
今天下午,阿里并未进行大规模宣传,而是在其官方对话页面chat.qwen.ai上低调上线了Qwen3.5系列的两款全新大语言模型——Qwen3.5-Plus与Qwen3.5-397B-A17B。
- 项目主页:https://qwen.ai/blog?id=qwen3.5
- GitHub:https://github.com/QwenLM/Qwen3.5
- Qwen Code: https://github.com/QwenLM/qwen-code
- Hugging Face: https://huggingface.co/collections/Qwen/qwen35
- ModelScope: https://modelscope.cn/collections/Qwen/Qwen35
这两款模型虽定位不同,却共同承载着Qwen3.5系列底层架构全面革新的核心成果,均全面支持文本与多模态任务,分别面向闭源服务与开源开发两大场景,旨在为不同需求的用户与企业提供更高效、更强大的AI能力支撑。

双旗舰定位清晰,精准覆盖两大核心场景
作为Qwen3.5系列的首款公开产品,两款新模型有着清晰的定位区分,精准覆盖不同用户群体的核心需求。其中,Qwen3.5-Plus定位为Qwen3.5系列的最新闭源大语言模型,主要以API服务的形式通过阿里云百炼平台向用户提供支持,其核心优势在于拥有1M token的超大上下文窗口,能够轻松处理超长文本交互、复杂文档分析等场景,同时内置官方工具链与自适应调用能力,用户只需传入相应参数,即可开启深度推理、联网搜索、代码解释器等高级功能,大幅提升复杂任务的处理效率。
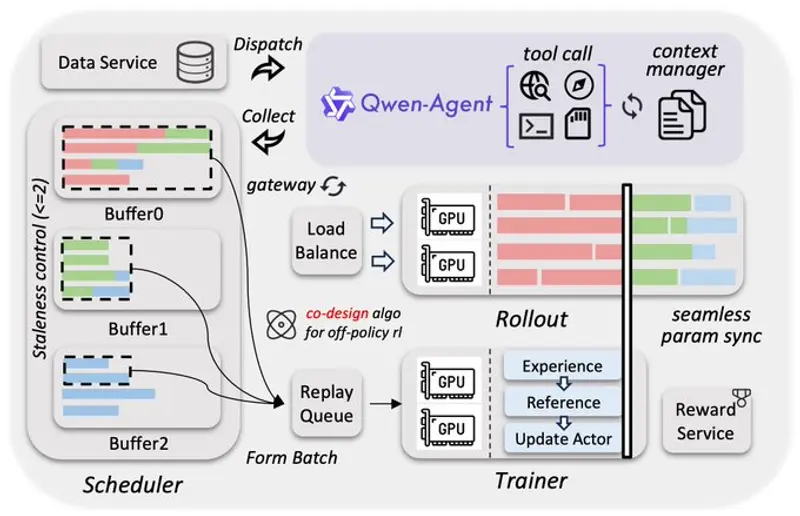
而Qwen3.5-397B-A17B则定位为Qwen3.5开源系列的旗舰大语言模型,不仅开放权重供开发者使用,更在架构设计上实现了重大突破。该模型采用创新的混合架构,将Gated Delta Networks线性注意力与稀疏混合专家(MoE)技术相结合,打造出“大参数量、小激活量”的高效运行模式——其总参数量高达3970亿,却在每次前向传播过程中仅激活170亿参数,这种设计既保证了模型的顶尖能力,又极大地优化了运行速度与硬件成本,让更多开发者能够在普通硬件环境中部署和使用高性能大模型。与此同时,该模型的语言与方言支持范围也实现了大幅扩展,从原有Qwen3系列的119种提升至201种,词表规模也从15万扩容至25万,仅这一项优化就使得多数语言的编码与解码效率提升了10%至60%,进一步增强了模型的全球通用性。
性能跨越式提升,多项评测超越国际一线
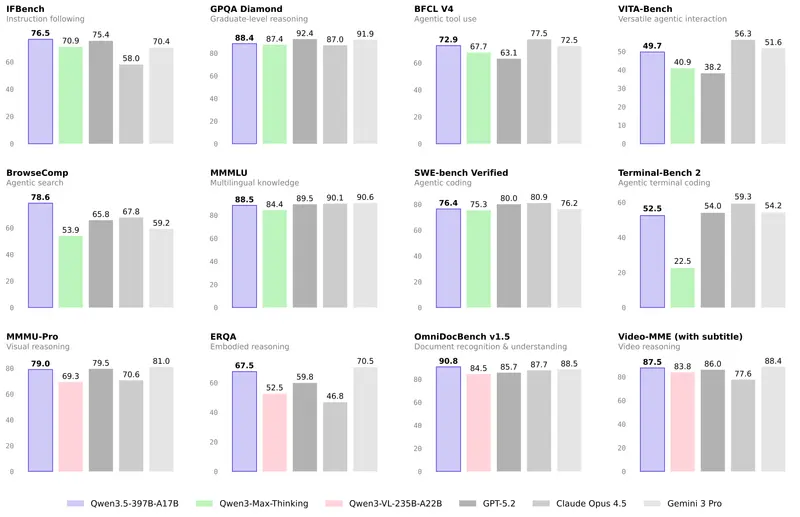
