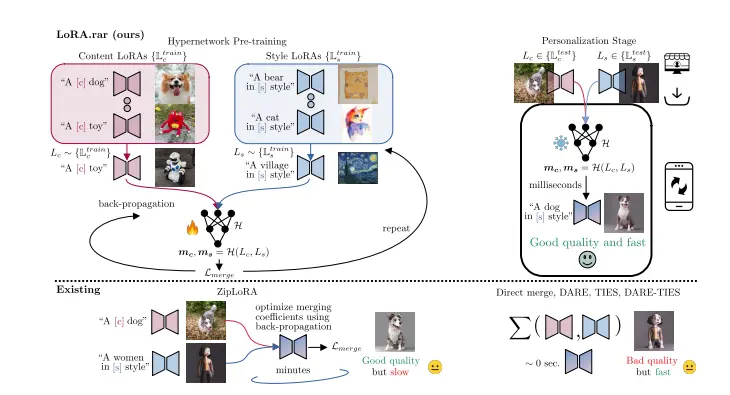
香港中文大学和字节跳动的研究人员提出了一种名为 Long Context Tuning(LCT,长上下文调优)的训练范式,通过将预训练的单镜头视频扩散模型扩展到场景级视频生成,以生成具有视觉和动态一致性的多镜头视频内容。
例如,电影《泰坦尼克号》中杰克和露丝在甲板上相遇的经典场景,包含多个镜头:杰克回头的特写镜头、露丝说话的中景镜头、露丝走向杰克的全景镜头以及杰克从背后拥抱露丝的特写镜头。这些镜头共同构成了一个连贯的场景,需要在视觉外观(如人物身份、背景、灯光和色调)和时间动态(如人物动作和镜头运动)上保持一致性。而现有的单镜头视频生成模型无法直接生成这种多镜头场景,LCT 方法就是为了解决这一问题而提出的。

主要功能
- 场景级视频生成:能够生成包含多个镜头的连贯视频场景,满足真实世界叙事视频(如电影、电视剧等)的创作需求。
- 镜头扩展功能:支持单镜头扩展(无镜头切换)和多镜头扩展(有镜头切换),可以将一个镜头或场景进一步延伸为更长的视频内容。
- 组合生成能力:可以接受人物身份图像和环境图像等作为条件输入,生成将这些元素无缝整合的视频,实现零样本的组合生成。
- 交互式镜头扩展:允许用户在生成过程中逐步添加新的镜头,根据已生成的内容进行交互式修改和扩展,为视频创作提供更大的灵活性。
主要特点
- 无需额外参数:LCT 方法在不引入额外参数的情况下,通过调整预训练模型的上下文窗口,扩展了模型的能力。
- 高效的自回归生成:通过将双向注意力模型微调为上下文因果注意力模型,利用 KV 缓存机制,显著降低了自回归生成过程中的计算开销。
- 强大的泛化能力:模型在训练过程中学习了场景级的视觉关系,因此能够自然地支持多种条件输入和组合生成,而无需针对特定任务进行额外训练。
工作原理
- 扩展上下文窗口:将单镜头视频扩散模型的上下文窗口从单个镜头扩展到整个场景,使模型能够直接从数据中学习跨镜头的一致性。
- 交错式三维位置嵌入:提出了一种交错式三维旋转位置嵌入(Interleaved 3D RoPE),为每个镜头分配独特的绝对位置,同时保持每个镜头内文本-视频令牌之间的相对位置关系。
- 异步噪声策略:在训练过程中,为每个镜头独立采样扩散时间步,而不是对所有镜头应用统一的时间步。这种策略允许模型在生成过程中动态地利用跨镜头的关系,例如将低噪声的镜头作为视觉条件来指导高噪声镜头的去噪过程。
- 上下文因果注意力微调:将双向注意力模型微调为上下文因果注意力模型,使得模型在自回归生成过程中能够更高效地利用历史信息,避免重复计算。

应用场景
- 短片创作:可以直接用于生成短片的多镜头场景,帮助创作者快速生成连贯的视频内容,减少拍摄和后期制作的工作量。
- 广告制作:能够根据广告脚本生成连贯的多镜头广告视频,快速展示产品或服务的使用场景和优势。
- 教育视频制作:能够生成用于教学的连贯视频内容,例如展示实验过程、历史事件重现等,增强教学的趣味性和直观性。
- 虚拟现实和增强现实内容创作:可以为 VR 和 AR 应用生成连贯的多镜头视频内容,提供更加丰富和真实的视觉体验。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











