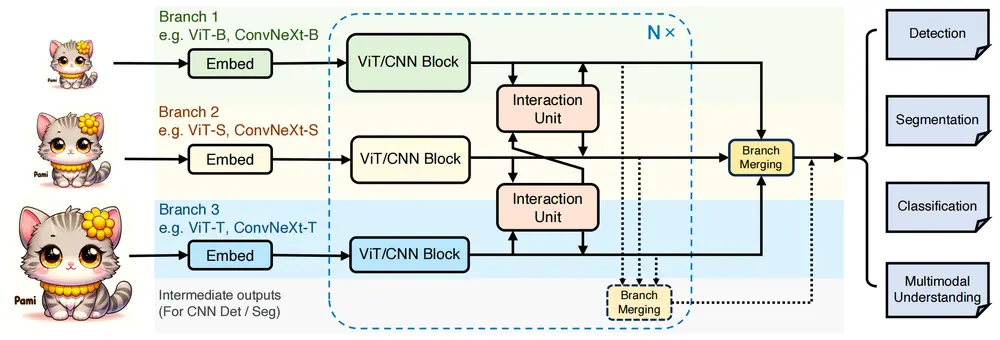
上海交通大学、清华大学、上海人工智能实验室、香港中文大学和商汤科技的研究人员推出新型网络架构PIIP,旨在提高视觉感知和多模态理解任务中的计算效率和性能。PIIP通过将不同分辨率的图像与不同参数规模的预训练模型(如ViTs或CNNs)相结合,形成参数逆置的图像金字塔,从而在保持高性能的同时显著降低计算成本。
例如,在对象检测任务中,传统的图像金字塔方法会使用相同的大规模模型处理不同分辨率的图像,导致计算成本随着图像分辨率的增加而呈二次方增长。PIIP则采用小规模模型处理高分辨率图像,大规模模型处理低分辨率图像,通过这种方式,PIIP能够在保持性能的同时,显著降低计算成本。具体来说,PIIP在MS COCO数据集上的对象检测任务中,相比传统的单分支模型,能够在减少40%-60%计算量的情况下,将性能提升1%-2%。
主要功能
- 视觉感知:提高对象检测、分割和图像分类等视觉感知任务的性能。
- 多模态理解:增强多模态大型语言模型(MLLMs)对图像的理解能力,提升在多模态任务中的表现。
主要特点
- 参数逆置设计:将不同分辨率的图像与不同参数规模的模型相结合,小模型处理高分辨率图像,大模型处理低分辨率图像,平衡计算成本和性能。
- 跨分支特征交互:通过引入跨分支特征交互机制,整合不同空间尺度和语义级别的特征,提高视觉表示学习的效果。
- 异构架构支持:支持纯ViT、纯CNN以及异构ViT-CNN网络结构,充分发挥ViT的全局语义建模能力和CNN的局部特征提取能力。
- 高效计算:在保持高性能的同时,显著降低计算成本,适用于大规模视觉基础模型和多模态大型语言模型。
工作原理
- 多分辨率分支:将输入图像调整为不同分辨率,并输入到不同规模的预训练模型中,高分辨率图像由小模型处理,低分辨率图像由大模型处理。
- 跨分支交互:在每个分支之间插入交互单元,通过可变形注意力机制和前馈网络进行特征融合,整合不同分辨率的特征。
- 分支合并:将所有分支的输出特征图合并为单一特征图,用于后续的任务处理,如对象检测、分割或图像分类。
- 多模态理解:在多模态任务中,PIIP通过项目器将视觉特征与语言模型的嵌入空间对齐,整合多尺度特征,提高模型对图像的理解能力。
具体应用场景
- 对象检测:在MS COCO数据集上,PIIP能够更准确地检测小物体,如背景中的小长椅和人物,或小汽车。
- 实例分割:PIIP能够更精确地分割对象,提供更清晰的边界和细节。
- 图像分类:PIIP在ImageNet数据集上的图像分类任务中,能够在减少计算成本的同时保持或提高分类准确率。
- 多模态理解:PIIP-LLaVA在多模态基准测试中表现出色,能够处理细粒度的视觉-语言任务,如文本识别、计数和细粒度识别。例如,PIIP-LLaVA能够从身份证中提取视觉信息并正确组织,其表现甚至可与GPT-4v相媲美。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











