
南洋理工大学和上海人工智能实验室的研究人员推出视频生成框架RepVideo,旨在通过重新思考跨层表示来提高文本到视频(Text-to-Video, T2V)扩散模型的性能。该框架通过积累邻近层的特征来形成丰富的表示,从而捕获更稳定的语义信息,进而改善视频生成中的空间外观和时间一致性。
例如,使用RepVideo生成一个描述“一只可爱的红熊猫顽皮地蹲在树枝上”的视频。传统的T2V模型可能会在生成的视频中出现红熊猫的外观在不同帧中变化显著的问题,而RepVideo能够生成主体一致、运动平滑且时间连贯的视频,即使在多场景切换时也能保持红熊猫的外观和动作的一致性。

主要功能
- 视频生成:能够根据文本提示生成高质量的视频。
- 空间细节增强:提高视频中物体的空间关系和细节的准确性。
- 时间一致性提升:确保视频帧之间的时间连贯性,减少运动不连贯或模糊的问题。
主要特点
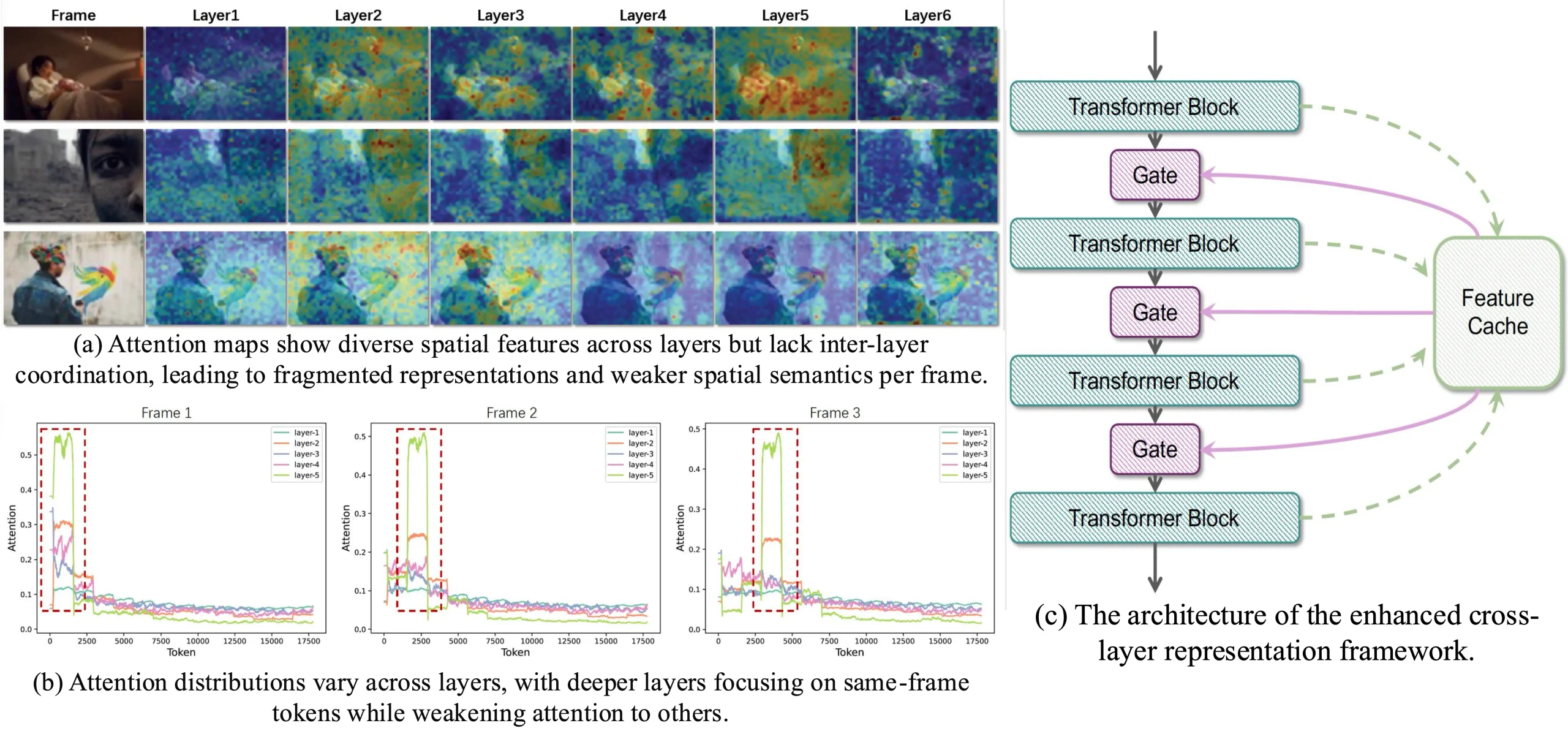
- 跨层特征积累:通过特征缓存模块(Feature Cache Module)积累多个邻近Transformer层的特征,形成更丰富的表示。
- 语义稳定性:通过门控机制(Gating Mechanism)将积累的特征与原始Transformer输入结合,增强语义表达能力,同时保持特征在相邻帧之间的一致性。
- 无需额外网络:不引入额外的网络结构,保持模型的简单性和计算效率。
- 轻量级实现:引入的特征积累和门控机制轻量级,引入的额外参数和计算开销小。
工作原理
- 特征缓存模块:在Transformer的每一层中,将输出的标记序列存储在缓存中,允许特征缓存模块从多个邻近Transformer层中积累特征。
- 特征聚合:计算存储在特征缓存模块中的特征的均值,形成更语义丰富的表示。
- 门控机制:通过门控机制将聚合后的特征与原始Transformer输出动态结合,使用可学习的参数控制它们的相对影响。
- 训练:基于CogVideoX-2B模型进行微调,使用大规模视频数据集进行训练,确保模型在视频生成任务中的性能。
具体应用场景
- 视频内容创作:为视频创作者提供工具,根据文本描述生成高质量的视频内容,如广告、电影预告片等。
- 虚拟现实和增强现实:在VR和AR应用中,根据虚拟环境的描述生成连贯的视频内容,增强用户体验。
- 教育和培训:生成教育视频,根据教学内容生成连贯的动画,帮助学生更好地理解和记忆知识。
- 游戏开发:在游戏开发中,根据游戏场景和角色描述生成连贯的视频动画,提高游戏的视觉效果。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











