
老旧视频模糊、噪点多、细节丢失,能否通过 AI 实现自然且真实的画质增强?
传统视频修复方法往往在提升分辨率的同时,引入伪影、纹理失真或帧间抖动。而基于扩散模型的新一代生成技术,虽然具备强大的细节生成能力,却容易在修复过程中偏离原始内容,导致结构错乱、时间不连贯、质感失真。
为此,阿里巴巴淘天集团提出 Vivid-VR ——一种基于 DiT 架构的生成式视频修复方法,目标是:
在保留原始语义的前提下,恢复真实纹理,确保时间一致性,实现“既清晰又可信”的高质量修复。
Vivid-VR 并非简单地“放大”视频,而是通过控制生成机制与概念知识迁移的协同设计,系统性解决当前可控扩散模型在微调中常见的“分布漂移”问题。
其核心成果已在多个真实与合成数据集上验证:在纹理质量、视觉生动性和时间连贯性方面,全面优于现有方法。

视频修复的难点:控制与真实感的平衡
理想的视频修复不仅要提升分辨率,还需满足三个关键要求:
- 内容一致性:修复后的画面应忠实于原意,不凭空添加或扭曲结构;
- 纹理真实性:生成的细节(如皮肤、毛发、建筑纹理)需自然逼真,而非机械重复;
- 时间连贯性:帧与帧之间过渡平滑,无闪烁、抖动或跳跃。
然而,当前主流基于 ControlNet 的可控生成方法,在应用于视频修复时面临一个根本挑战:
微调过程中的多模态对齐不完善,导致“分布漂移”。
具体表现为:模型在学习“如何根据低质量视频生成高质量结果”时,未能充分对齐文本描述、视觉内容和时间动态,从而在生成中出现语义偏移、纹理失真或帧间断裂。
Vivid-VR 的解决方案:概念提炼 + 控制增强
Vivid-VR 从两个层面入手,重构训练与推理流程:
- 训练阶段:通过“概念提炼”稳定知识迁移;
- 架构层面:重新设计控制路径,提升信号保真度。
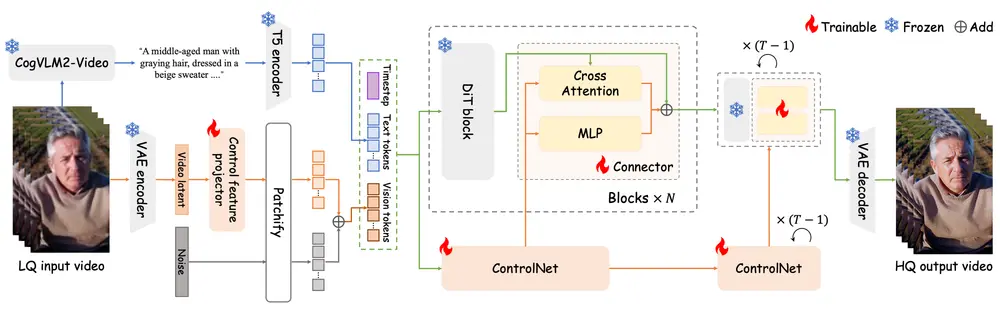
一、概念提炼训练策略(Concept Distillation)
传统微调依赖真实修复数据配对(低质 → 高质),但这类数据稀缺且标注成本高。Vivid-VR 转而利用预训练文本到视频(T2V)模型自身的能力,合成高质量训练样本。
流程如下:
- 使用 CogVLM2-Video 对输入低质量视频生成语义描述;
- 将描述送入 T5 编码器 转为文本嵌入;
- 利用预训练 T2V 模型,以该文本为条件,生成对应的高保真视频作为“合成目标”;
- 将这些文本-视频对用于微调 Vivid-VR 模型。
这一过程相当于将 T2V 模型中已有的“概念理解能力”蒸馏到修复模型中,使其在修复时不仅能“看清”,还能“理解”画面内容。
优势:
- 缓解因数据不足导致的过拟合;
- 增强文本与视觉在潜在空间中的对齐;
- 保留原始语义,减少分布漂移。
二、控制架构升级:双管齐下
为了更精准地引导生成过程,Vivid-VR 对 ControlNet 架构进行了两项关键改进:
1. 控制特征投影器(Control Feature Projector)
低质量视频的潜在表示中常含有噪声、压缩伪影等退化信号。若直接输入生成模型,这些误差会被放大。
Vivid-VR 引入一个轻量级 CNN 模块,作为 VAE 编码器的扩展:
- 接收低质量视频的潜在特征;
- 主动过滤退化成分;
- 输出“净化后”的控制信号。
作用:从源头减少错误传播,提升生成稳定性。
2. 双分支 ControlNet 连接器(Dual-Branch Connector)
