视觉扩散模型虽已取得显著进展,但受限于“高分辨率训练数据稀缺”与“计算资源消耗大”,多数模型只能在低分辨率(如512×512)下训练,导致生成高保真图像、视频时容易出现“重复模式”“细节模糊”等问题——尤其是生成超出训练分辨率的内容时,高频信息增加会引发累积误差,进一步降低视觉质量。
- 项目主页:https://eyeline-labs.github.io/CineScale
- GitHub:https://github.com/Eyeline-Labs/CineScale
- 模型:https://huggingface.co/Eyeline-Labs/CineScale
为解决这一痛点,南洋理工大学与Netflix Eyeline Studios的研究团队提出了CineScale:一种专为高分辨率视觉生成设计的新型推理范式。它无需复杂调优,就能让预训练扩散模型突破分辨率限制,不仅支持文本到图像(T2I)、文本到视频(T2V),还扩展到图像到视频(I2V)、视频到视频(V2V)等多任务,甚至能实现“免微调8K图像生成”“最小LoRA微调4K视频生成”,为影视、设计等领域提供了高性价比的高分辨率解决方案。

一、CineScale的核心能力:突破分辨率与任务边界
CineScale的核心价值在于“用更轻量的方式,解锁扩散模型的高分辨率潜力”,具体能力可从“图像生成”“视频生成”“多任务支持”三大维度展开:
1. 图像生成:免微调从512×512扩展至8K
对于预训练图像扩散模型(如常见的T2I模型),CineScale无需任何额外训练或微调,就能将生成分辨率从基础的512×512,逐步提升至8192×8192(即8K)。关键在于,提升分辨率的同时,图像的“细节完整性”与“整体结构一致性”不会受损——例如生成“城市夜景”时,8K分辨率下的窗户灯光、建筑纹理、夜空星点等细节清晰可辨,不会出现传统高分辨率生成中常见的“重复灯光图案”“边缘模糊”问题。
这种“免微调”特性大幅降低了使用门槛:开发者无需为高分辨率场景重新训练模型(省去大量数据与计算成本),直接调用预训练模型+ CineScale推理范式,即可输出8K高保真图像。
2. 视频生成:最小LoRA微调实现4K流畅输出
视频生成的分辨率突破难度更高(需兼顾帧内细节与帧间流畅性),CineScale采用“最小LoRA微调”策略——仅对模型关键层进行少量参数调整,即可将低分辨率视频(如320×512)扩展至2176×3840(4K)。
测试显示,4K视频生成时,CineScale能同时保证“视觉质量”与“动态流畅性”:例如生成“海浪拍打海岸”的视频,4K分辨率下海浪的泡沫纹理、沙滩的颗粒感清晰可见,且相邻帧之间的运动轨迹连贯,不会出现“画面抖动”“细节跳变”等问题,满足影视级预制作、广告片等专业场景需求。
3. 多任务支持:覆盖T2I/T2V/I2V/V2V全场景
不同于现有高分辨率生成方法仅支持“文本到图像/视频”,CineScale将应用范围扩展至“图像到视频(I2V)”与“视频到视频(V2V)”,实现多任务覆盖:
- I2V(图像到视频):输入一张静态图像(如“森林日落”),可生成基于该图像风格与内容的4K动态视频(如“日落时分森林中光影变化、树叶飘动”);
- V2V(视频到视频):输入一段低分辨率视频(如720P的“人物行走”),可提升至4K分辨率,同时支持局部语义编辑(如修改人物服装颜色、背景场景)。
这种全场景支持能力,让CineScale可适配更多实际需求——例如设计师可通过I2V将静态概念图转化为动态演示视频,影视后期团队可通过V2V将低清素材修复为4K高清版本。
二、核心技术:四大创新破解高分辨率生成难题
CineScale之所以能突破分辨率限制,关键在于其针对扩散模型高分辨率生成的痛点,设计了四大核心技术模块,从“上采样”“细节融合”“模型适配”等维度系统性解决问题:
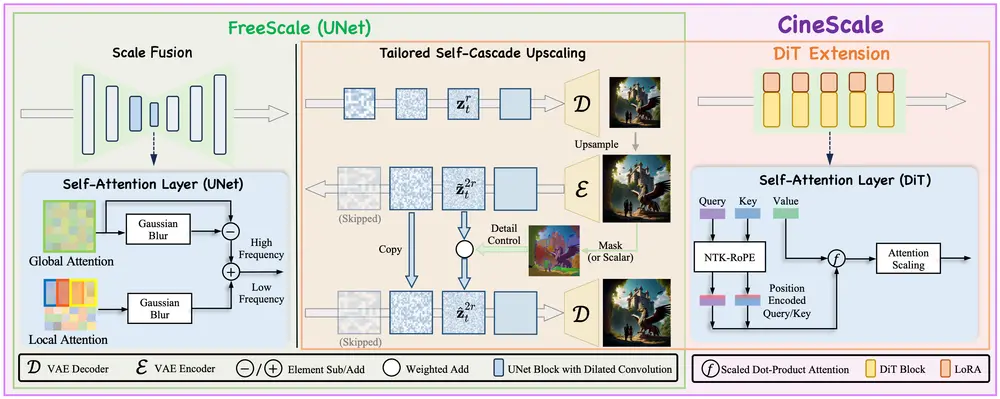
1. 自适应级联上采样:逐步重建高分辨率细节
传统高分辨率生成常采用“一次性上采样”,容易导致细节丢失或重复。CineScale采用“定制自级联上采样”策略:
- 先将模型生成的低分辨率内容(如512×512图像)逐步上采样至目标分辨率(如8K);
- 上采样过程中,向高分辨率“潜在表示”(模型内部的特征数据)逐步添加少量噪声;
- 去噪阶段,重新引入部分“干净的潜在表示”(未添加噪声的低分辨率特征),稳定生成过程,避免高频信息累积误差导致的重复模式。
这种“逐步上采样+噪声控制”的方式,能在低分辨率阶段先确定合理的视觉结构(如人物轮廓、场景布局),再在高分辨率阶段精准补充细节(如皮肤纹理、物体纹理),确保“整体不跑偏,细节不重复”。
