一个仅含 700万参数 的神经网络,如何在性能上匹敌甚至超过参数量高达其 10,000倍 的大语言模型?
这不是理论设想,而是现实。
三星先进技术研究院(SAIT)蒙特利尔分部的高级AI研究员 Alexia Jolicoeur-Martineau 最近发布了名为 Tiny Recursion Model(TRM) 的新模型——一种专为结构化推理设计的小型生成式网络,在数独、迷宫和ARC-AGI等抽象推理基准测试中,表现优于 Gemini 2.5 Pro、o3-mini 等顶级闭源模型。
- 项目主页:https://alexiajm.github.io/2025/09/29/tiny_recursive_models.html
- GitHub:https://github.com/SamsungSAILMontreal/TinyRecursiveModels
更重要的是:它完全开源,采用商业友好的 MIT 许可证,代码已在 GitHub 公开。
小模型为何能赢?递归取代规模
当前主流AI发展路径高度依赖“更大即更强”:通过增加参数、算力和数据量来提升能力。但 TRM 提出了另一种可能:
少即是多(Less is More)
TRM 的核心思想是:用递归推理替代模型深度与参数规模。
具体来说,该模型不靠庞大的层数或注意力机制堆叠能力,而是通过在一个轻量级两层网络上反复迭代、自我修正答案,逐步逼近正确解。
这个过程类似于人类面对难题时的“再想想”:
- 给出初步判断;
- 检查错误;
- 调整思路;
- 再次尝试。
TRM 将这一过程形式化为一个递归更新循环,在多达16步内不断优化内部表示和输出结果,而无需引入额外复杂结构。
架构极简:从 HRM 到 TRM 的简化之路
TRM 基于今年早些发布的 Hierarchical Reasoning Model(HRM) 改进而来。HRM 使用两个协同工作的神经网络(高频+低频),并依赖数学上的不动点定理实现稳定收敛。
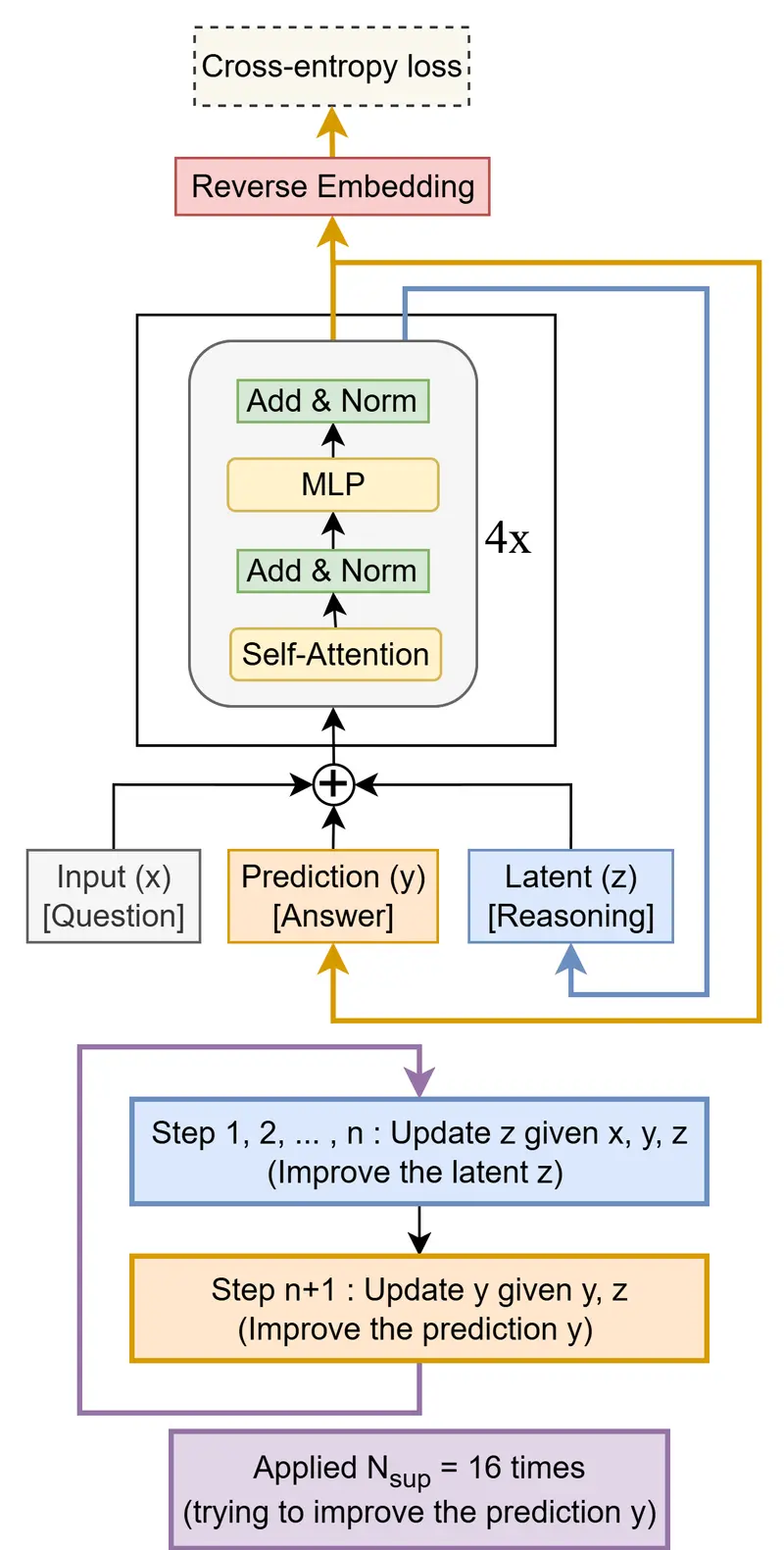
但 Jolicoeur-Martineau 发现,这种设计过于复杂,且难以复现和扩展。
于是她彻底重构:
- ✅ 移除双网络结构
- ✅ 移除不动点逼近机制
- ✅ 替换为单一两层前馈网络
- ✅ 引入递归反馈路径
最终形成的 TRM 架构极为简洁:
- 输入:问题描述 + 初始猜测
