对于研究人员来说,将一篇论文转化为一场高质量的学术演示视频,往往意味着数小时的设计、录制与剪辑——即使最终视频只有5到10分钟。
幻灯片排版、语音同步、字幕对齐、讲解节奏控制……这些重复性工作消耗大量精力,却与核心科研无关。
为解决这一痛点,新加坡国立大学 Show Lab 推出 PaperTalker——全球首个面向学术演示视频生成的多智能体自动化框架。它能直接输入一篇PDF格式的研究论文,输出一段包含幻灯片、语音、字幕、数字主讲人和鼠标指针的完整演讲视频。
- 项目主页:https://showlab.github.io/Paper2Video
- GitHub:https://github.com/showlab/Paper2Video
- 数据:https://huggingface.co/datasets/ZaynZhu/Paper2Video
与此同时,团队还发布了配套基准数据集 Paper2Video,为该领域建立首个可衡量标准。这不仅是效率工具的升级,更是学术传播方式的一次结构性革新。

背景:为什么需要自动化学术视频生成?
随着 NeurIPS、ICML 等顶会全面推行“必交视频”政策,越来越多研究者必须为每篇投稿准备3–10分钟的讲解视频。
但当前流程高度依赖人工:
- 手动设计PPT或LaTeX Beamer幻灯片;
- 录制配音并调整语速;
- 添加字幕、动画与视觉引导;
- 合成主讲人画面(如有);
整个过程耗时通常超过5小时,且质量受个人技能影响大。
更关键的是,现有视频生成方法难以应对学术内容的独特挑战:
- 输入是长文本+图表+公式的复合文档;
- 输出需协调幻灯片、语音、字幕、光标、主讲人五重模态;
- 核心目标不是“好看”,而是“准确传达科学思想”。
为此,Show Lab 提出了一套完整的解决方案:数据集 + 框架 + 评估体系。
Paper2Video:首个学术演示视频基准数据集
要训练和评估自动化系统,首先需要真实、高质量的数据。
团队构建了 Paper2Video——一个包含 101篇研究论文及其作者制作的官方演示视频 的公开数据集,涵盖计算机视觉、自然语言处理、机器人等多个领域。
每项数据包括:
- 原始论文(平均1.33万词)
- 作者使用的幻灯片(平均28.7页,含44.7张图表)
- 实际录制的演示视频(平均6分15秒,最长14分钟)
- 主讲人元数据(肖像、语音样本等)
这个数据集的价值在于:它提供了从“论文 → 视频”的真实映射路径,成为后续模型训练与评估的基础。
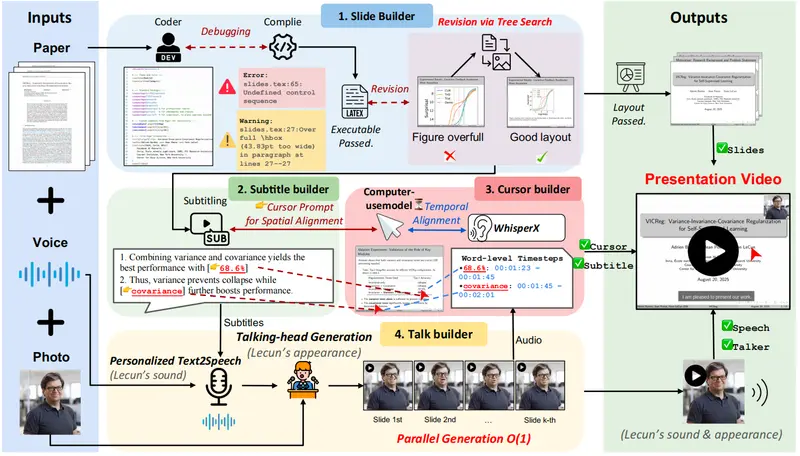
PaperTalker:四智能体协同的自动化生成框架
PaperTalker 不是一个单一模型,而是一个由四个专业化“构建器”组成的多智能体协作系统,各司其职、并行推进。
✅ 幻灯片构建器
输入论文后,自动生成 LaTeX Beamer 代码,并通过编译反馈迭代优化布局与语法。
