视频对象分割是一项具有挑战性的任务,每个像素必须被准确标记,并且这些标签必须在帧之间保持一致。当分割具有任意粒度时,难度会进一步增加,这意味着段的数量可以任意变化,并且掩模仅基于一个或几个样本图像定义。这种复杂性使得传统的分割方法难以应对。
挑战
像素级精度:每个像素必须被准确标记,这对于高分辨率视频尤其困难。 帧间一致性:标签必须在连续的帧之间保持一致,以确保对象的连续性和运动的平滑性。 任意粒度:分割段的数量可以任意变化,这要求模型具有高度的灵活性和适应性。 样本稀疏性:掩模仅基于一个或几个样本图像定义,这限制了模型的学习能力。
解决方案SMITE
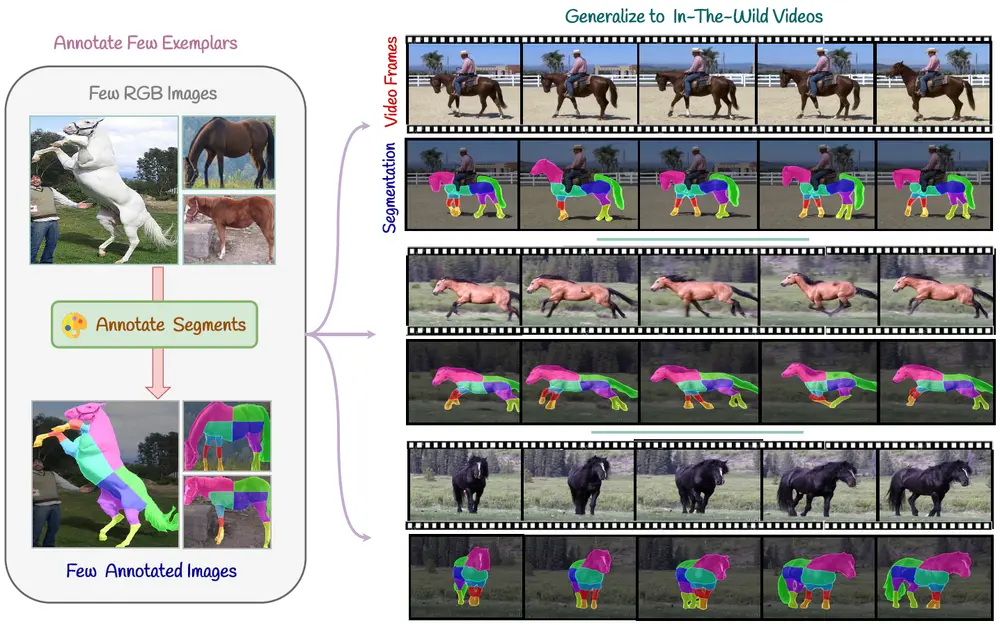
西蒙弗雷泽大学、Autodesk研究、多伦多大学和Google DeepMind的研究人员一个名为SMITE(SEGMENT ME IN TIME)的视频对象分割技术,结合了预训练的文本到图像扩散模型和额外的跟踪机制,以解决上述挑战。SMITE旨在解决视频内对象的分割问题,特别是在需要任意粒度(即对象可以被分割成不同数量的片段)的情况下。这项技术特别适用于需要对视频中的对象进行精确且一致的像素级标记,并保持这些标记在视频帧间一致性的应用场景。
例如,在视觉特效(VFX)制作中,可能需要将视频中的人物面部进行分割,以便进行面部表情的捕捉或替换。SMITE可以在只有一两张参考图像的情况下,对整个视频中的人物面部进行一致且准确的分割,无需对视频中的每一帧都进行手动分割。
主要功能和特点
灵活的粒度分割:SMITE能够根据少量的参考图像,对视频中的对象进行不同粒度级别的分割。 预训练模型的应用:利用预训练的文本到图像扩散模型,结合额外的跟踪机制,实现对视频的有效分割。 跨帧一致性:通过时间注意力和投票机制,SMITE保证了分割结果在时间上的一致性,减少了闪烁和噪声。 少量样本学习:SMITE能够在只有少量样本图像的情况下学习并泛化到未见过的视频上。
工作原理
预训练模型:SMITE使用预训练的文本到图像扩散模型,该模型能够理解文本提示并生成相应的图像特征。 时间注意力:通过在模型中加入时间注意力机制,SMITE能够在视频帧之间共享信息,从而保持分割的一致性。 跟踪和投票机制:SMITE采用点跟踪算法来跟踪视频中的对象部分,并使用投票机制来确定每个像素的标签,以此保持分割的一致性。 低通滤波器:为了保持分割结构并平滑边界过渡,SMITE在最终去噪步骤中使用低通滤波器。
实验结果
研究人员通过实验验证了该方法的有效性,结果显示:
像素级精度:生成的掩模在像素级上具有高精度,能够准确捕捉对象的边界。 帧间一致性:掩模在连续的帧之间保持一致,确保对象的连续性和运动的平滑性。 任意粒度:方法能够处理不同数量的分割段,具有高度的灵活性和适应性。 样本稀疏性:即使基于少量样本图像,生成的掩模也能保持高质量和一致性。
具体应用场景
视觉特效(VFX):在电影和电视剧中,用于面部表情捕捉、物体替换等。 监控和安全:对视频中的人物或车辆进行跟踪和分割,以进行安全监控。 自动驾驶:对道路上的车辆和行人进行精确分割,以提高自动驾驶系统的决策能力。 医疗成像:在医学影像中分割不同的组织和器官,以辅助诊断。
SMITE通过其创新的方法,为视频分割领域提供了一个高效且灵活的工具,能够在多种应用中实现高质量的视频对象分割。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











