
阿里通义团队于两个月前升级了 Qwen2.5-Turbo,使其支持最多一百万个Tokens的上下文长度。1月27日,通义团队正式推出开源的 Qwen2.5-1M 模型及其对应的推理框架支持。以下是本次发布的亮点:
- 开源模型: 通义团队发布了两个新的开源模型,分别是 Qwen2.5-7B-Instruct-1M 和 Qwen2.5-14B-Instruct-1M,这是通义团队首次将开源 Qwen 模型的上下文扩展到 1M 长度。
- 推理框架: 为了帮助开发者更高效地部署 Qwen2.5-1M 系列模型,通义团队完全开源了基于 vLLM 的推理框架,并集成了稀疏注意力方法。该框架在处理 1M 长度输入时的速度能够提升 3倍到7倍。
- 技术报告: 通义团队还分享了 Qwen2.5-1M 系列背后的技术细节,包括训练和推理框架的设计思路以及消融实验的结果。
现在,你可以访问通义团队在 Huggingface 和 Modelscope 上的在线演示来体验 Qwen2.5-1M 模型。另外,通义团队最近也推出了 Qwen Chat ,一个基于 Qwen 系列的 AI 助手。你可以与他对话、编程、生成图像与视频,使用搜索以及调用工具等功能。你也可以在 Qwen Chat 中与使用上下文长度同样为 1M 的 Qwen2.5-Turbo 模型进行长序列处理。
模型性能
首先,让通义团队来看看 Qwen2.5-1M 系列模型在长上下文任务和短文本任务中的性能表现。
长上下文任务
在上下文长度为100万 Tokens 的大海捞针(Passkey Retrieval)任务中,Qwen2.5-1M 系列模型能够准确地从 1M 长度的文档中检索出隐藏信息,其中仅有7B模型出现了少量错误。
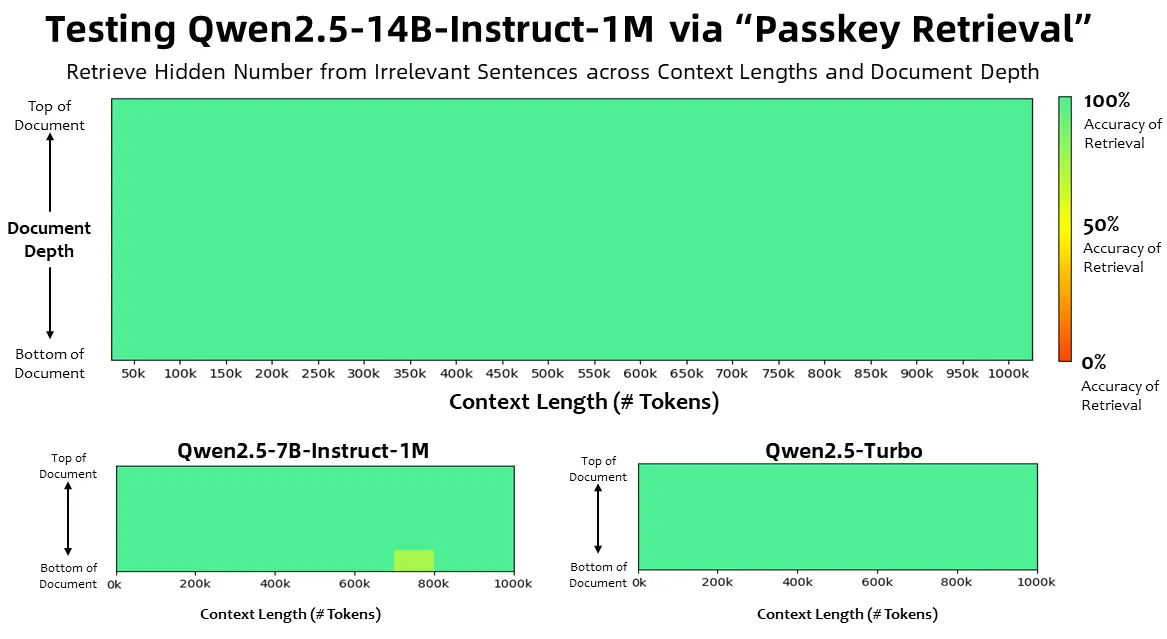
对于更复杂的长上下文理解任务,通义团队选择了RULER、LV-Eval 和 LongbenchChat,这些测试集也在此博客中进行了介绍。
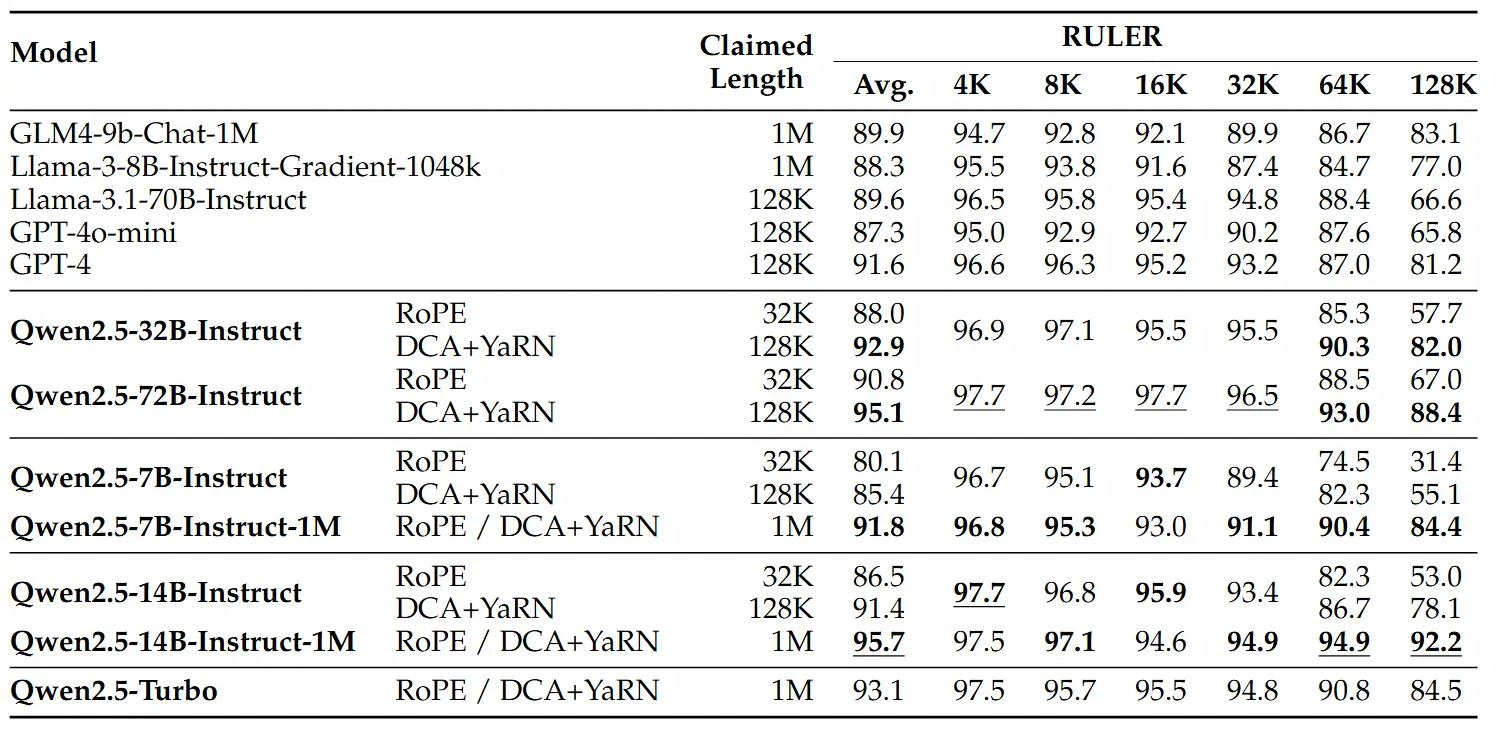
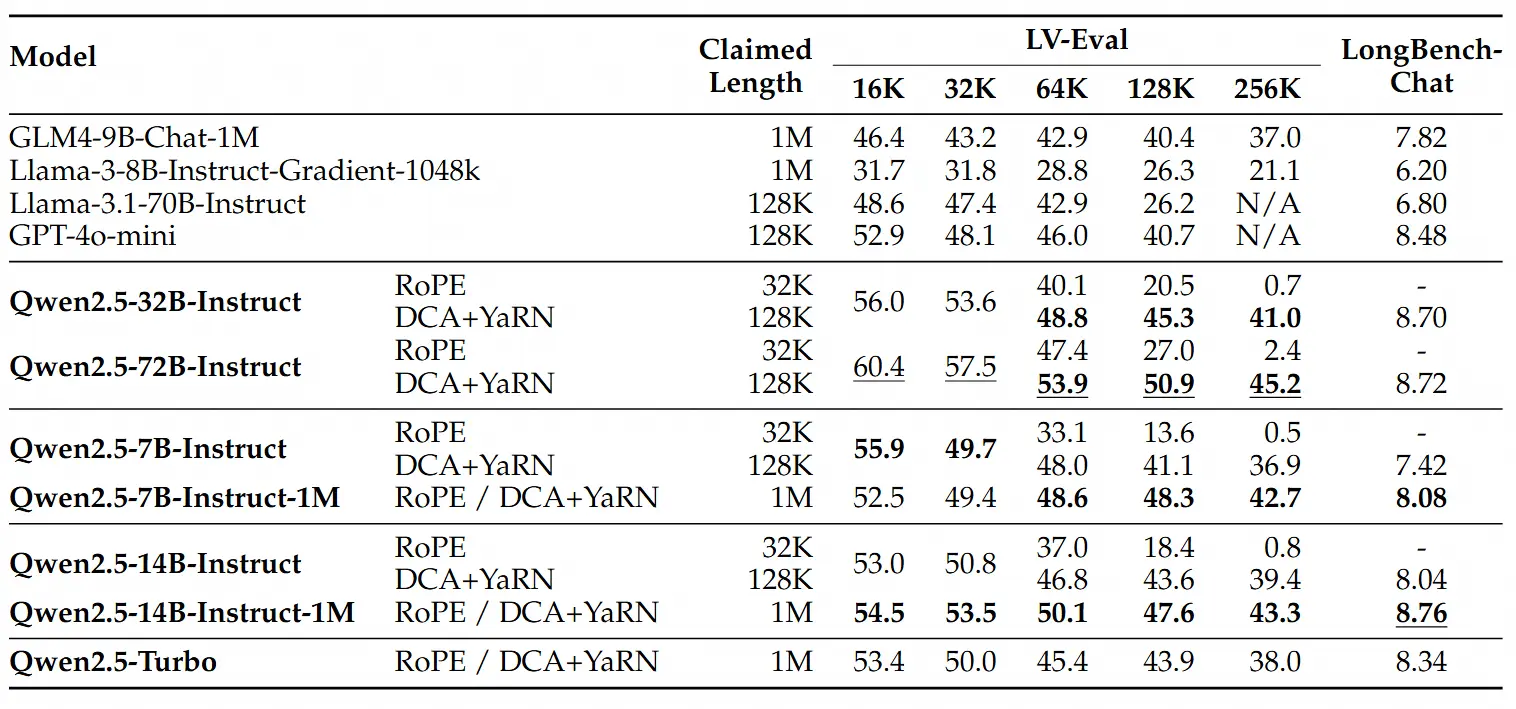
从这些结果中,通义团队可以得出以下几点关键结论:
- 显著超越128K版本:Qwen2.5-1M 系列模型在大多数长上下文任务中显著优于之前的128K版本,特别是在处理超过64K长度的任务时表现出色。
- 性能优势明显:Qwen2.5-14B-Instruct-1M 模型不仅击败了 Qwen2.5-Turbo,还在多个数据集上稳定超越 GPT-4o-mini,因此可以作为现有长上下文模型的优秀开源替代。
短序列任务
除了长序列任务的性能外,通义团队同样关注这些模型在短序列上的表现。通义团队在广泛使用的学术基准测试中比较了 Qwen2.5-1M 系列模型及之前的128K版本,并加入了 GPT-4o-mini 进行对比。
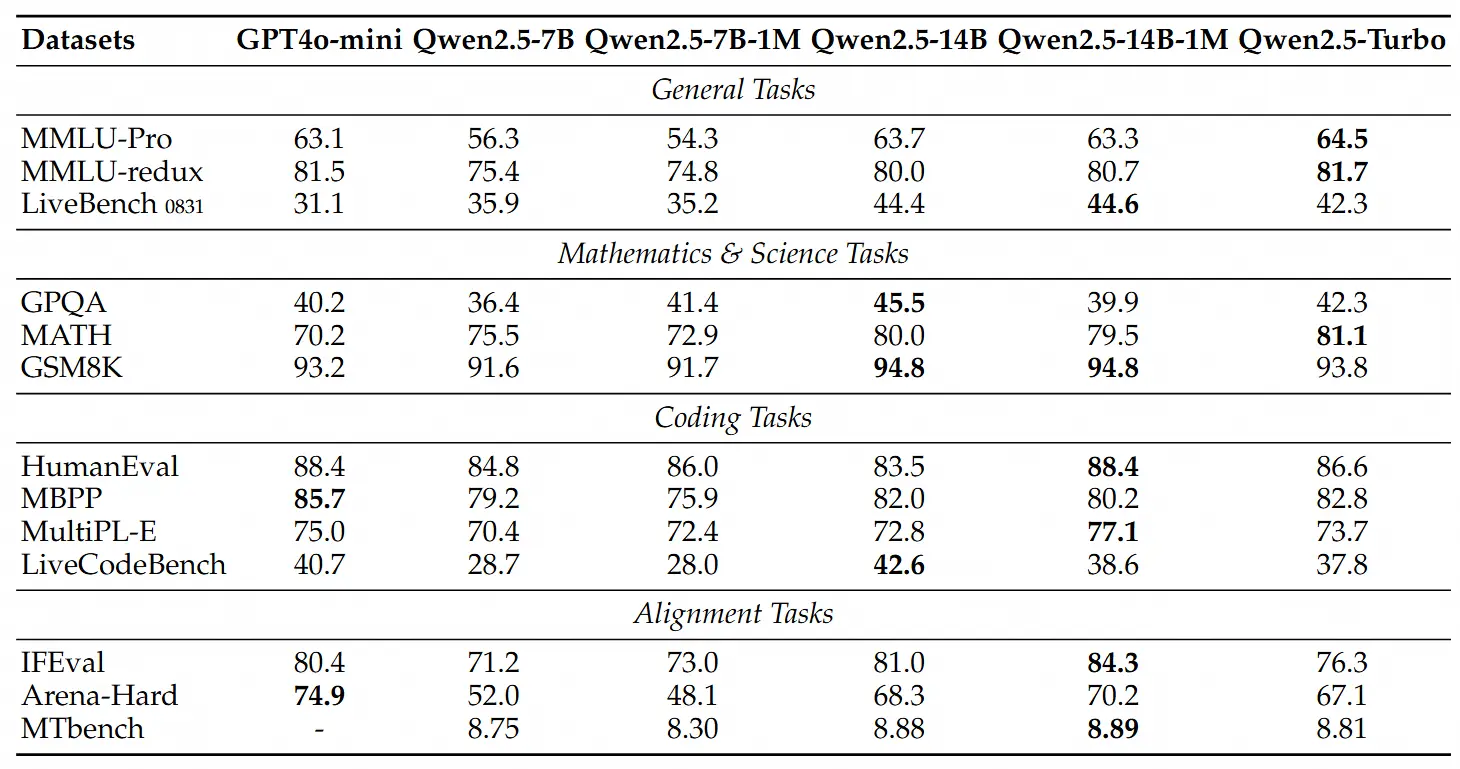
我们可以发现:
- Qwen2.5-7B-Instruct-1M 和 Qwen2.5-14B-Instruct-1M 在短文本任务上的表现与其128K版本相当,确保了基本能力没有因为增加了长序列处理能力而受到影响。