传统 ControlNet 通常采用简单拼接或加权融合方式连接控制信号与主干 DiT。这种方式难以兼顾内容保留与动态调节。
Vivid-VR 提出双分支设计:
- MLP 分支:负责全局特征映射,保持结构一致性;
- 交叉注意力分支:实现动态特征检索,允许局部细节自适应调整;
- 两路输出融合后注入 DiT 的各个层级。
效果:既能忠实还原原始内容,又能灵活增强纹理细节,实现“可控而不僵化”。
支持任务与典型应用场景
Vivid-VR 主要面向以下视频修复任务:
| 任务类型 | 输入 | 输出 | 应用场景 |
|---|---|---|---|
| 单帧增强 | 模糊/低清图像 | 高清图像序列 | 老照片动画化 |
| 视频超分 | 480p/720p 视频 | 1080p/4K 视频 | 影像资料修复 |
| 去噪去压 | 压缩严重、带马赛克视频 | 清晰流畅视频 | 用户上传内容优化 |
| 细节恢复 | 结构模糊、纹理丢失视频 | 纹理丰富、结构清晰视频 | 文创、影视后期 |
典型修复效果示例:
- 修复模糊风景视频中的房屋轮廓,使其结构合理、边缘清晰;
- 还原人物面部细节,生成自然肤色与毛发纹理;
- 增强动物皮毛、织物、树叶等复杂材质的真实感;
- 保持运动轨迹稳定,避免修复后出现“呼吸效应”或闪烁。
实验结果:指标与主观评价双领先
定量评估
在多个基准测试集上,包括:
- 合成退化数据集
- 真实老旧视频
- AIGC 生成但质量较低的视频
Vivid-VR 在以下指标上均优于现有方法:
| 指标 | 类型 | Vivid-VR 表现 |
|---|---|---|
| PSNR / SSIM | 全参考 | 显著高于对比模型 |
| LPIPS | 感知相似度 | 更接近原始高清源 |
| NIQE / MUSIQ / CLIP-IQA | 无参考质量评分 | 分数更优,表明视觉质量更高 |
| DOVER | 视频整体质量预测 | 综合得分领先 |
特别是在 LPIPS 和 NIQE 上的优势,说明其生成结果不仅清晰,而且更符合人类视觉偏好。
定性评估
人工盲测评结果显示,Vivid-VR 在以下维度得分最高:
- 纹理真实感:皮肤、毛发、材质细节更自然;
- 结构合理性:建筑、人脸等几何结构更准确;
- 时间连贯性:无明显帧间跳变或闪烁;
- 整体生动性:画面更具“生命力”,而非机械锐化。
例如,在一段模糊的家庭录像修复中,Vivid-VR 成功还原了儿童面部表情的细微变化,同时保持背景稳定,实现了“清晰而不失真”的效果。
技术亮点总结
| 特性 | 说明 |
|---|---|
| ✅ 概念提炼训练 | 利用预训练 T2V 模型生成高质量合成数据,缓解分布漂移 |
| ✅ 控制特征净化 | 投影器过滤潜在空间中的退化信号,提升输入质量 |
| ✅ 双分支连接器 | MLP + 交叉注意力协同工作,兼顾内容保留与动态控制 |
| ✅ 时间一致性保障 | 基于 DiT 的时空建模能力,天然支持帧间连贯生成 |
| ✅ 无需额外标注 | 训练数据可自动生成,降低数据依赖 |
局限与使用建议
- 依赖强文本理解模型:需 CogVLM2-Video 等高质量视频描述模型配合;
- 计算资源要求较高:适合在 GPU 集群或云环境中部署;
- 对极端损坏视频仍有挑战:如大面积缺失或严重抖动,需结合其他预处理手段;
- 尚未开源:目前仅披露技术方案,模型与代码暂未公开。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











