
背景与动机
LoRA(低秩适应)是一种参数高效的微调技术,广泛用于大语言模型和扩散模型(如Stable Diffusion)的定制化训练。然而,传统LoRA训练方法存在效率低和易学到无关特征(如背景或风格)的缺点。复印机学习法(Copier Learning Method)通过训练两个LoRA模型来学习图像差异,但仍需大量步骤(约2000步),对计算资源要求较高。
开发者“hakomikan”于2025年3月4日提出ADDifT,旨在通过直接学习图像差异来优化LoRA训练。它不仅大幅减少训练时间,还通过交替训练和时间步调度提升模型的精确性和适用性。
ADDifT(Alternating Direct Difference Training)是一种创新的LoRA训练技术,旨在解决传统训练方法效率低下和学习无关特征的问题。它通过直接学习图像对(例如开眼与闭眼)的差异,显著减少训练时间,并提升模型的针对性。ADDifT基于Ollama等开源框架的LoRA技术,已在Stable Diffusion 1.5上验证,并计划扩展到其他扩散模型。相比传统LoRA和复印机学习法,ADDifT无需预训练复印模型,训练步骤从2000降至30-100,且能在低端硬件(如RTX 3060)上快速运行。其潜在应用包括自正则化和视频生成,使其成为生成式AI领域的重要进步。
LoRA训练技术的进步:引入新的训练方法
LoRA训练技术正在迅速发展,但自其诞生以来,基本的训练方法基本保持不变。这次,我开发了一种新的训练方法,并将详细解释其细节。该技术将复印机学习法中的差异学习所需的训练时间缩短至原来的十分之一到二十分之一,同时还能在多个图像集上同时进行训练。此外,它不仅有潜力应用于图像模型,还可以应用于一般的扩散模型。
LoRA训练与复印机学习法
首先,让我们回顾一下标准的训练方法。
传统训练方法
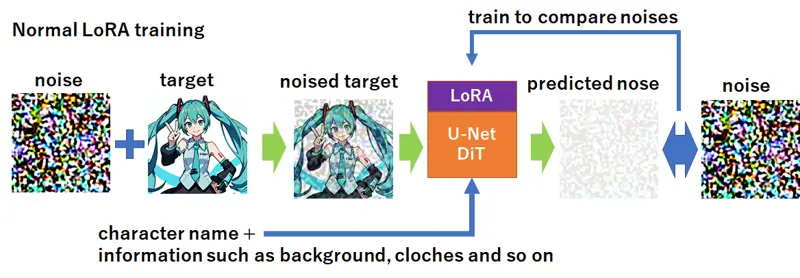
在传统的LoRA(或其他扩散模型)训练中,带有噪声的图像xt通过U-Net(或在最近的模型中,通过DiT)进行处理。然后将预测的噪声ϵ^θ(xt,t)与原始噪声ϵ进行比较。损失函数L定义为:
由于这个过程涉及噪声,可能看起来有些抽象。然而,这在扩散模型中至关重要,其目标是通过逐渐减少噪声来重建图像。训练确保预测的噪声ϵ^θ(xt,t)与原始噪声ϵ一致。简单来说,这个过程评估生成的图像与输入图像的相似程度。
然而,一个关键问题出现了:模型不仅会学习所需的角色特征,还会学习图像中不相关的元素。例如,如果一个角色正在做和平手势,模型可能会将该角色与总是做这个手势联系起来。同样,它可能会学习背景、艺术风格或其他细节。
通过标记和在大数据集上进行训练可以在一定程度上缓解这个问题,但也可能导致重要特征的丢失。
复印机学习法
为了解决这个问题,月須和・那々开发了复印机学习法。该方法训练两个独立的LoRA模型:
- 首先,将单个图像训练到极致,创建一个无论初始噪声如何都生成相同图像的模型。