除了架构与设计上的革新,Qwen3.5系列在性能表现上更是实现了跨越式提升,多项权威评测成绩超越国际一线大模型,展现出强劲的综合实力。根据阿里官方披露的信息,Qwen3.5在MMLU-Pro认知能力评测中斩获87.8分,成功超越GPT-5.2;在考验博士级知识与推理能力的GPQA测评中,其88.4分的成绩也高于Claude 4.5;而在指令遵循能力评测IFBench中,76.5分的成绩更是刷新了所有模型的纪录,充分证明了其对用户指令的精准理解与高效执行能力。不仅如此,在通用Agent评测BFCL-V4、搜索Agent评测Browsecomp等基准测试中,Qwen3.5的表现也全面超越Gemini 3 Pro,在智能体领域展现出突出优势。值得一提的是,作为开源旗舰的Qwen3.5-397B-A17B,其综合能力已经能够与参数量超过1万亿的Qwen3-Max-Base相媲美,真正实现了“小激活、大性能”的代际突破,打破了“参数量决定性能”的固有认知。
效率爆发式增长,实现“强性能+低成本”双赢
效率的全面提升是Qwen3.5系列的另一大核心亮点,该系列基于全新的Qwen3-Next架构打造,通过更高稀疏度的MoE结构、Gated DeltaNet与Gated Attention相结合的混合注意力机制,再加上稳定性优化与多token预测等技术,实现了推理效率的爆发式增长。从实测数据来看,Qwen3.5-397B-A17B在32k上下文长度下的解码吞吐量是Qwen3-Max的8.6倍,在256k长上下文长度下更是达到了19.0倍,即便与Qwen3-235B-A22B相比,其32k与256k上下文长度下的解码吞吐量也分别提升了3.5倍与7.2倍。而闭源版本的Qwen3.5-Plus相比万亿参数的Qwen3-Max,不仅部署显存占用降低了60%,最大推理吞吐量更是最高提升至19倍,真正做到了“性能更强、跑得更快、用得更省”,大幅降低了企业与开发者的部署成本和使用门槛。
预训练三维优化,筑牢模型核心竞争力
Qwen3.5系列的这些突破,离不开其在预训练阶段围绕能力、效率、通用性三大核心维度的持续深耕与优化。在能力提升方面,Qwen3.5在更大规模的视觉-文本语料上进行训练,同时重点加强了中英文、多语言、STEM领域以及逻辑推理相关的数据储备,并采用了更严格的数据过滤机制,确保训练数据的高质量,最终实现了跨代持平的优异表现,让397B总参、17B激活的版本能够达到万亿参数模型的能力水平。在效率优化方面,除了架构上的创新,其通过激活参数的精准控制,大幅降低了推理过程中的硬件资源消耗,尤其是在长上下文场景下的效率提升,让大模型能够更好地适配复杂业务场景。而在通用性方面,Qwen3.5通过早期文本-视觉融合技术与扩展的视觉、STEM、视频数据,实现了原生多模态能力,在相近规模下其多模态表现优于Qwen3-VL;多语言覆盖范围的扩展与词表的扩容,则进一步提升了模型的全球适用性,让不同地区、不同语言的用户都能获得良好的使用体验。
底层基建强力支撑,解锁训推高效协同
