
来自哈尔滨大学和清华大学的研究团队推出VideoElevator,利用文生图模型来增强文生视频的质量和细节,这个过程是无需训练的,可以直接插入现有的模型中使用,还能利用文生图模型来实现风格迁移,非常方便。
主要功能和特点:
- 提升视频质量: VideoElevator能够显著提高由文本到视频扩散模型生成的视频的质量,使其更接近于由文本到图像扩散模型生成的图像的质量。
- 无需训练: 这个技术不需要额外的训练过程,可以直接应用于不同的文本到视频和文本到图像的模型。
- 增强风格多样性: 它不仅能够改善基础的文本到视频模型的性能,还能够利用个性化的文本到图像模型来创造风格多样的视频。
工作原理:
VideoElevator将视频生成的每个步骤明确分解为两个部分:时间运动细化和空间质量提升。时间运动细化利用文本到视频模型来增强视频的时间一致性,并通过反转过程适应文本到图像模型所需的噪声分布。接着,空间质量提升利用扩展的文本到图像模型直接预测出更少噪声的潜在表示,从而增加更多逼真的细节。
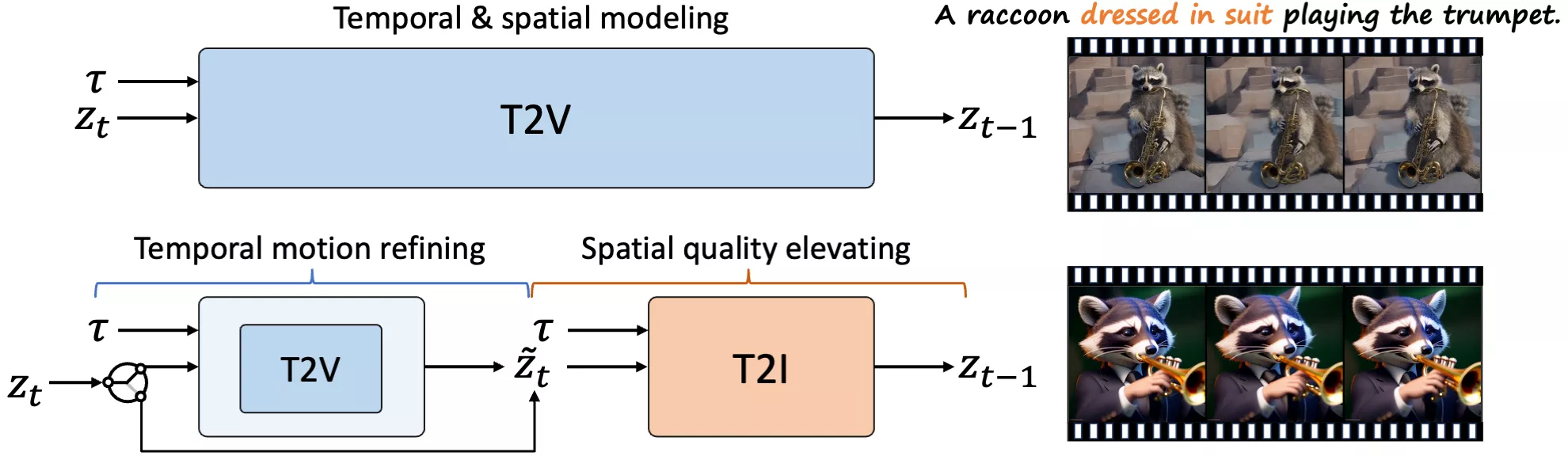
在实际应用中仍然面临一些局限性和挑战:
- 数据依赖性:VideoElevator的性能在很大程度上依赖于训练文本到图像模型的数据集。如果这些数据集不够多样化或质量不高,可能会限制生成视频的多样性和真实感。
- 计算资源需求:虽然VideoElevator是一个无需训练的即插即用方法,但运行高质量的文本到视频和文本到图像模型仍然需要大量的计算资源,这可能限制了它在资源受限的环境中的应用。
- 风格一致性:在使用个性化的文本到图像模型时,确保视频中的所有帧在风格上保持一致可能是一个挑战,尤其是在处理具有复杂或抽象概念的提示时。
- 编辑和控制的复杂性:虽然VideoElevator提供了一定程度的控制,允许用户通过文本提示来指导视频内容的生成,但用户可能仍需面对如何精确控制生成结果的挑战。
- 模型的泛化能力:VideoElevator在特定的数据集和模型上进行了优化,可能在遇到与训练数据显著不同的新数据时,其性能会有所下降。
- 用户输入的挑战:用户需要提供准确的文本提示来生成所需的视频内容,这可能需要一定的技巧和经验,对于普通用户来说可能是一个挑战。
- 伦理和版权问题:生成的视频可能涉及版权和伦理问题,尤其是在使用个性化内容和真实人物形象时,需要谨慎处理。
- 结果的不可预测性:尽管VideoElevator试图提高生成视频的质量,但结果仍然可能存在不可预测性,有时可能无法完全符合用户的期望。
VideoElevator是一个强大的工具,它通过结合最新的文本到图像生成技术,来提升视频生成的质量,并且支持个性化的创作,为视频制作和编辑带来了新的可能性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











