
Freepik Tunes
Freepik Tunes 是一个创新的平台,提供由人工智能创作的免费音乐、画外音和音效生成工具,旨在帮助创作者轻松提升项目的音频体验。
由西北工业大学音频、语音与语言处理研究组(ASLP Lab)和香港中文大学(深圳)深圳大数据研究院共同开发的DiffRhythm(谛韵),是一款基于潜扩散技术(Latent Diffusion)的新型端到端全长度歌曲生成模型。它旨在克服现有音乐生成方法的局限,如只能生成人声或伴奏、依赖复杂的多阶段架构、生成速度慢以及无法生成完整长度歌曲等。
| 模型 | HuggingFace |
|---|---|
| DiffRhythm-base (1m35s) | https://huggingface.co/ASLP-lab/DiffRhythm-base |
| DiffRhythm-full (4m45s) | Coming soon... |
| DiffRhythm-vae | https://huggingface.co/ASLP-lab/DiffRhythm-vae |
为了使用DiffRhythm生成音乐,您需要遵循特定的格式要求:
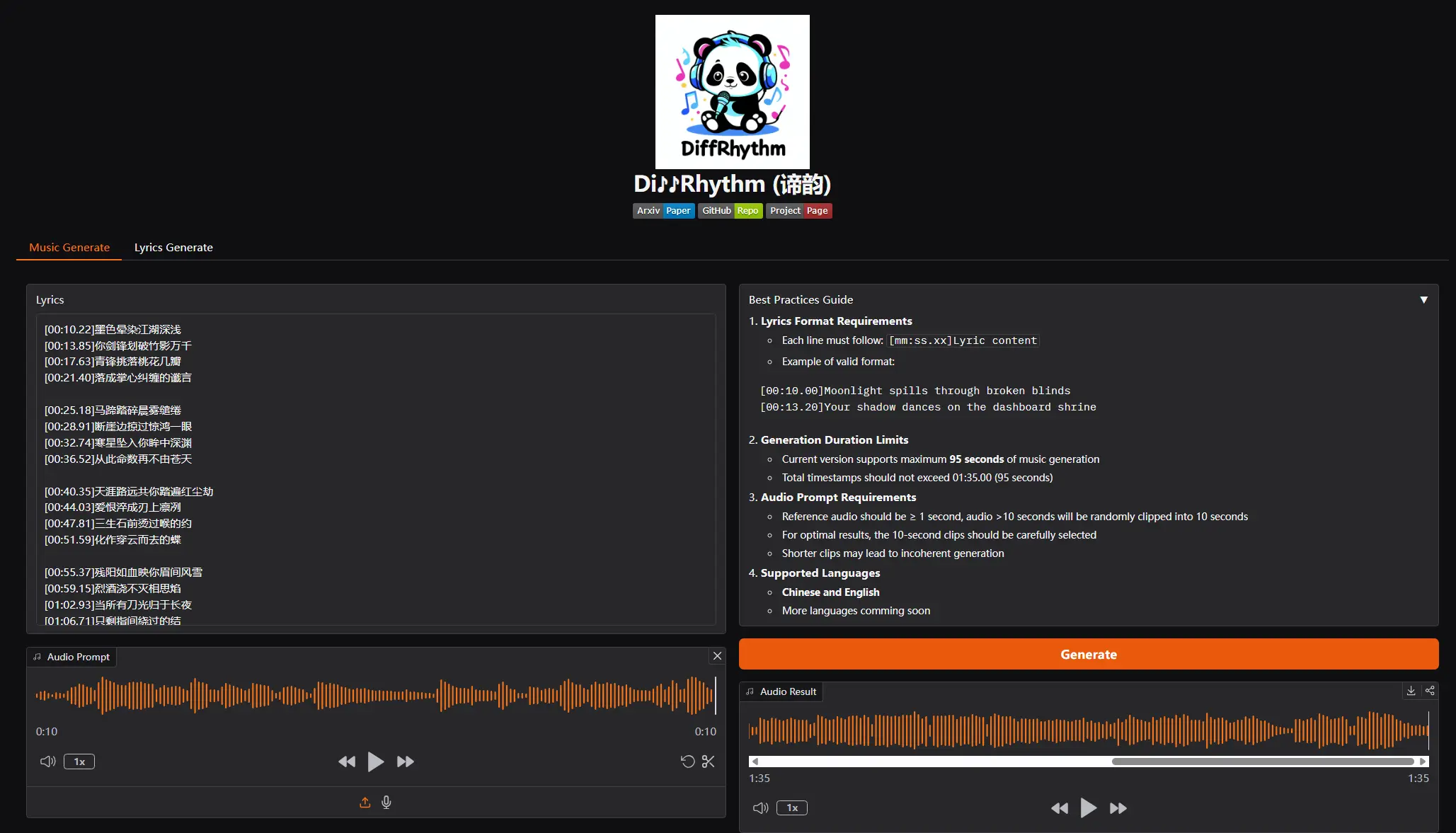
[mm:ss.xx]歌词内容。1、生成歌词
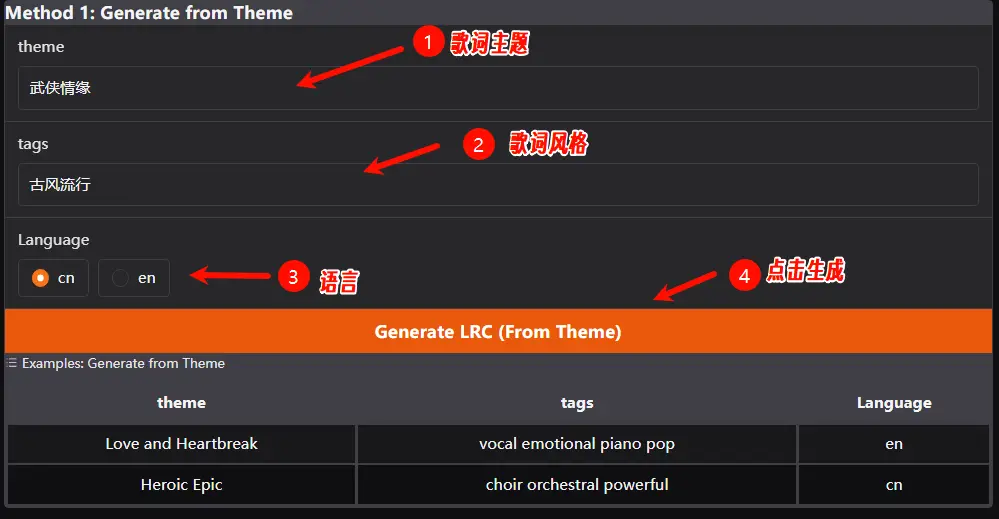
官方提供了两种歌词生成方法:主题生成和自定义生成。选择歌词生成选项,可以按照主题进行生成,如下图提示,目前支持 中文 和 英文。
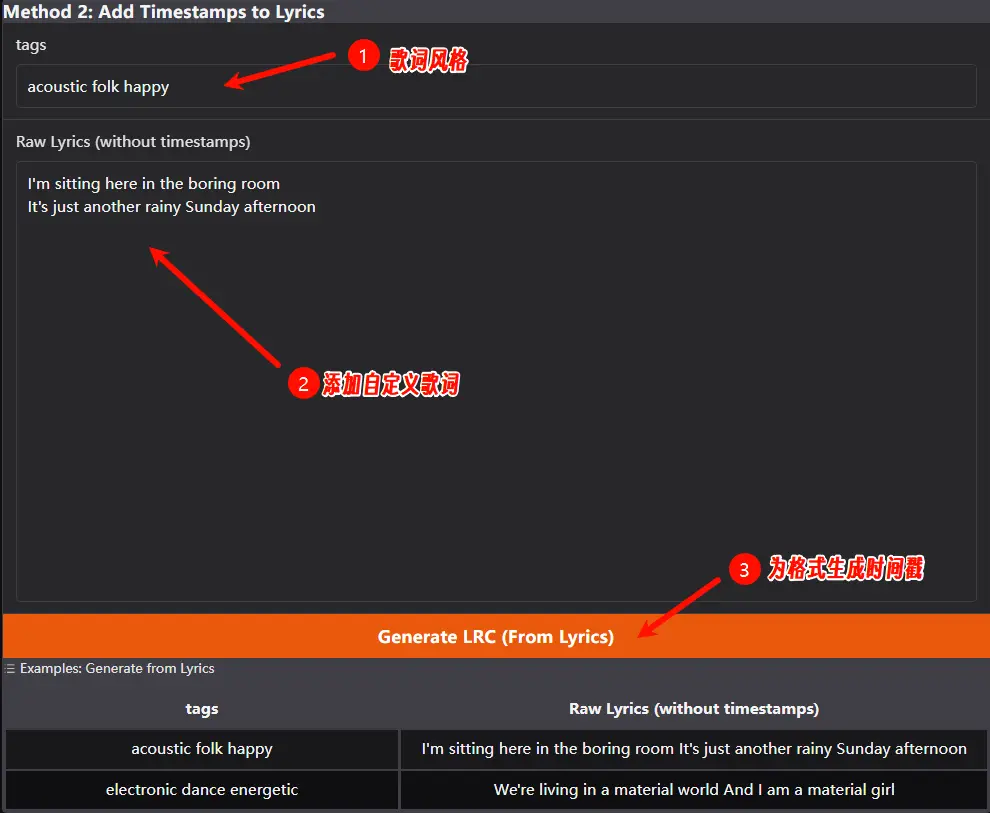
