腾讯推出大语言模型适配器(LLM Adapter)ELLA,无需 U-Net 或大语言模型训练,就可通过 ELLA ,为文生图模型增强文本对齐,解决大多数模型受限于 CLIP 本身对密集提示词的理解能力(多对象、详细属性、复杂关系、长文本对齐等)较差的问题。
简单来说,你有一段描述一个场景的提示词,比如“一只穿着蒸汽朋克风格眼镜、白T恤和皮夹克的法老雕像画像”。现在,你想SD模型能够根据这段描述生成一幅图像。这就是文本到图像生成模型的工作内容。然而,现有的模型在处理这种复杂的、包含多个对象和属性的描述时往往会遇到困难。这就是ELLA模型试图解决的问题。

主要功能:
ELLA的主要功能是提高文本到图像生成模型在处理复杂、详细的文本描述时的性能。它通过结合大型语言模型的强大语言理解能力,帮助生成模型更好地理解文本中的每个细节,并生成与之匹配的图像。

主要特点:
- 无需重新训练: ELLA能够与现有的扩散模型和大型语言模型无缝结合,无需对这些预训练模型进行额外的训练。
- 时序感知语义连接器(TSC): ELLA引入了一个新颖的模块,能够根据生成过程中的不同阶段动态提取文本特征,从而更准确地引导图像生成过程。
- 高兼容性: ELLA设计为轻量级模块,可以轻松集成到社区模型和工具中,提升它们的文本跟随能力。
工作原理:
ELLA的工作原理可以分为以下几个步骤:
- 文本理解: 使用大型语言模型(如T5或LLaMA-2)来理解输入的文本描述,提取出文本特征。
- 时序感知: TSC模块根据生成过程中的噪声去除阶段(即扩散过程的时序),动态提取与当前阶段最相关的文本特征。
- 图像生成: 将提取的文本特征用于指导扩散模型的图像生成过程,确保生成的图像与文本描述紧密对齐。
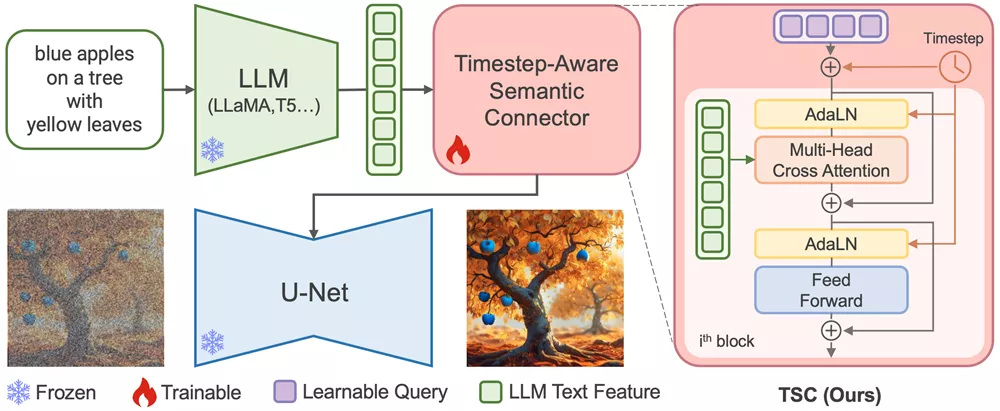
时序感知语义连接器(TSC)
时序感知语义连接器(TSC)在ELLA模型中扮演了一个至关重要的角色,它负责在文本到图像的生成过程中,根据生成的不同阶段动态地提取和利用文本特征。为了更好地理解TSC的作用,我们可以将其比作一个翻译官,它能够根据当前的上下文和阶段,将文本描述中的关键信息准确地传达给图像生成模型。

TSC的主要作用包括:
- 动态特征提取:在文本到图像的生成过程中,不同的阶段需要关注文本描述中的不同信息。例如,在生成过程的早期阶段,模型可能需要关注文本中描述的主要对象和布局;而在后期阶段,则需要关注更细致的属性,如颜色和纹理。TSC能够根据这些不同的需求,动态地从大型语言模型中提取相应的文本特征。
- 时序依赖性:TSC通过整合时间步骤(timestep)信息,使得模型能够理解文本描述在生成过程中的重要性变化。这意味着TSC能够识别出在生成的不同时间点,哪些文本信息是最为关键的,从而为图像生成提供更精确的指导。
- 语义对齐:TSC的设计使得生成的图像能够更好地与文本描述保持一致。通过在不同阶段提供不同层次的语义信息,TSC帮助模型在生成图像时更好地捕捉到文本中的复杂关系和细节。
TSC的工作原理:
TSC基于transformer架构,通过自注意力(self-attention)机制来处理文本特征。在生成过程中的每个时间步骤,TSC都会根据当前的噪声水平和文本描述,更新其内部状态,从而提取出与当前阶段最相关的语义特征。这些特征随后通过交叉注意力(cross-attention)机制传递给扩散模型,指导图像的生成。
具体应用场景中的TSC:
在实际应用中,TSC使得ELLA模型能够处理包含多个对象、详细属性和复杂关系的长文本描述。例如,当用户输入一段描述一个繁忙市场场景的文本时,TSC能够在生成过程的不同阶段,分别提取出关于市场布局、各个摊位的具体商品、以及人物活动等信息,从而生成一个细节丰富、与文本描述高度一致的图像。
DPG-Bench(Dense Prompt Graph Benchmark)是一个用于评估文本到图像模型在处理复杂、密集提示(dense prompts)时性能的基准测试集。这个基准测试集专门设计来评估模型在理解和生成包含多个对象、属性和关系的复杂场景描述时的能力。

DPG-Bench的主要特点和作用包括:
- 复杂性:DPG-Bench包含的提示(prompts)比以往的基准测试集更为复杂,它们描述了多个对象,每个对象都有不同的属性和关系。
- 全面性:这个基准测试集旨在全面评估模型在理解密集语义信息方面的能力,不仅仅是简单的对象识别,还包括对象间的空间关系和整体场景的布局。
- 自动评估:DPG-Bench利用最先进的多模态语言模型(MLLM)自动生成提示,并通过自动化的评估流程来衡量生成图像的质量。
- 挑战性:通过包含1,065个复杂提示,DPG-Bench提供了一个具有挑战性的测试环境,能够区分不同模型在处理复杂文本到图像生成任务时的性能。
DPG-Bench的构建过程:
- 从COCO、PartiPrompts、DSG-1k和Object365等数据源收集数据。
- 利用GPT-4等先进的语言模型自动生成详细的提示,这些提示包含丰富的语义信息。
- 通过自动化的流程生成对应的图谱(tuple categories, questions, and graphs),用于评估模型生成的图像。
DPG-Bench的应用场景:
- 模型开发和测试: 研究人员和开发者可以使用DPG-Bench来测试和比较不同模型在理解复杂文本描述和生成高质量图像方面的能力。
- 技术进步评估: DPG-Bench可以作为衡量文本到图像生成领域技术进步的标尺,帮助研究人员了解当前技术的局限性和未来的发展方向。
- 社区挑战: 它可以作为社区挑战的一部分,鼓励研究人员和开发者共同推动这一领域的发展。

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