创新点:引入 树搜索视觉选择(Tree Search Visual Choice),在多个候选排版方案中选择最符合学术审美的布局。
✅ 字幕构建器
结合视觉语言模型分析幻灯片内容,生成逐句讲解文本,并标注句子级视觉焦点区域(如某图表、某公式),用于后续光标定位。
✅ 光标构建器
将视觉焦点提示转换为屏幕坐标轨迹,生成自然的鼠标移动路径,并与语音时间轴精确对齐,增强观众注意力引导。
✅ 讲述人构建器
利用主讲人的照片与语音样本,通过 TTS 和数字人技术生成个性化讲解视频,保留面部特征与说话风格,提升可信度与归属感。
所有模块采用逐页并行生成策略,显著提升效率——相比传统串行流程,速度提升 6倍以上。
最终,系统将五大元素(幻灯片、语音、字幕、光标、主讲人)合成为统一视频流,实现端到端自动化。
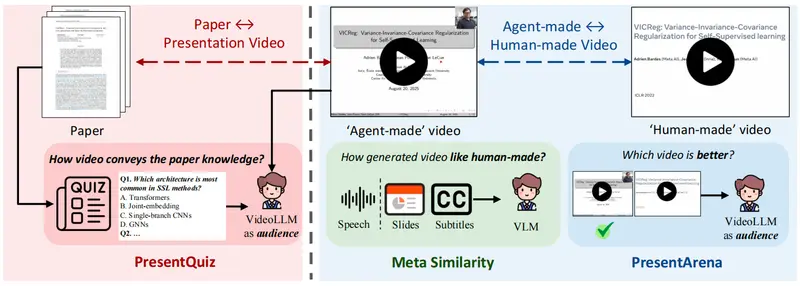
如何评估?四项定制化指标衡量“传播效能”
学术视频的质量不能仅看“像不像真人”,更要评估“是否有效传递知识”。
因此,团队提出四个专为学术场景设计的评估维度:
| 指标 | 说明 |
|---|---|
| Meta Similarity | 衡量生成视频在幻灯片、语音、字幕等方面与原作的相似程度 |
| PresentArena | 通过A/B测试比较不同方法生成视频的整体质量偏好 |
| PresentQuiz | 观众观看后回答预设问题,评估信息覆盖与理解度 |
| IP Memory | 测试观众能否记住作者身份与论文贡献,反映影响力潜力 |
这些指标共同构成一个“以传播效果为中心”的评价体系,超越传统视频生成中的FVD、CLIP-Score等通用指标。
实验结果:接近人类水平的信息传达能力
在 Paper2Video 数据集上的测试表明:
- Meta Similarity:PaperTalker 显著优于现有基线,最接近人类制作视频;
- PresentArena:在对比实验中胜率最高,整体质量领先;
- PresentQuiz:信息准确率排名第一,证明其讲解更具完整性;
- IP Memory:观众记忆作者与工作的概率显著更高;
- 人类评估:生成视频得分仅次于真实人类录制视频,在流畅性与专业性上获得认可。
这意味着,PaperTalker 不仅能“做出来”,更能“讲明白”。
对科研社区的意义
🎯 对研究者
- 大幅降低视频制作门槛;
- 可快速生成会议投稿视频、课程材料、项目汇报等内容;
- 支持非英语母语者生成高质量英文讲解,减少语言障碍。
🔬 对AI社区
- 首次系统性定义“学术演示生成”任务;
- 提供可复现数据集与评估协议;
- 展示多智能体架构在复杂跨模态任务中的潜力。
🚀 未来方向
团队计划开源模型与数据集,并探索:
- 更灵活的风格定制(如教学型 vs 汇报型);
- 多语言支持;
- 与会议平台集成,实现一键提交视频摘要。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...