在小型语言模型(SLM)加速落地的趋势下,以色列AI公司 AI21 Labs 推出其最新力作——Jamba Reasoning 3B。
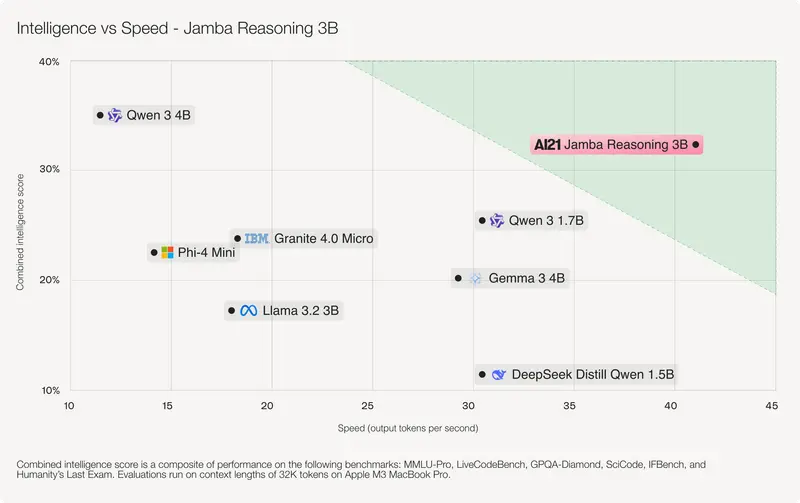
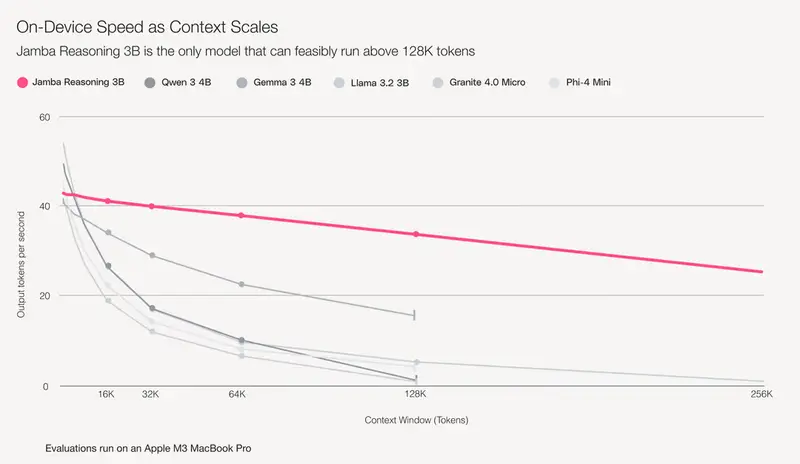
这是一款专为设备端推理设计的开源模型,仅含 30亿参数,却支持高达 250,000 tokens 的上下文窗口,并能在标准 MacBook Pro 上以每秒约35个token的速度完成推理。
为什么需要更小的模型?数据中心已不堪重负
AI21 联合CEO Ori Goshen 指出,当前AI基础设施面临一个根本性的经济问题:
数据中心建设成本高昂,而收入增长难以覆盖芯片折旧与能耗开销。
他预测,未来计算将走向混合模式:
- 简单任务 → 在本地设备(手机、笔记本)上处理;
- 复杂推理 → 交由云端GPU集群执行。
这种分流不仅能降低延迟、提升隐私,还能显著缓解数据中心压力。
“我们相信,保留在设备上的模型,将在个性化体验优化中扮演关键角色。”Goshen 表示。
技术突破:Mamba + Transformer 混合架构
Jamba Reasoning 3B的核心创新在于其混合神经网络架构——结合了 Mamba 的序列建模效率 与 Transformer 的表达能力。
| 架构组件 | 作用 |
|---|---|
| Mamba | 处理长序列时具有线性计算复杂度,显著降低内存占用 |
| Transformer 层 | 保留对复杂语义关系的理解能力 |
这一组合使得模型在保持轻量的同时,仍能高效处理超长上下文任务,如:
- 分析整本技术文档
- 解析大型代码库
- 连续对话记忆追溯
AI21 表示,相比纯Transformer模型,该架构实现了 2–4倍的推理速度提升,同时大幅减少显存需求。
实测表现:MacBook 上流畅运行 25万 token
在标准配置的 MacBook Pro(M1/M2芯片) 上测试显示:
- Jamba Reasoning 3B 可稳定加载并处理 250K tokens 上下文
- 推理速度达到 ~35 tokens/秒
这意味着用户可以在离线状态下,用本地设备完成原本必须依赖云服务的长文本分析任务。
例如:
- 输入一份包含数万行代码的日志文件;
- 提问:“最近一次崩溃是由哪个函数引起的?”
- 模型直接在设备上检索相关信息并生成回答,无需上传任何数据。
定位明确:面向企业级实用场景
Jamba Reasoning 3B 并非用于闲聊或内容创作,而是专注于三类高价值企业任务:
- 函数调用与工具路由
自动识别用户意图,并调用内部API或工作流工具。 - 基于策略的内容生成
在合规框架内生成邮件、报告、合同条款等结构化输出。 - 本地化决策支持
如金融顾问应用根据客户资料生成投资建议,全程数据不出设备。
Goshen 强调:“它比大多数小型模型更小,但在推理任务上不牺牲速度。”
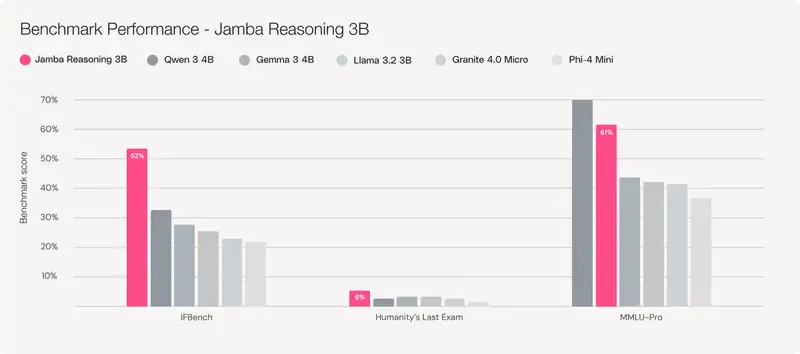
基准测试:多项指标领先同类模型
在多个权威基准测试中,Jamba Reasoning 3B 表现优异:
| 基准 | 表现 |
|---|---|
| IFBench | 超越 Qwen-4B、Llama-3.2B、Phi-4-Mini |
| Humanity’s Last Exam | 同样排名第一 |
| MMLU-Pro | 排名第二,仅次于 Qwen-4B |
这些结果表明,尽管参数规模仅为3B,Jamba Reasoning 3B在推理能力和知识覆盖方面已达到甚至超过部分更大模型的水平。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