- 然后,使用稍微修改的图像训练另一个LoRA模型。由于第一个模型只生成相同的图像,第二个模型只学习图像之间的差异。
这种方法允许创建仅修改图像特定方面的LoRA模型——这在以前是难以实现的。
引入ADDifT:一种新的训练方法
虽然ADDifT与复印机学习法在学习差异方面有相似之处,但其方法是独特的。
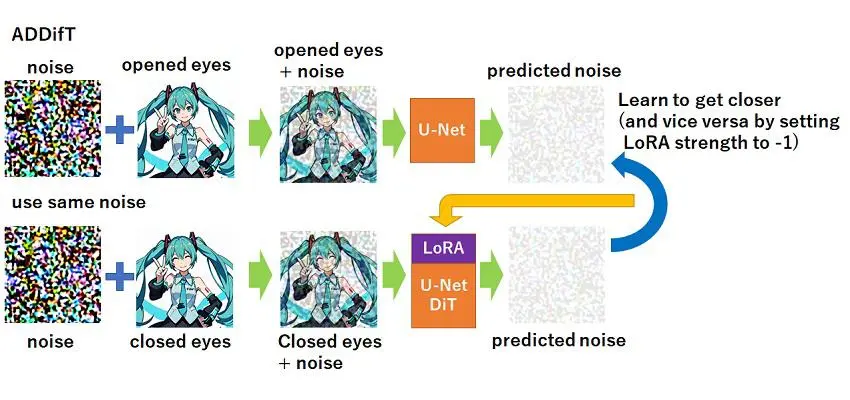
ADDifT,即交替直接差异训练,直接学习成对图像(x1,x2)之间的差异。“直接”意味着LoRA模型明确地只学习图像之间的变化。
例如,考虑学习睁眼和闭眼图像之间的差异。在ADDifT中,LoRA参数根据以下损失函数进行更新:
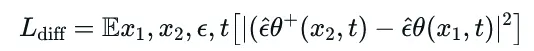
与传统训练不同,ADDifT旨在仅学习图像之间的修改,而不是生成特定图像。
这种方法无需首先创建复印机模型,从而显著减少了所需的训练步骤——通常只需30到100步。事实上,超过100步的训练可能会导致过拟合。
交替训练
ADDifT的“交替”意味着模型在两个相反的训练方向之间交替:
- 学习“睁眼→闭眼”
- 学习“闭眼→睁眼”(应用负LoRA)
这种交替防止了学习到不需要的特征。通过在反向过程中反转LoRA应用,只保留关键差异。
相应的损失函数为:
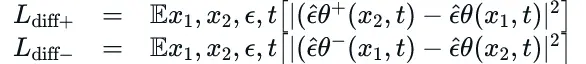
计划随机时间步
ADDifT引入了一个新概念:计划随机时间步。由于训练只需30到100步,时间步的分布变得不平衡。通常,时间步在0到1000之间随机选择,但在较少的步骤中,分布可能会变得偏斜。
为了解决这个问题,该方法将时间步分为五个相等的组,并按顺序选择。例如:
- 从0-200中选择
- 然后从201-400中选择
- ……直到800-1000
对于与眼睛相关的LoRA训练,重点是高时间步(500-1000),因为它们能带来更稳定的训练。相反,对于风格LoRA,较低时间步(200-400)更受青睐。
性能与速度比较
该方法将训练时间从:
(500+500步)×批次大小2=2000减少到:30步×批次大小1=30
对于SD1.5,在RTX 3060(12GB)上训练“闭眼”LoRA仅需30秒。
未来发展
该方法的一个潜在应用是LoRA训练中的自正则化。在DreamBooth训练中,通过将通用图像与目标图像混合来缓解过拟合。然而,这可能会导致不需要的伪影。
相反,ADDifT可以比较应用LoRA和未应用LoRA的噪声预测,以过滤掉不需要的学习效果。
此外,由于该方法适用于所有扩散模型,因此可以扩展到视频和其他生成任务。
结论
ADDifT是一种新颖的训练技术,能够快速学习图像差异,并广泛适用于扩散模型。鉴于其效率和灵活性,它可能成为未来AI驱动内容创作的宝贵工具。(来源)
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











