
尽管当前文生视频模型在短片段合成上取得进展,但在生成结构严谨、知识准确、视觉连贯的教育视频方面仍面临挑战。这类内容不仅要求语义正确,还需具备清晰的空间布局、逻辑动画过渡和教学节奏控制。
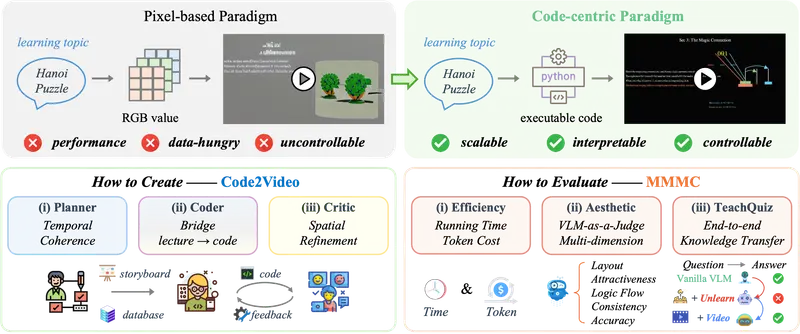
为此,新加坡国立大学 Show Lab 提出 Code2Video ——一个以可执行代码为核心媒介的教育视频生成框架。它不依赖像素级扩散模型,而是通过 Python 代码操控 Manim(数学动画引擎)环境,实现对视频时间线与空间结构的精确控制。
该框架由三个协同工作的 AI 智能体组成:
- 规划器(Planner):将学习主题分解为结构化故事板;
- 编码器(Coder):生成并优化可运行的 Manim 代码;
- 评审器(Critic):利用多模态反馈迭代改进视觉呈现。
整个流程强调可控性、可解释性与可复现性,为自动化教育内容生产提供了新范式。

为什么用代码?从“黑盒生成”到“白盒构建”
传统文生视频模型(如 Veo、Sora)通常采用端到端方式,直接从文本提示生成像素序列。这种方式难以保证:
- 动画逻辑是否符合学科原理;
- 公式推导步骤是否完整无误;
- 视觉元素布局是否利于理解。
而 Code2Video 的核心理念是:
教育视频的本质不是“画面”,而是“过程描述”——这正是代码最擅长表达的内容。
通过输出 Manim 脚本,系统不仅能渲染出高质量动画,还能确保每一步都有明确的逻辑依据,支持人工审查、调试和二次编辑。
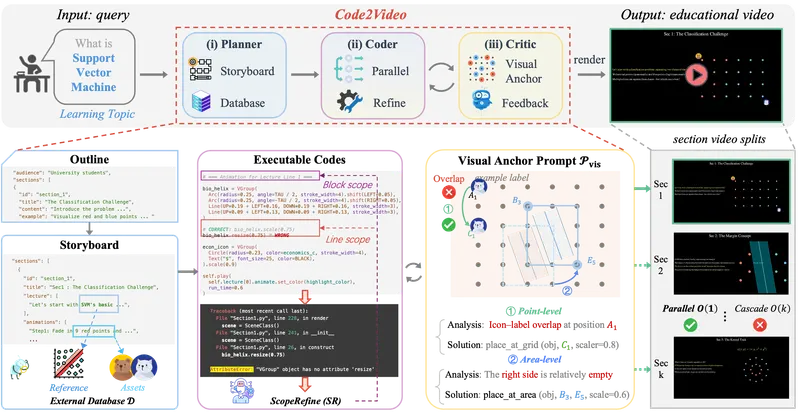
三智能体协作机制
1. 规划器(Planner)
输入一个学习主题(如“傅里叶变换”),规划器负责:
- 将知识点拆解为时间有序的教学段落;
- 设计每个环节的视觉目标(例如公式出现顺序、图形演变过程);
- 从外部数据库检索相关素材(符号、图表模板等);
输出为结构化的教学剧本,作为后续编码的基础。
2. 编码器(Coder)
将教学剧本转换为可执行的 Manim 代码,并引入两项关键技术提升效率:
- 并行代码合成:多个模块同时生成不同部分代码;
- 范围引导的自动修复:当代码报错或不符合预期时,仅针对问题区域进行局部修正,而非整体重写。
相比逐行试错的传统方法,大幅缩短生成周期。
3. 评审器(Critic)
使用视觉-语言模型(VLM)对初步生成的视频帧进行评估,重点关注:
- 空间布局合理性(如公式与图示的位置关系);
- 文字可读性与标注清晰度;
- 是否存在歧义或误导性表达;
并通过锚点视觉提示(anchor visual cues)指导编码器调整代码,实现闭环优化。
MMMC 基准:首个面向教育视频生成的评测体系
为了系统评估此类系统的性能,团队构建了 MMMC 基准数据集(Multimodal Math & Science Content),包含:
- 117 个精选学习主题;
- 覆盖数学、物理、计算机科学等领域;
- 灵感来源于 3Blue1Brown 等优质教育频道;
- 所有视频均为专业制作,用于对比生成质量。
评估维度包括:
| 维度 | 方法 |
|---|---|
| 美学与结构质量 | 使用 VLM-as-a-Judge 打分(满分100) |
| 代码效率 | 生成耗时、调试轮次、资源消耗 |
| 知识传递效果 | 新指标 TeachQuiz:训练另一个 VLM 从生成视频中学习并回答问题,衡量信息传达有效性 |
这一评估体系突破了传统“人类主观打分”的局限,更贴近真实教学目标。
实验结果摘要
| 指标 | Code2Video | 像素级模型(如 Veo3) |
|---|---|---|
| 平均生成时间 | 15.4 分钟 | 86.6 分钟(直接代码生成基线) |
| VLM美学评分 | 79.0 | 12.6 |
| TeachQuiz得分 | 82.0 | 6.0 |
| 人类学生TeachQuiz得分 | 88.1(中学群体) | — |
值得注意的是,在针对初中学生的测试中,观看 Code2Video 生成视频的学生答题正确率甚至高于观看人类制作视频的对照组,显示出其在特定场景下的教学潜力。
应用前景
Code2Video 并非旨在取代教师或专业视频团队,而是为以下场景提供支持工具:
- ✅ 在线教育平台:快速生成标准化课程片段;
- ✅ 个性化辅导系统:根据学生进度动态生成讲解视频;
- ✅ 教师辅助创作:自动生成复杂动画草稿,节省备课时间;
- ✅ 开放教育资源(OER)建设:低成本复制高质量教学内容。
更重要的是,其代码驱动特性使得全球开发者可以共享、修改和扩展脚本库,推动教育资源的开源共建。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











