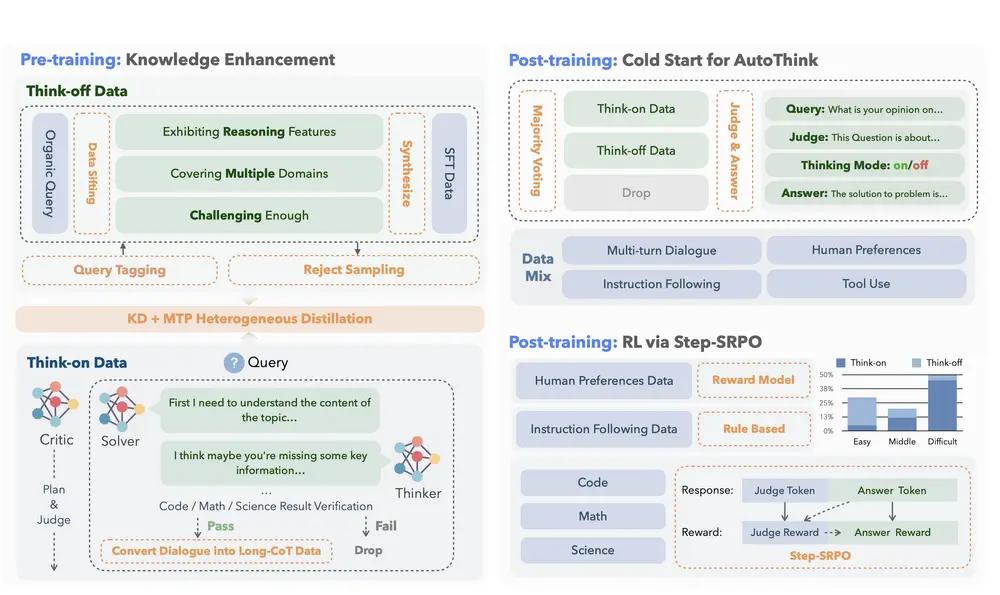
美团LongCat 团队近日开源了 LongCat-Flash-Lite —— 一款拥有 685 亿总参数、激活参数约 30 亿 的混合专家(MoE)语言模型。它基于 LongCat-Flash 架构,但引入了一项关键创新:N-gram 嵌入表(N-gram Embedding Table),在不显著增加激活计算量的前提下,显著提升了模型在智能体任务和编程场景中的表现。
该模型支持 256K 上下文长度(通过 YaRN 扩展),并在多项基准测试中超越同规模 MoE 模型,尤其在工具调用与代码生成方面表现突出。
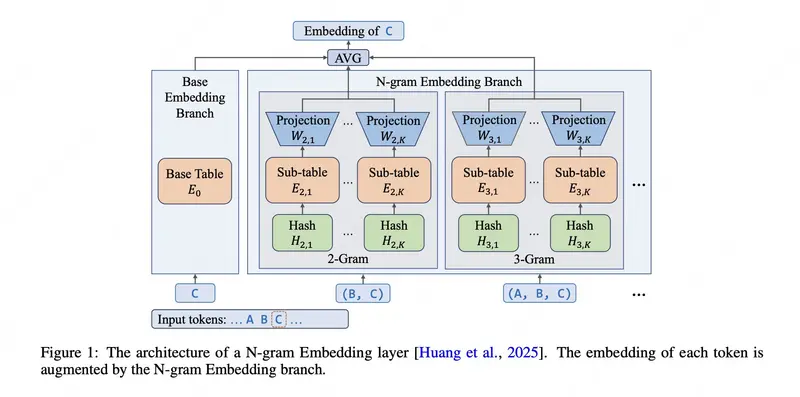
核心创新:N-gram 嵌入表,MoE 的高效扩展新路径
传统 MoE 模型通过增加专家数量来提升容量,但会带来显著的 I/O 开销和推理延迟。LongCat-Flash-Lite 提出了一种替代方案:将部分参数分配给一个大型 N-gram 嵌入表(超过 300 亿参数),用于显式建模高频词序列的语义。
这一设计带来三重优势:
- 更优的扩展效率
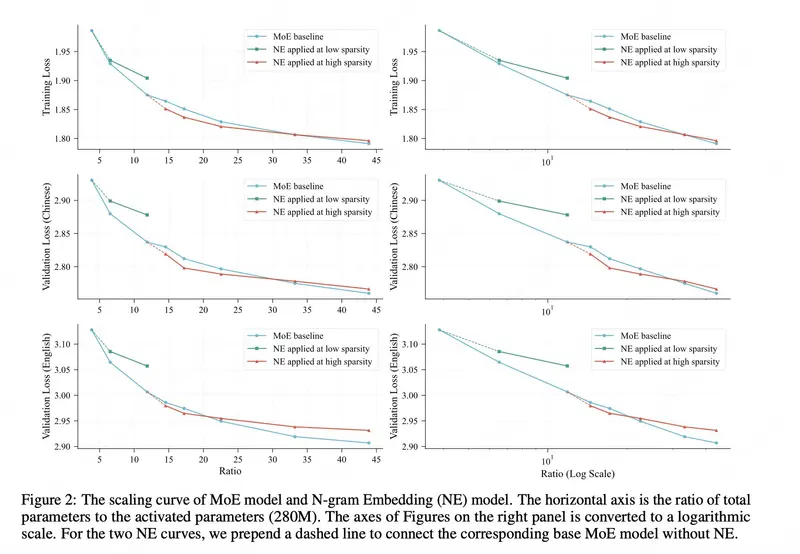
实验表明,在特定配置下,扩展嵌入表比增加专家数量能实现更好的性能-成本帕累托前沿。团队系统分析了影响其有效性的关键因素,包括嵌入初始化、哈希冲突缓解、参数分配比例等。 - 更低的推理延迟
N-gram 嵌入表以查表方式工作,避免了 MoE 专家层中频繁的权重加载与路由开销。配合专用的 N-gram 缓存 和 同步内核优化,推理速度显著提升。 - 更强的任务能力
尽管激活参数仅约 30 亿,LongCat-Flash-Lite 在智能体工具使用和编程任务上大幅领先同规模模型,证明了嵌入表对上下文理解和结构化输出的有效增强。
