
图像合成是计算机视觉中的一个常见任务,涉及将前景对象无缝集成到背景场景中。传统的图像合成方法通常依赖于人为的编辑或预定义的规则,难以处理前景对象与背景场景之间的复杂相互作用。为了应对这一挑战,哈佛大学、康奈尔理工大学、香港理工大学和波士顿学院的研究人员提出了 Mask-Aware Dual Diffusion (Madd) 模型,该模型通过引入“功能性”概念,旨在根据各种位置提示将任何对象无缝插入任何场景中。例如,将一个人插入到一个场景中时,系统会确保这个人站在地面上而不是悬浮在空中,或者将一个杯子插入到场景中时,会确保它放在一个表面上。
- 项目主页:https://kakituken.github.io/affordance-any.github.io
- GitHub:https://github.com/KaKituken/affordance-aware-any

主要功能:
- 对象插入: 将任意对象插入到任意场景中。
- 位置提示支持: 支持多种位置提示,包括点、边界框、掩码,甚至是无提示(null prompts)。
- 掩码感知双扩散模型(MADD): 同时去噪RGB图像和插入掩码,以实现精确的对象位置和大小调整。
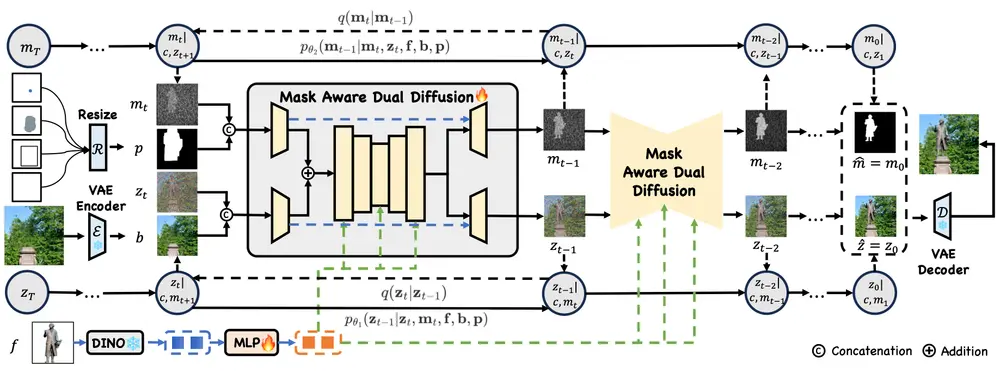
功能性感知的对象插入任务
功能性感知的对象插入任务的核心思想是确保插入的前景对象不仅在视觉上与背景场景融合良好,还能在功能上与其环境相适应。例如,椅子应该放在桌子上而不是空中,汽车应该停在道路上而不是水面上。为了实现这一目标,研究人员构建了 SAM-FB 数据集,该数据集包含超过300万个样本,涵盖3000多个对象类别,提供了丰富的训练数据来学习不同对象与场景之间的功能性关系。
工作原理
- 任务定义: 给定前景对象、背景场景和位置提示,模型需要预测一个合成图像,将对象根据正确的可承受性放置在场景中,并与位置提示的意图对齐。
- 掩码感知双扩散(MADD): 模型采用双流架构,同时去噪RGB图像和对象掩码。在去噪过程中,对象的位置逐渐被细化,同时合成目标RGB图像,确保对象与位置之间的准确对齐。
- 位置提示编码器: 将不同类型的位置提示转换为统一的密集表示,以便模型能够有效地解释和响应各种位置输入。
实验结果与性能评估
研究人员通过大量实验验证了 Madd 的有效性。实验结果表明,Madd 在功能性感知的对象插入任务上显著优于现有的最先进方法,并在野外图像上表现出强大的泛化性能。具体来说:
- SAM-FB 测试集上的可视化结果:在每组可视化结果中,最左边的图像是带有位置提示的背景。Madd 预测了插入对象的 RGB 图像和掩码,分别显示在每组的最后两张图像中。结果显示,Madd 能够根据不同的位置提示,将前景对象无缝地插入到背景中,且生成的图像质量高,细节丰富。
- 野外图像上的插入结果:在野外图像上,Madd 展示了出色的泛化能力。无论是在常见的对象(如椅子、汽车)还是不常见的对象(如动物、家具)上,Madd 都能更好地保持前景对象的外观,并根据背景场景调整其属性。此外,即使在提供模糊提示的情况下,Madd 也能生成合理的插入结果,展示了其强大的鲁棒性。
方法的优势与特点
- 功能性感知:Madd 通过显式建模插入掩码,确保前景对象不仅在视觉上与背景融合良好,还能在功能上与其环境相适应。
- 双流架构:Madd 同时对 RGB 图像和对象掩码进行去噪,确保生成的图像和掩码都具有高质量,增强了合成结果的真实感。
- 位置提示的灵活性:Madd 支持多种类型的位置提示,能够根据不同的提示灵活调整前景对象的插入位置,适用于各种应用场景。
- 强大的泛化能力:Madd 在野外图像上表现出色,能够在常见和不常见的对象上保持高质量的合成效果,展示了其广泛的适用性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