自定义生成,可以添加自己书写的歌词,然后生成时间戳;当前版本支持最长 95 秒的音乐生成,因此你的歌词总时间戳不应超过 01:35.00。
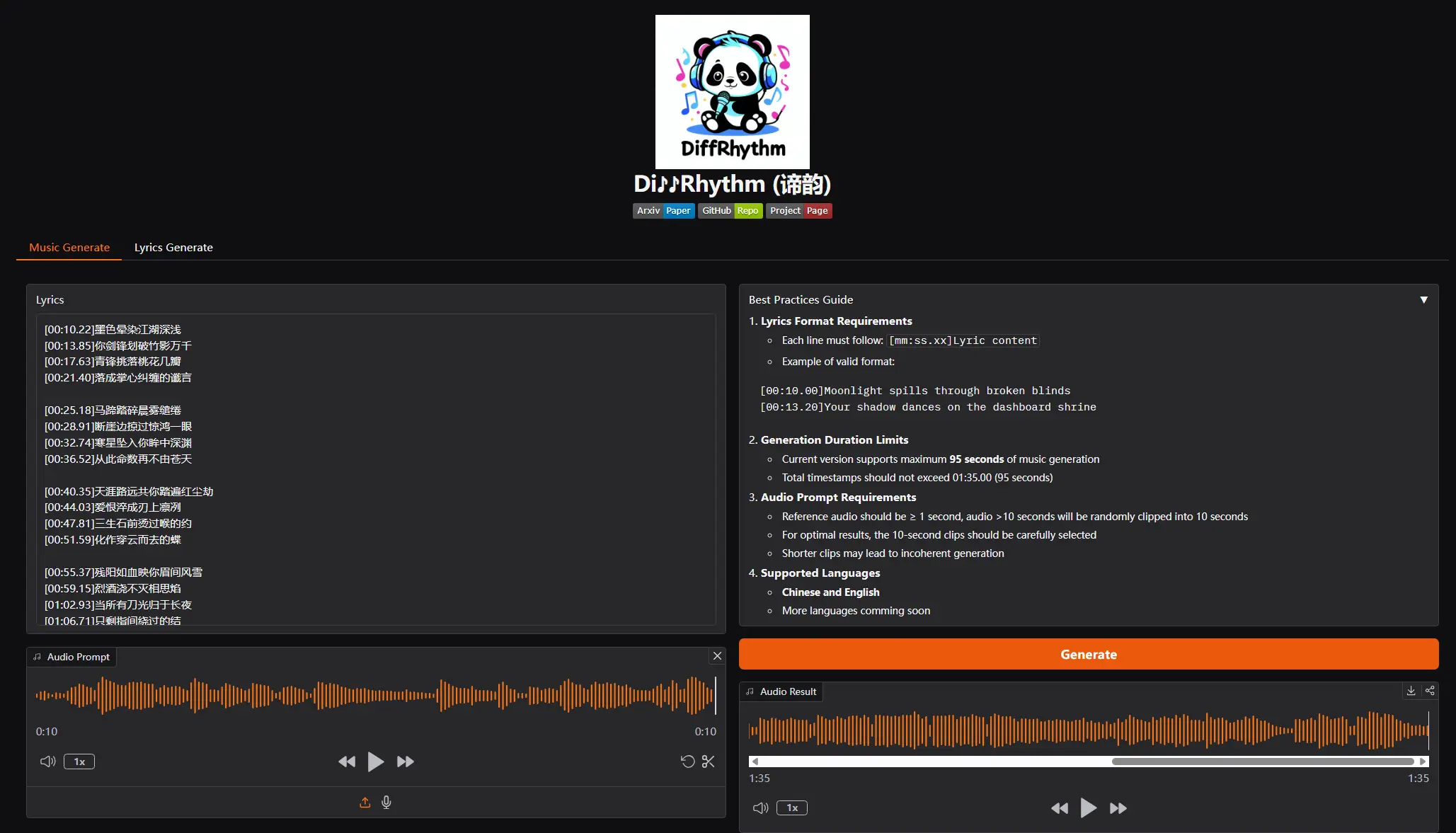
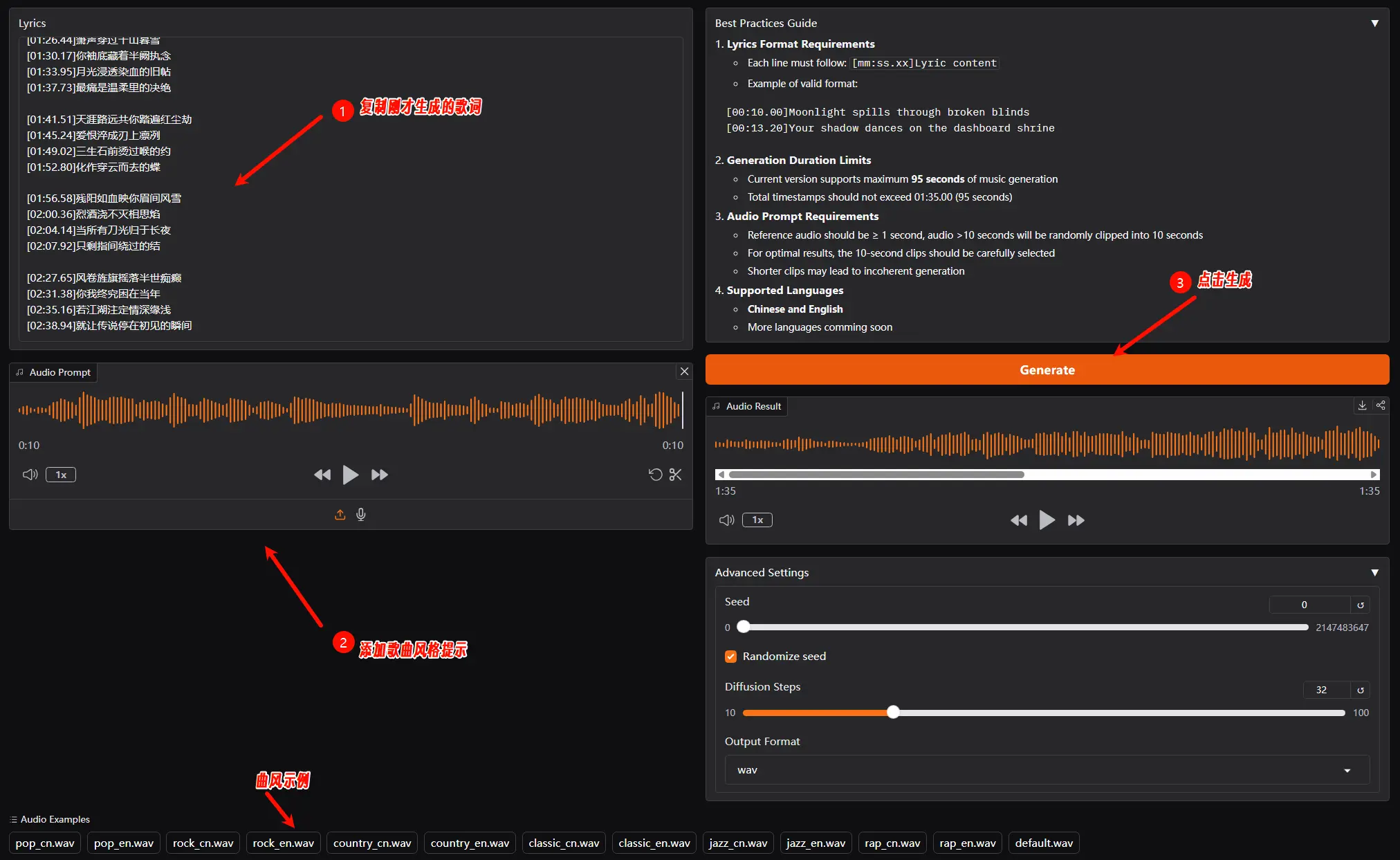
2、歌曲生成
复制刚才生成的歌词到歌词框,上传或选择示例曲风,点击生成歌曲。
推荐使用pinokio工具进行一键安装,本地运行DiffRhythm仅需8GB显存,便能在10至12秒内生成一首完整的歌曲。