- 隐藏状态 z:随每一步更新
- 输出 y:逐步精细化的答案
- 停止机制:判断是否已收敛
整个系统没有自注意力模块(在小网格任务中反而降低性能),也不依赖复杂的生物启发假设,更易理解和部署。
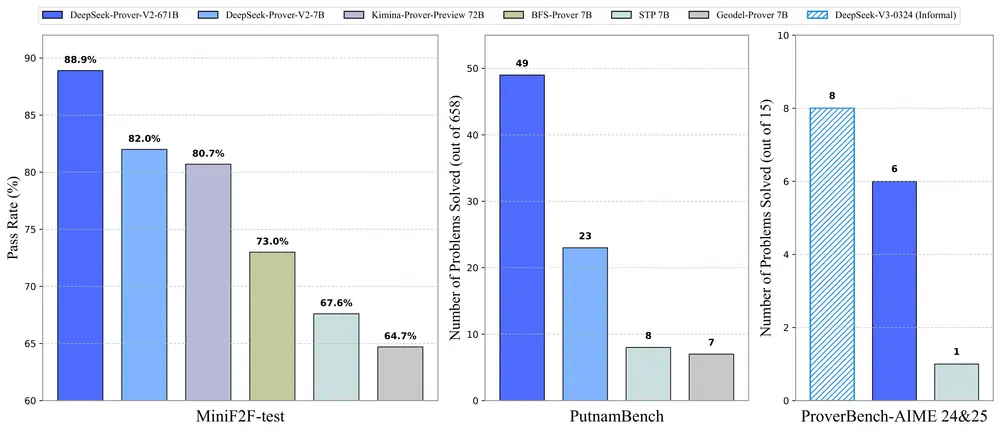
实测表现:小模型跑赢巨头
尽管参数仅为 7M(相比Gemini Pro约70B,不足0.01%),TRM 在多个高难度推理基准上达到甚至超越了大规模模型的表现:
| 任务 | TRM 准确率 | 对比模型表现 |
|---|---|---|
| Sudoku-Extreme | 87.4% | HRM: 55%,LLMs普遍低于80% |
| Maze-Hard | 85% | 接近 o3-mini 与 DeepSeek R1 |
| ARC-AGI-1 | 45% | 匹配 Gemini 2.5 Pro 水平 |
| ARC-AGI-2 | 8% | 在小模型中处于领先 |
这些任务的特点是:输入输出均为结构化网格,规则明确但需组合推理——正是传统LLM容易失败的领域。
TRM 的成功表明:对于这类问题,推理质量不取决于参数多少,而在于能否进行有效的逐步修正。
如何做到高效?训练策略与数据增强
虽然模型本身很小,但其训练方式充分挖掘了数据潜力:
- 大量数据增强:对颜色、位置、旋转等进行变换,扩大有效训练集;
- 深度监督:每一轮递归都提供真实标签,确保中间步骤也可学习;
- 轻量停止机制:动态判断何时终止推理,避免无效计算。
计算资源需求也远低于主流大模型:
- 数独任务可在单张 NVIDIA L40S GPU 上完成训练;
- ARC-AGI 实验使用多H100集群,但仍远低于百亿参数模型的典型开销。
团队强调:“我们的目标不是最小化总FLOPs,而是展示参数效率的新方向。”
设计哲学:匹配问题结构,而非堆砌容量
TRM 的最大启示在于其设计理念:
“模型架构应匹配任务的数据结构与规模。”
研究发现:
- 在固定上下文任务(如数独)中,简单的 MLP 比自注意力更有效;
- 增加层数或参数会导致过拟合;
- 极简结构反而带来更好泛化。
这提醒我们:AI进步不应只是“scaling up”,更要“thinking differently”。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











