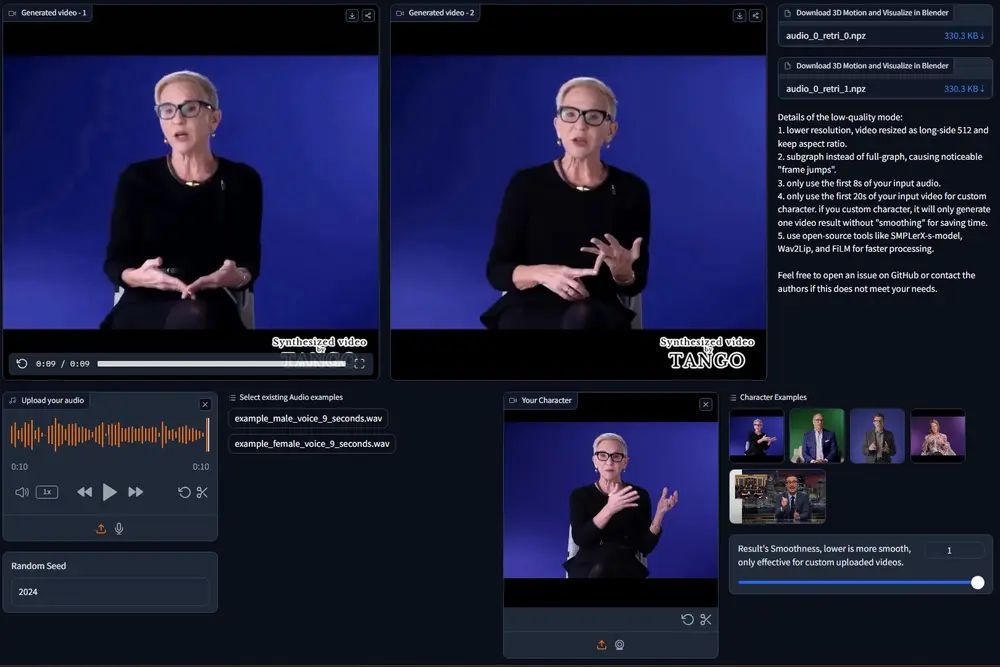
AI驱动的视频生成领域正在迅速发展,图像到视频(I2V)模型因其视觉一致性和增强的可控性而处于前沿。然而,一个显著的差距一直存在:缺乏专门的数据集来理解图像到视频提示的独特需求。为了填补这一空白,悉尼科技大学和浙江大学的研究人员推出一个名为TIP-I2V的大规模真实文本和图像提示数据集,TIP-I2V数据集包含了超过170万独特的用户提供的文本和图像提示,以及由五个最先进的图像到视频扩散模型生成的视频,这是第一个专门为I2V模型量身定制的大规模数据集。
- 项目主页:https://tip-i2v.github.io
- GitHub:https://github.com/WangWenhao0716/TIP-I2V
- 数据:https://huggingface.co/datasets/WenhaoWang/TIP-I2V

TIP-I2V数据集的特点
1、大规模用户提示:
数量:超过170万个独特的用户提供的提示。 多样性:来自多样化的用户群体,涵盖广泛的主题和风格。
2、多模型生成视频:
模型:包括五个领先的图像到视频模型生成的相应视频。 多样性:不同模型生成的视频提供了丰富的对比和分析机会。
3、语义差异:
深度分析:TIP-I2V不仅提供了广泛的提示多样性,还提供了影响视频生成的语义差异的见解。
4、与现有数据集的比较:
VidProM:文本到视频数据集。 DiffusionDB:文本到图像数据集。 独特性:TIP-I2V专门针对图像到视频提示,提供了更广泛的提示多样性和更深入的语义分析。
新研究方向
1、用户偏好分析:
大规模分析:利用数据集中庞大的提示阵列,研究人员可以大规模分析用户偏好,调整模型以更好地满足这些需求。
2、新基准开发:
多维度评估:TIP-I2V支持开发新的基准,更准确地评估模型在多个维度上的性能,如视觉质量、时间一致性和提示遵循。
3、安全问题解决:
错误信息检测:通过追踪生成的视频回到其源图像,TIP-I2V提供了一种结构化的方法,以检测和解决错误信息问题。 透明度和问责制:确保AI生成过程中的透明度和问责制,提高模型的安全性和可靠性。
提高AI生成内容的安全性和可靠性
1、理解错误信息风险:
风险识别:有了TIP-I2V,开发者可以更好地理解潜在的错误信息风险。 保障措施:设计保障措施,确保生成的内容准确、可信。
2、透明度和问责制:
溯源能力:通过将生成的视频追溯到其提示来源,TIP-I2V提供了一种方法,确保AI生成过程的透明度和问责制。
TIP-I2V作为同类数据集中的第一个,为推进图像到视频的研究和开发提供了重要资源。凭借其庞大的规模、详细的提示以及与实际用户需求的契合,TIP-I2V有望推动整个领域的创新,从改进以用户为中心的模型到更好的安全性和基准标准。通过鼓励研究社区在TIP-I2V的基础上进行构建,该数据集将成为图像到视频技术演进中的基石,支持未来更安全、更适应的AI应用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











