视频扩散模型虽能生成高质量内容,但其缓慢的推理速度长期制约实际应用。近日,清华大学、生数科技与加州大学伯克利分校联合提出 TurboDiffusion——一个端到端视频生成加速框架,在单张 RTX 5090 显卡上实现了 100–200 倍的推理加速,同时保持与原始模型相当的视频质量。
这意味着,原本需耗时 75 分钟(4549 秒)生成一段 720p 视频的任务,现在仅需 38 秒即可完成。

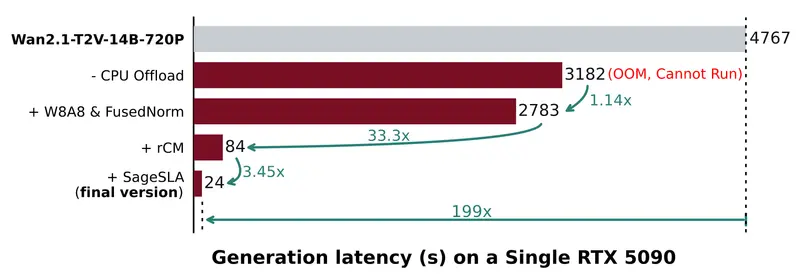
核心技术:三重加速策略
TurboDiffusion 并非依赖单一技巧,而是通过系统性优化实现突破:
1. 注意力机制加速
- 采用 SageAttention:一种低比特(<8-bit)注意力实现,显著降低计算开销。
- 引入 可训练的稀疏线性注意力(Sparse-Linear Attention, SLA):在保持建模能力的同时,减少冗余计算。
2. 采样步数压缩
- 基于 rCM(score-regularized continuous-time consistency) 方法进行步长蒸馏,将原本数百步的扩散过程压缩至极低步数(通常 ≤10 步),大幅缩短生成路径。
3. 全模型 W8A8 量化
- 将权重(W)与激活值(A)统一量化为 8 位整数,在不显著损失精度的前提下,加速线性层运算并减小显存占用。
此外,框架还重实现了 LayerNorm / RMSNorm 等基础操作,进一步提升底层效率。
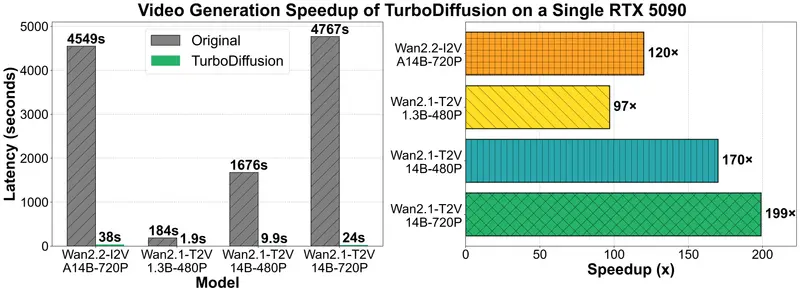
实测性能:从小时级到秒级
在多个主流视频扩散模型上的测试结果如下(均基于单卡 RTX 5090):
| 模型 | 原始延迟 | TurboDiffusion 延迟 | 加速比 |
|---|---|---|---|
| Wan2.2-I2V-A14B-720P | 4549 秒 | 38 秒 | 120× |
| Wan2.1-T2V-1.3B-480P | 184 秒 | 1.9 秒 | 97× |
| Wan2.1-T2V-14B-720P | 4767 秒 | 24 秒 | 199× |
| Wan2.1-T2V-14B-480P | 1676 秒 | 9.9 秒 | 169× |
注:所有 Turbo 模型均支持生成 480p 或 720p 视频,“最佳分辨率”指质量最优的输出尺寸。
开源模型与可用性
项目已开源全部代码、训练/推理脚本及模型检查点,支持以下四个优化版本:
| 模型名称 | 最佳分辨率 | 用途 |
|---|---|---|
| TurboWan2.2-I2V-A14B-720P | 720p | 图像到视频(I2V) |
| TurboWan2.1-T2V-1.3B-480P | 480p | 文本到视频(T2V),轻量级 |
| TurboWan2.1-T2V-14B-480P | 480p | 高质量 T2V,标准分辨率 |
| TurboWan2.1-T2V-14B-720P | 720p | 高质量 T2V,高清输出 |
模型可在 Hugging Face 获取,便于开发者快速集成到现有工作流。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...