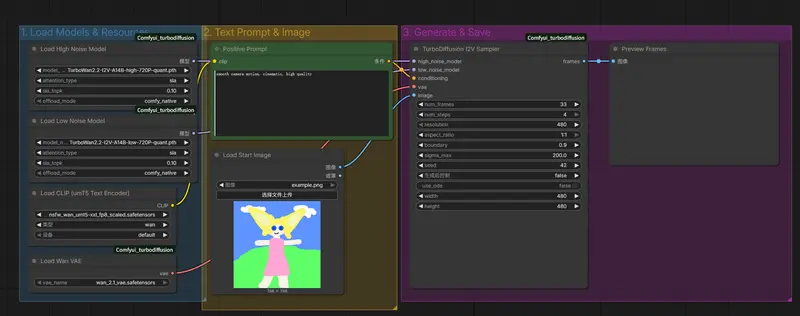
标准工作流(8 个节点)
TurboWanModelLoader→ 加载高噪声模型(带 SLA)TurboWanModelLoader→ 加载低噪声模型(带 SLA)CLIPLoader→ 加载 umT5-xxl 文本编码器CLIPTextEncode→ 输入提示词TurboWanVAELoader→ 加载 时序 VAE(⚠️ 非标准 VAE)LoadImage→ 上传起始图像TurboDiffusionI2VSampler→ 执行完整推理TurboDiffusionSaveVideo→ 导出 MP4/GIF/WebM
完整流程示例见项目中的 turbowan_workflow.json。
关键节点说明
TurboDiffusionI2VSampler(核心采样器)
重要参数:
num_frames:必须为 8n+1(如 49, 77, 121)num_steps:1–4 步,推荐 4resolution:"480"(低显存)、"480p"(平衡)、"720p"(高画质)boundary:模型切换点,默认 0.9use_ode:设为 false(使用 SDE,更稳定)
TurboWanVAELoader
⚠️ 注意:此 VAE 专为视频时序设计,输入/输出为 (B, C, T, H, W),
不能与 ComfyUI 默认 VAE 节点混用。
性能实测(RTX 3090)
| 配置 | 生成时间 | 显存占用 |
|---|---|---|
| 720p, 77 帧, 4 步 | 60–90 秒 | 12–15 GB |
| 启用 SLA vs 原始注意力 | 快 2–3 倍 | 显存更低 |
加速模式建议(实测经验)
经多环境测试,最稳定配置为:
attention_type = "sla"- 执行模式 =
layerwise_gpu
其他选项(如 sagesla、original)在部分 Windows + CUDA 环境下可能报错或崩溃。
建议优先使用 sla,确保稳定性。
故障排查
| 问题 | 解决方案 |
|---|---|
| 节点未加载 | 安装后重启 ComfyUI |
| 模型未找到 | 检查模型是否在正确子目录 |
| CUDA OOM | 降低分辨率或帧数(如用 480 + 49 帧) |
| 采样器缺失 | 确认 turbodiffusion_vendor/ 目录已完整复制 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











