
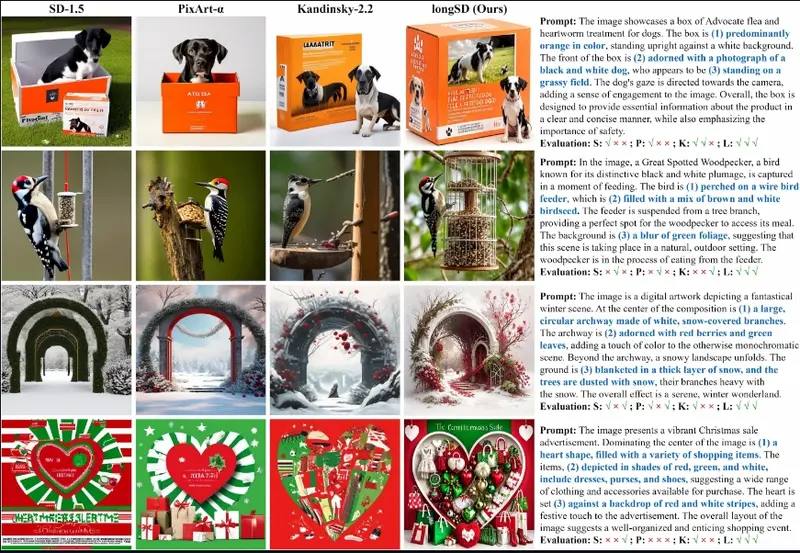
文生图模型的快速发展使它们能够从给定的文本生成前所未有的结果。然而,随着文本输入变长,现有的编码方法如 CLIP 面临限制,并且将生成的图像与长文本对齐变得具有挑战性。为了解决这些问题,香港大学、新加坡 Sea AI 实验室、中国人民大学和浙江大学的研究人员提出了 LongAlign,其中包括一种用于处理长文本的分段编码方法和一种用于有效对齐训练的分解偏好优化方法。
对于分段编码,长文本被分成多个段并分别处理。该方法克服了预训练编码模型的最大输入长度限制。对于偏好优化,研究团队提供了基于分解 CLIP 的偏好模型来微调扩散模型。具体来说,为了利用基于 CLIP 的偏好模型进行 T2I 对齐,研究团队深入研究了它们的评分机制,并发现偏好分数可以分解为两个部分:一个与文本相关的部分,用于衡量 T2I 对齐,以及一个与文本无关的部分,用于评估人类偏好的其他视觉方面。此外,研究团队发现与文本无关的部分在微调过程中导致了常见的过拟合问题。为了解决这个问题,研究团队提出了一种重新加权策略,为这两个部分分配不同的权重,从而减少过拟合并增强对齐。
主要功能和特点:
- 长文本分割处理:将长文本分割成多个小段,分别处理,以克服模型输入长度的限制。
- 偏好模型优化:通过分析偏好模型的评分机制,将评分分解为与文本相关和无关两部分,以减少过拟合并增强文本对齐。
- 梯度重加权策略:在微调过程中,对导致过拟合的文本无关部分进行权重调整,以增强模型的对齐能力。
工作原理:
- 文本分割:将长文本描述分割成多个小段,比如句子或短语。
- 独立编码:对每个文本段进行独立编码,生成嵌入向量。
- 合并编码:将各个文本段的嵌入向量合并,用于图像生成模型。
- 偏好模型分解:将偏好模型的评分分解为与文本对齐相关的部分和与文本对齐无关的部分。
- 梯度重加权:在模型微调时,对导致过拟合的文本无关部分的梯度进行重加权,以减少其影响。

具体应用场景:
- 创意写作:作家可以提供长篇故事描述,AI根据这些描述生成一系列插图。
- 广告和营销:根据产品的详细描述生成吸引人的广告图像。
- 教育和培训:根据复杂的教学材料生成相应的教学图像或动画,帮助学生更好地理解概念。
- 游戏开发:根据游戏剧本生成场景概念图,帮助设计师快速把握场景布局和氛围。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











