
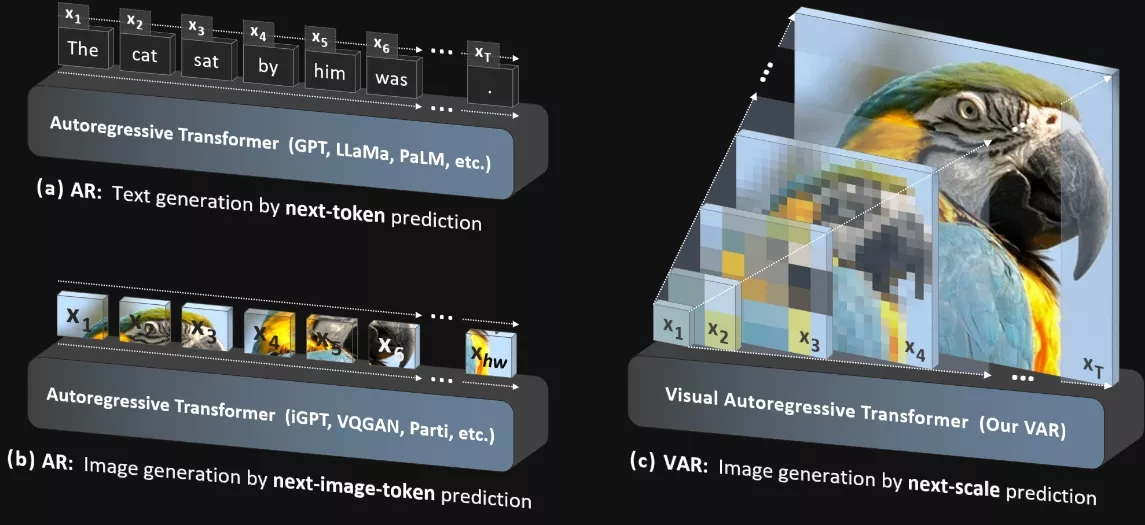
来自北京大学和字节跳动的研究人员推出新型图像生成模型VAR(Visual Autoregressive Modeling,“视觉自回归建模”),VAR模型是一种基于Transformer的自回归(autoregressive)模型,它能够以一种从粗糙到精细的方式生成图像,这与传统的像素级顺序生成(像扫描一样)有很大不同。
主要功能和特点:
- 高效生成:VAR模型能够快速生成高质量图像,其推理速度比现有的自回归模型快20倍。
- 高质量图像:在ImageNet数据集上,VAR模型在生成256×256像素图像时,其Fréchet Inception Distance(FID)从18.65降低到1.80,这是一个衡量生成图像质量的指标,数值越低表示质量越高。
- 可扩展性:VAR模型展现出了类似于大型语言模型(LLMs)的扩展定律,即模型性能随着模型大小的增加而持续提升。
- 零样本泛化能力:VAR模型能够在没有额外训练的情况下,泛化到不同的下游任务,如图像修复、扩展和编辑。
工作原理:
VAR模型的工作原理是将图像编码成多个不同分辨率的标记图(token maps),然后自回归地从低分辨率到高分辨率逐层生成图像。在生成过程中,模型并行生成每个分辨率级别的所有标记,而不是一个接一个地生成。这种方法允许模型在生成图像时保持空间局部性,并显著降低了计算复杂度。
具体应用场景:
- 图像生成:VAR模型可以用于生成高质量的艺术作品或者用于数据增强。
- 图像编辑:VAR模型的零样本泛化能力使其能够无需特定训练就能进行图像编辑任务,如改变图像中的对象或背景。
- 视频生成:虽然VAR模型目前专注于图像,但其原理可以扩展到视频生成,处理更长时间序列的数据。
总的来说,VAR模型是一种强大的图像生成工具,它结合了自回归模型的灵活性和变换器模型的强大学习能力,能够在多个领域提供高效、高质量的图像生成服务。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











