
人类运动生成的交互式编辑是一个重要的研究领域,特别是在动画、游戏和虚拟现实等应用中。然而,现有的运动扩散模型存在两个主要问题:
- 缺乏对词级文本-运动对应关系的显式建模:这限制了模型在细粒度编辑方面的能力。
- 缺乏良好的可解释性:这使得用户难以理解模型的工作原理和编辑效果。
为了解决这些问题,清华大学、国际数字经济学院(IDEA)和香港中文大学的研究人员提出了一种基于注意力的运动扩散模型——MotionCLR,它是一个基于注意力机制的人体动作生成和编辑框架。MotionCLR通过理解和操作注意力图谱来实现对动作的生成和编辑,而无需额外的训练。例如,可以通过调整“跳跃”动作的权重来强调或减弱该动作,或者将“走路”替换为“跳舞”来改变动作内容。
- 项目主页:https://lhchen.top/MotionCLR
- GitHub:https://github.com/IDEA-Research/MotionCLR
- Demo:https://huggingface.co/spaces/EvanTHU/MotionCLR

主要功能和特点
- 动作编辑能力:MotionCLR能够通过调整注意力权重来精细控制动作的强调或减弱,实现动作的替换和序列调整。
- 无需训练的编辑:与传统模型不同,MotionCLR能够在不重新训练的情况下,直接对生成的动作进行编辑。
- 基于注意力的模型:模型利用自注意力和交叉注意力机制来分别建模动作帧间的关系和文本与动作帧间的对应关系。
- 清晰的文本-动作对应:通过交叉注意力机制,模型在词级别上显式地建模文本和动作之间的对应关系,提高了生成动作的质量和对文本描述的准确性。

MotionCLR 模型架构
MotionCLR 采用了 CLeaR 建模的注意力机制,分别使用自注意力和交叉注意力来建模模态内和跨模态的交互。
自注意力机制:
- 目的:衡量帧之间的序列相似性,并影响运动特征的顺序。
- 作用:确保运动序列的内部一致性,捕获时间上的依赖关系。
交叉注意力机制:
- 目的:找到细粒度的词-序列对应关系,并在运动序列中激活相应的时刻。
- 作用:实现文本和运动之间的精确匹配,支持细粒度的编辑操作。
运动编辑方法
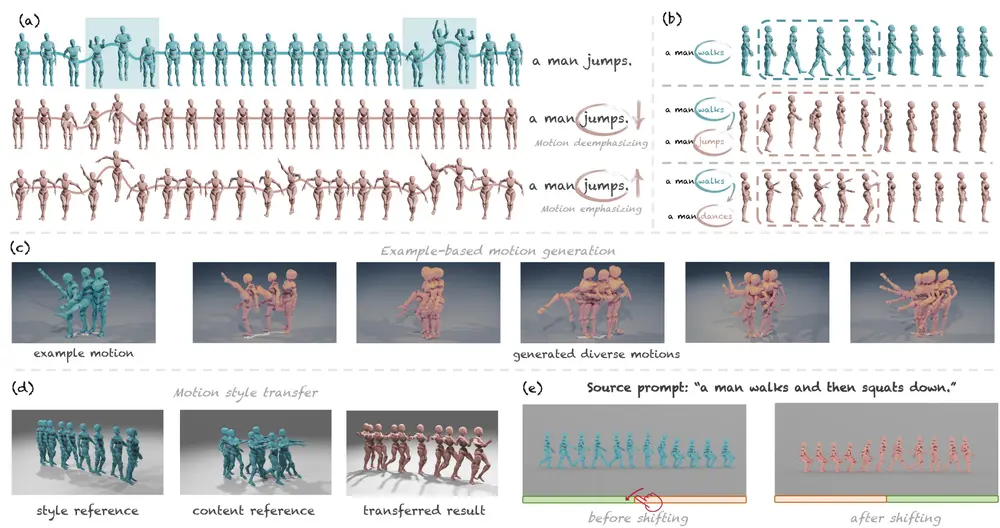
基于上述注意力机制,研究人员开发了一系列简单而有效的运动编辑方法:
- 运动强调:通过增强注意力图中的特定区域,增加特定运动的权重。
- 运动去强调:通过减弱注意力图中的特定区域,减少特定运动的权重。
- 就地运动替换:通过修改注意力图,将一个运动序列中的特定部分替换为另一个运动序列中的相应部分。
- 基于示例的运动生成:通过参考已有的运动示例,生成新的运动序列。
注意力机制的可解释性
为了验证注意力机制的可解释性,研究人员进行了以下探索:
- 动作计数:通过分析注意力图,自动计数运动序列中的特定动作。
- 基于基础的运动生成:通过调整注意力图,生成基于特定基础动作的运动序列。
实验结果
实验结果表明,MotionCLR 模型具有以下优点:
- 生成能力:能够生成高质量的运动序列,保持自然流畅。
- 编辑能力:支持细粒度的运动编辑操作,如运动强调、去强调和替换。
- 可解释性:通过注意力图,用户可以直观地理解模型的工作原理和编辑效果。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