- 与 GPT-4o-mini 相比,Qwen2.5-14B-Instruct-1M 和 Qwen2.5-Turbo 在短文本任务上实现了相近的性能,同时上下文长度是 GPT-4o-mini 的八倍。
关键技术
在这里,将简要介绍构建 Qwen2.5-1M 背后的关键技术。更多内容可参阅技术报告。
长上下文训练
长序列的训练需要大量的计算资源,因此通义团队采用了逐步扩展长度的方法,在多个阶段将 Qwen2.5-1M 的上下文长度从 4K 扩展到 256K:
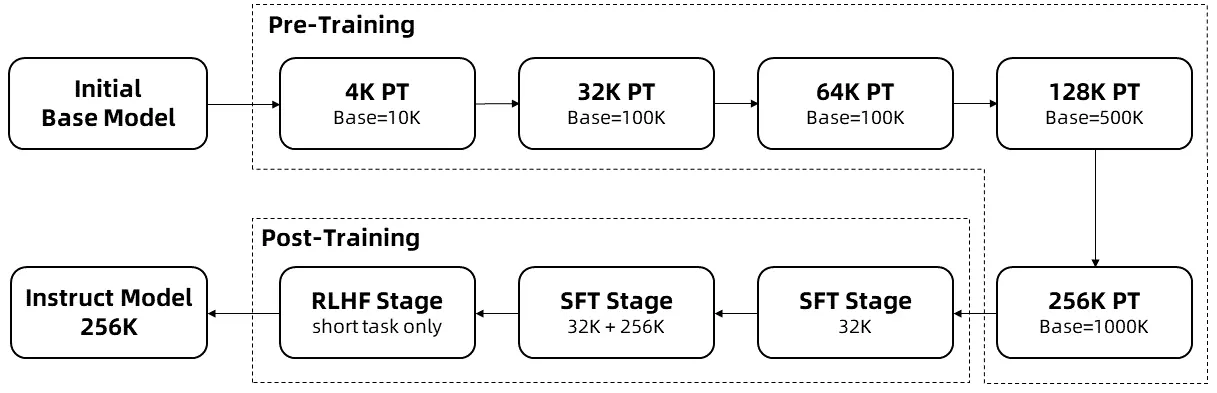
- 通义团队从预训练的Qwen2.5的一个中间检查点开始,此时上下文长度为4K。
- 在预训练阶段,通义团队逐步将上下文长度从 4K 增加到 256K,同时使用Adjusted Base Frequency的方案,将 RoPE 基础频率从 10,000 提高到 10,000,000。
- 在监督微调阶段,通义团队分两个阶段进行以保持短序列上的性能:
- 第一阶段: 仅在短指令(最多 32K 长度)上进行微调,这里通义团队使用与 Qwen2.5 的 128K 版本相同的数据和步骤数,以获得类似的短任务性能。