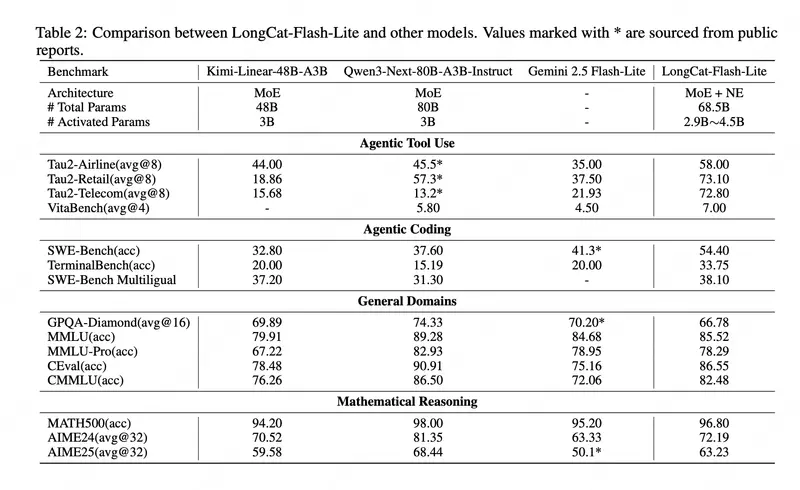
性能表现:智能体与编程领域全面领先
在权威基准测试中,LongCat-Flash-Lite 展现出极强的竞争力:
| 任务 | LongCat-Flash-Lite | Qwen3-Next-80B | Kimi-Linear-48B |
|---|---|---|---|
| Tau2-Airline(工具调用) | 58.00 | 45.5* | 44.00 |
| Tau2-Retail | 73.10 | 57.3* | 18.86 |
| SWE-Bench(代码修复) | 54.40 | 37.60 | 32.80 |
| TerminalBench | 33.75 | 15.19 | 20.00 |
| PRDBench | 39.63 | 15.36 | - |
注:带 * 数据来自公开报告
在通用能力(如 MMLU、CEval)和数学推理(MATH500)上,也达到或接近当前主流大模型水平,验证了其多功能性与高性价比。
使用要求与部署
由于模型规模较大,LongCat-Flash-Lite 对硬件有一定要求:
- 至少 2 张 80GB 显存 GPU(如 A100/H100)
- Python ≥ 3.10
- PyTorch ≥ 2.6
- Transformers ≥ 4.57.6
安装依赖:
pip install -U transformers==4.57.6 accelerate==1.10.0
完整技术细节请参阅官方技术报告。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