2. 尺度融合:平衡全局结构与局部细节
扩散模型生成高分辨率内容时,常出现“全局结构混乱”或“局部细节缺失”的问题。CineScale通过“尺度融合”技术解决这一矛盾:
- 注意力层优化:修改UNet结构的自注意力层,同时结合“全局注意力”(捕捉场景整体关联,如人物与背景的位置关系)与“局部注意力”(聚焦局部细节,如人物面部特征);
- 频率融合:通过高斯模糊处理,将高频细节(如纹理、边缘)与低频语义(如物体形状、场景结构)融合,避免高频信息过度堆积导致的重复;
- 受限扩张卷积:在模型卷积层应用“受限扩张卷积”,扩大卷积感受野(即模型能“看到”的图像范围),减少局部区域的重复纹理生成。
3. DiT扩展:适配Transformer类扩散模型
针对基于Transformer的扩散模型(如DiT模型),CineScale额外设计了“DiT扩展”模块,解决高分辨率下的注意力计算问题:
- NTK-RoPE:引入动态RoPE(旋转位置编码)调整策略,让模型在高分辨率图像/视频的大尺寸特征图上,仍能精准捕捉位置信息,避免注意力分散;
- 注意力缩放:对注意力权重进行自适应缩放,平衡不同分辨率下的注意力分配;
- 最小LoRA微调:仅对与RoPE相关的少量参数进行LoRA微调,帮助模型快速适应高分辨率输入,无需全量训练,大幅降低计算成本。
4. 频率选择性提取:优化细节质量
高分辨率内容包含大量高频信息,若盲目保留所有高频信号,容易引入噪声。CineScale通过“频率选择性提取”技术:
- 对生成过程中的特征数据进行频率分解,区分“有效高频细节”(如物体纹理、边缘轮廓)与“无效高频噪声”(如随机斑点、重复纹路);
- 选择性保留有效高频信息,过滤无效噪声,同时融合低频语义信息,进一步提升生成内容的视觉质量与清晰度。
三、模型参数与测试结果:数据验证性能优势
1. 已开源模型:适配不同分辨率需求
CineScale目前已在Hugging Face开源多款模型,覆盖不同任务与分辨率需求,开发者可根据硬件条件选择:
| 模型名称 | 任务类型 | 调优分辨率 | 支持推理分辨率 | 硬件要求 | 说明 |
|---|---|---|---|---|---|
| CineScale-1.3B-T2V | 文本到视频(T2V) | 1088×1920 | 3K(1632×2880) | A100 × 1 | 轻量级模型,适合入门级高分辨率视频生成 |
| CineScale-14B-T2V | 文本到视频(T2V) | 1088×1920 | 4K(2176×3840) | A100 × 8 | 大参数模型,4K视频生成效果更优 |
| CineScale-14B-I2V | 图像到视频(I2V) | 1088×1920 | 4K(2176×3840) | A100 × 8 | 专注I2V任务,支持从静态图生成4K动态视频 |
研究团队建议,将上述模型与Wan2.1/2.2模型搭配使用,可进一步提升高分辨率生成的细节丰富度与风格一致性。
2. 测试结果:多维度指标领先现有方法
通过在图像、视频生成场景的权威基准测试,CineScale的性能优势得到充分验证:
(1)图像生成:高分辨率下指标全面领先
在2048×2048、4096×4096分辨率测试中,CineScale在FID(弗雷歇 inception 距离,越低表示生成质量越接近真实)、KID(核 inception 距离,越低越好)、IS(inception 分数,越高表示多样性与质量越好)等核心指标上,均超过现有高分辨率生成方法(如SR3、ProPainter)。例如在4096×4096分辨率下,CineScale的FID值比第二名低12%,意味着生成图像与真实高分辨率图像的差异更小。
(2)视频生成:兼顾质量与流畅性
在960×1664、1920×3328分辨率视频测试中,CineScale在FVD(弗雷歇视频距离,衡量视频质量与流畅性)、动态程度、审美质量评分上表现突出:
- FVD值比现有方法低15%,视频帧间连贯性更强;
- 动态程度评分高8%,生成的运动场景(如水流、人物动作)更自然;
- 审美质量评分领先10%,视觉效果更符合人类主观感受。
(3)用户研究:满意度最高
在针对100名专业设计师、影视从业者的用户调研中,CineScale生成的8K图像、4K视频在“细节丰富度”“整体协调性”“语义一致性”三个维度的评分均排名第一,78%的受访者表示“愿意在实际项目中使用CineScale替代现有高分辨率生成工具”。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...