- 第二阶段: 混合短指令(最多 32K)和长指令(最多 256K)进行训练,以实现在增强长任务的性能的同时,保持短任务上的准确率。
- 在强化学习阶段,通义团队在短文本(最多 8K 长度)上训练模型。通义团队发现,即使在短文本上进行训练,也能很好地将人类偏好对齐性能泛化到长上下文任务中。
通过以上训练,通义团队最终获得了 256K 上下文长度的指令微调模型。
长度外推
在上述训练过程中,模型的上下文长度仅为 256K 个 Tokens。为了将其扩展到 1M ,通义团队采用了长度外推的技术。
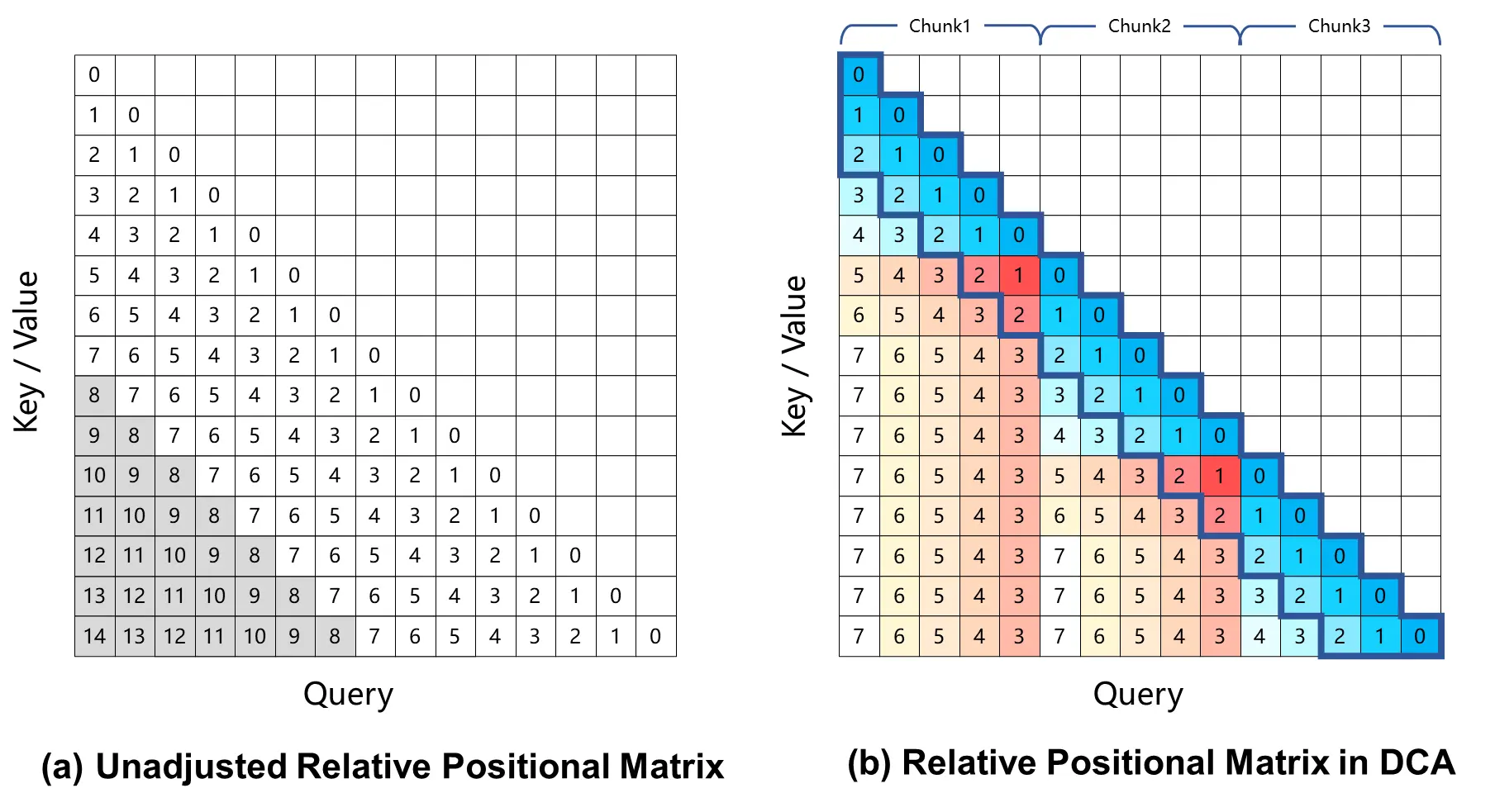
当前,基于旋转位置编码的大型语言模型会在长上下文任务中产生性能下降,这主要是由于在计算注意力权重时,Query 和 Key 之间的相对位置距离过大,在训练过程中未曾见过。为了解决这一问题,通义团队引入了Dual Chunk Attention (DCA),该方法通过将过大的相对位置,重新映射为较小的值,从而解决了这一难题。
