
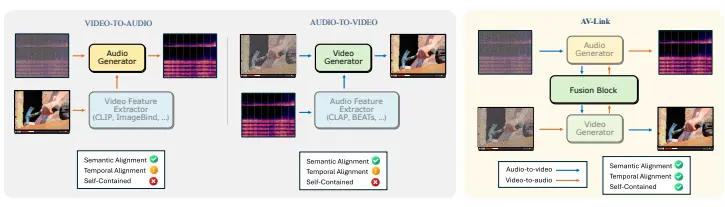
莱斯大学和Snap的研究人员推出统一框架AV-Link,用于跨模态音频-视频生成。AV-Link利用冻结的视频和音频扩散模型的激活来进行时间对齐的跨模态条件生成,这意味着它可以基于视频内容生成与之语义和时间上对齐的音频,或者根据音频内容生成相应的视频内容。例如,给定一段展示烟花爆炸的视频,AV-Link能够生成与视觉内容时间上精确对齐的爆炸声音频;同样,给定一段爆炸声的音频,AV-Link能够生成展示爆炸场景的视频。
主要功能:
- 视频到音频(V2A)生成: 根据视频内容生成与之语义和时间上对齐的音频。
- 音频到视频(A2V)生成: 根据音频内容生成与之语义和时间上对齐的视频。
主要特点:
- 时间对齐的跨模态条件生成: AV-Link通过使用时间对齐的自注意力操作和对称特征注入机制,实现了精确的时间对齐。
- 无需专门的预训练特征提取器: 与传统方法不同,AV-Link直接利用预训练的扩散模型的激活作为条件信号,避免了对特定任务预训练特征提取器的依赖。
- 统一框架: AV-Link提供了一个统一的框架,可以处理V2A和A2V任务,增加了模型的灵活性和适用性。
工作原理
AV-Link的工作原理基于以下几个关键组件:
- 融合块(Fusion Block): 通过时间对齐的自注意力操作和对称特征注入机制,实现音频和视频模态之间的双向信息交换。
- 时间对齐的特征: 使用预训练的扩散模型的激活作为条件信号,这些激活包含了丰富的语义信息,并且由于生成媒体的起源,它们也是时间对齐的。
- 对称特征注入: 将融合块生成的特征对称地重新注入到冻结的音频和视频生成器中,以进一步提升生成质量。
具体应用场景
- 电影制作: 在电影制作中,AV-Link可以用来生成与视觉场景精确匹配的音效,简化后期音频制作流程。
- 虚拟现实(VR)和增强现实(AR): 在VR或AR应用中,AV-Link可以根据用户的视觉体验实时生成相应的音频,提升沉浸感。
- 音乐视频制作: AV-Link可以根据音乐生成匹配的视频内容,或者根据视频内容生成匹配的音乐视频。
- 自动字幕和音频描述: 对于听障人士,AV-Link可以自动生成视频内容的音频描述;对于视障人士,可以生成音频内容的视频字幕。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











