
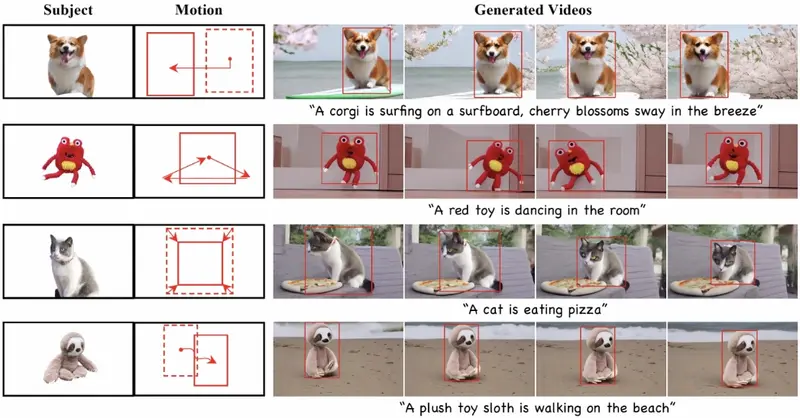
复旦大学、阿里巴巴、,能够根据单一图像和一系列界定框(bounding box)序列生成具有特定主题和运动轨迹的视频。简单来说,就是用户可以提供一张图片和一些关于视频中对象应该如何移动的指示,DreamVideo-2就能创造出一个全新的视频,里面的对象既符合图片中的样子,也按照指定的路径移动。例如,你手里有一张柯基犬的图片,你想要一个视频,视频里的柯基犬在冲浪板上冲浪,周围是樱花随风摇曳的场景。DreamVideo-2就能帮你实现这个想法,即使你没有原始的视频素材,只需要提供图片和一些描述运动的指示。
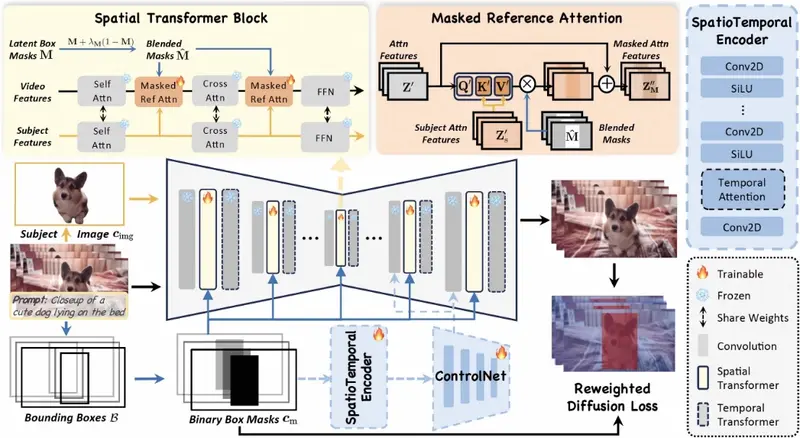
DreamVideo-2能够生成具有特定主题和运动轨迹的视频,分别由单张图像和边界框序列引导,并且无需测试时微调。具体来说,研究团队引入了参考注意力,利用模型固有的主题学习能力,并设计了一个掩码引导的运动模块,通过充分利用从边界框派生的框掩码的鲁棒运动信号来实现精确的运动控制。虽然这两个组件实现了它们预期的功能,但我们通过实验观察到运动控制往往主导主题学习。为了解决这个问题,研究团队提出了两个关键设计:掩码参考注意力,它将混合潜在掩码建模方案集成到参考注意力中,以增强所需位置的主题表示,以及重新加权的扩散损失,它区分了边界框内和边界框外区域的贡献,以确保主题和运动控制之间的平衡。在新策划的数据集上的广泛实验结果表明,DreamVideo-2 在主题定制和运动控制方面优于最先进的方法。
主要功能和特点:
- 零样本学习:用户不需要提供视频样本,只需提供一张图片和运动轨迹的描述。
- 精确运动控制:能够根据界定框序列精确控制视频中对象的运动。
- 主题和运动定制:可以定制视频的主题(如柯基犬)和运动轨迹(如冲浪)。
- 无需测试时微调:与需要在测试时进行复杂微调的方法不同,DreamVideo-2无需这些额外步骤。
工作原理:
DreamVideo-2通过以下几个关键步骤工作:
- 主题学习:使用提供的图片,DreamVideo-2通过内部的参考注意力机制(reference attention)学习图片中的主题外观。
- 运动控制:利用一系列界定框转换成的二进制掩码(binary box masks),DreamVideo-2通过一个掩码引导的运动模块(mask-guided motion module)来控制视频中对象的运动。
- 平衡学习:为了确保主题学习和运动控制之间的平衡,DreamVideo-2引入了混合掩码(blended masks)和重新加权的扩散损失函数(reweighted diffusion loss)。
具体应用场景:
- 娱乐和社交媒体:用户可以快速创建个性化的视频内容,用于分享在社交媒体上。
- 广告和营销:公司可以利用这个技术根据季节性活动或产品特点快速生成吸引人的视频广告。
- 教育和培训:可以创建定制的视频内容,帮助解释复杂的概念或者模拟特定的操作过程。
- 电影和游戏制作:在电影特效或者游戏开发中,可以用于生成或者预览特定的场景和动作。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