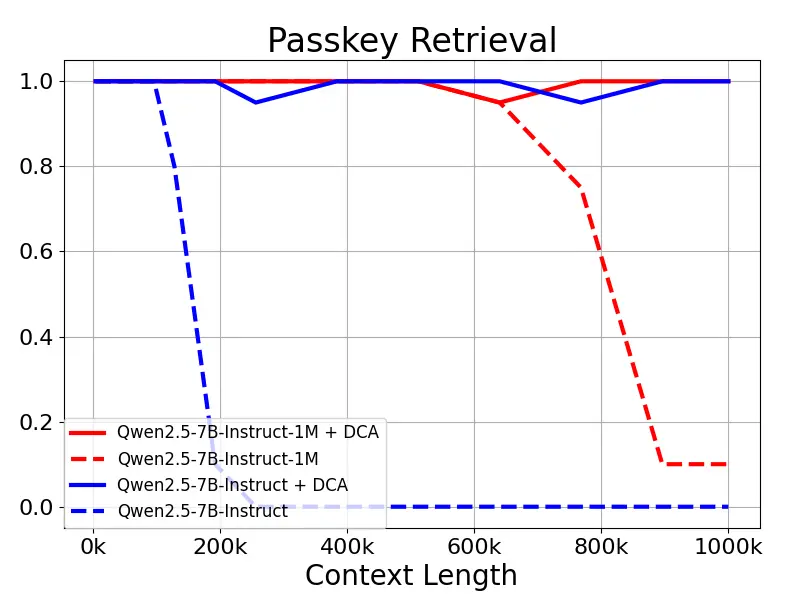
通义团队对 Qwen2.5-1M 模型及之前 128K 的版本进行了评估,分别测试了使用和不使用长度外推方法的情况。
结果表明:即使是仅在 32K 长度上训练的 Qwen2.5-7B-Instruct,在处理 1M 上下文的 Passkey Retrieval 任务中也能达到近乎完美的准确率。这充分展示了 DCA 在无需额外训练的情况下,也可显著扩展支持的上下文长度的强大能力。
稀疏注意力机制
对于长上下文的语言模型,推理速度对用户体验至关重要。为了加速预填充阶段,通义团队引入了基于 MInference 的稀疏注意力优化。在此基础上,通义团队还提出了一系列改进:
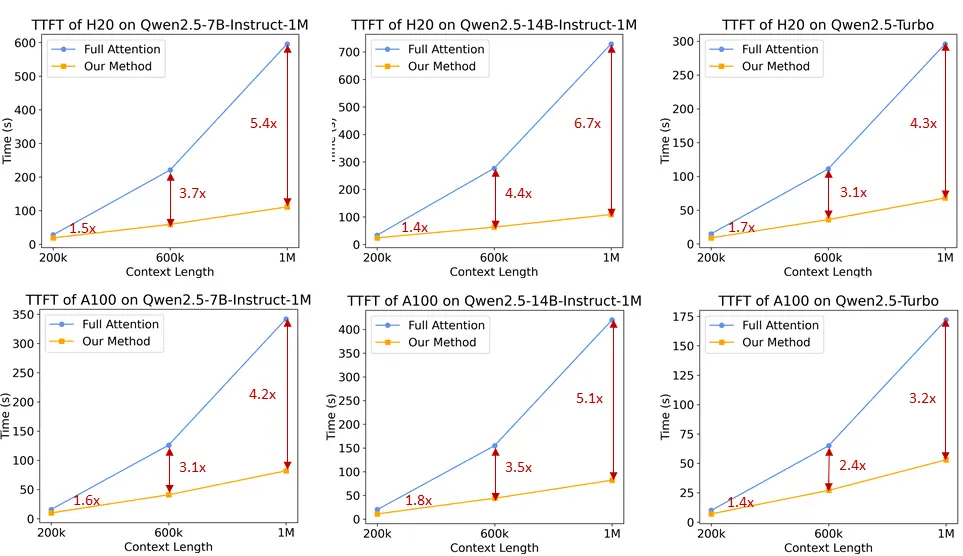
- 分块预填充: 如果直接使用模型处理长度100万的序列,其中 MLP 层的激活权重会产生巨大的显存开销。以Qwen2.5-7B 为例,这部分开销高达 71GB。通过将分块预填充(Chunked Prefill)与稀疏注意力适配,可以将输入序列以 32768 长度分块,逐块进行预填充,MLP 层激活权重的显存使用量可减少 96.7%,因而显著降低了设备的显存需求。
- 集成长度外推方案: 通义团队在稀疏注意力机制中进一步集成了基于 DCA 的长度外推方案,这使通义团队的推理框架能够同时享受更高的推理效率和长序列任务的准确性。
- 稀疏性优化: 原始的 MInference 方法需要进行离线搜索以确定每个注意力头的最佳稀疏化配置。由于全注意力权重对内存的要求太大,这种搜索通常在短序列上进行,不一定能在更长序列下起到很好的效果。通义团队提出了一种能够在100万长度的序列上优化稀疏化配置的方法,从而显著减少了稀疏注意力带来的精度损失。
- 其他优化: 通义团队还引入了其他优化措施,如优化算子效率和动态分块流水线并行,以充分发挥整个框架的潜力。
通过这些改进,通义团队的推理框架在不同模型大小和 GPU 设备上,处理 1M 长度输入序列的预填充速度提升了 3.2 倍到 6.7 倍。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