这些亮眼的成绩背后,离不开阿里云底层基础设施的强力支撑。为了高效支撑Qwen3.5系列的训练与推理,阿里云打造了异构并行训练体系,将视觉与语言组件进行解耦并行设计,避免了统一方案带来的低效问题,使得在混合文本-图像-视频数据上的训练吞吐接近100%。同时,原生FP8流水线技术对激活、MoE路由与GEMM运算采用低精度处理,并通过运行时监控在敏感层保持BF16精度,既实现了约50%的激活显存降低,又带来了超过10%的速度提升,且能够稳定扩展至数万亿token的训练规模。此外,为了持续释放强化学习的潜力,阿里云构建了可扩展的异步强化学习框架,全面支持Qwen3.5全尺寸模型,覆盖文本、多模态及多轮交互等各类场景。该框架采用训推分离的解耦式设计,显著提升了硬件利用率,实现了动态负载均衡和细粒度的故障恢复,再配合FP8训推、Rollout路由回放、投机采样以及多轮Rollout锁定等技术,进一步优化了系统吞吐,提高了训推一致性。这种系统与算法的协同设计,在严格控制样本陈旧性的基础上有效缓解了数据长尾问题,提升了训练曲线的稳定性和性能上限,同时面向原生智能体工作流设计,能够实现稳定、无缝的多轮环境交互,消除框架层的调度中断,可扩展至百万级规模的Agent脚手架与环境,最终实现了3×至5×的端到端加速,展现出卓越的稳定性、高效率与可扩展性。
双入口可直接体验,兼顾普通用户与开发者
目前,用户已经可以通过两大入口快速体验Qwen3.5系列模型的强大能力。其中,普通用户可以直接访问chat.qwen.ai网页端,无需复杂配置即可与Qwen3.5进行交互,该页面提供了自动、思考、快速三种模式供用户选择,自动模式下用户可使用自适应思考,并调用搜索、代码解释器等工具;思考模式适合处理复杂难题,模型会进行深度推理分析;快速模式则适合简单问题咨询,模型将直接给出答案,不消耗思考token,兼顾了不同场景下的使用需求。而对于有开发需求或企业用户来说,可以通过阿里云百炼平台调用Qwen3.5-Plus的API服务,若想开启推理、联网搜索与Code Interpreter等高级能力,只需传入enable_thinking和enable_search两个参数即可。同时,该API还可与Qwen Code、Claude Code、Cline、OpenClaw、OpenCode等第三方编程工具无缝集成,为开发者带来流畅的“vibe coding”体验,助力企业与开发者显著提升生产力。
战略转型:从“做大模型”到“做智能体系统”
阿里云在此次发布中明确表示,Qwen3.5凭借高效的混合架构与原生多模态推理能力,已经为通用数字智能体奠定了坚实的基础,而下一阶段的发展重点将从“做大模型”转向“做智能体系统”,实现从模型规模到系统整合的战略转型。未来,阿里云将重点构建具备跨会话持久记忆的智能体,打造面向真实世界交互的具身接口,并研发模型自我改进机制,其最终目标是打造出能够长期自主运行、逻辑一致的智能系统,将当前以任务为边界的AI助手,升级为可持续、可信任的智能伙伴,为各行各业的数字化转型提供更加强大、更加灵活的AI支撑。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











