
来自加州大学圣地亚哥分校和Adobe的研究人员推出大型3D重建模型MeshLRM,这是一种新颖的基于LRM的方法,它能在不到一秒的时间内,能够从极少量的输入图像(仅需四张)快速重建出高质量的3D网格模型。这项技术对于3D视觉、图形应用以及3D编辑、渲染和仿真工具来说非常重要,因为这些应用和工具特别针对3D网格模型进行了优化。例如,如果一个游戏开发者想要创建一个虚拟的城堡,他们只需要提供城堡的四张不同角度的照片,MeshLRM 就能够快速生成城堡的3D网格模型,这个模型可以直接用于游戏开发中,大大减少了手动建模的时间和成本。
与以往主要基于NeRF进行重建的大型重建模型(LRMs)不同,MeshLRM在LRM框架内融入了可微分的网格提取和渲染技术。这使得我们能够通过微调具有网格渲染功能的预训练NeRF LRM,实现端到端的网格重建。此外,开发团队还简化了先前LRMs中的复杂设计,进一步优化了LRM架构。MeshLRM的NeRF初始化过程结合了低分辨率和高分辨率图像的顺序训练;这种新的LRM训练策略显著提高了收敛速度,从而在减少计算量的同时保证了重建质量。我们的方法不仅在稀疏视图输入的网格重建方面达到了业界领先水平,还适用于多种下游应用,如文本到3D和单图像到3D的生成。

主要功能:
MeshLRM 的主要功能是高效、准确地创建3D资产,通过少量图像快速重建出直接用于网络推断的3D网格模型,无需针对每个场景进行优化。
主要特点:
- 快速重建: MeshLRM 可以在不到一秒钟的时间内从四张输入图像重建出高质量的3D网格。
- 简化设计: 它通过简化先前大型重建模型(LRMs)中的复杂设计,提高了模型的训练和推理速度。
- 端到端优化: MeshLRM 整合了不同的3D表示和渲染技术,允许端到端的网格重建。
- 新颖的训练策略: 它采用了一种新的训练策略,先使用低分辨率图像进行预训练,然后使用高分辨率图像进行微调,从而加快了模型的收敛速度。
工作原理:
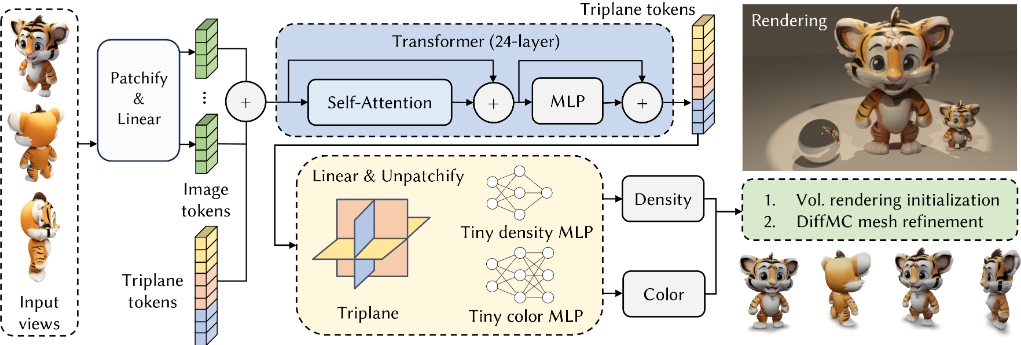
关于MeshLRM的模型架构,首先,图像被分割成小块并转化为令牌。接着,转换器将这些图像令牌和三平面令牌拼接起来作为输入。然后,输出的三平面令牌通过取消分割操作符进行上采样,而输出的图像令牌则会被丢弃(在图中未显示)。此外,该模型还集成了两个小型MLP,分别用于密度和颜色的解码,从而支持体积渲染和DiffMC微调。最终,我们在图的右侧展示了生成的网格输出。
MeshLRM 的工作原理基于以下几个步骤:
- 图像令牌化: 将输入图像转换为特征图,并将相机参数转换为特定的坐标系,然后将这些特征输入到一个基于自注意力机制的变换器模型中。
- 变换器架构: 使用一个深度变换器网络来处理多视图图像令牌和可学习的triplane(位置)嵌入,输出用于渲染的triplane特征。
- 体积渲染训练: 通过基于射线步进的体积渲染来训练模型,为网格重建提供良好的初始化权重。
- 表面渲染微调: 使用可微分的Marching Cubes(DiffMC)技术和可微分的光栅化器,对预测的密度场进行网格表面提取,并通过最小化表面渲染损失来优化模型。
具体应用场景:
MeshLRM 可以应用于多种场景,包括但不限于:
- 3D内容创建: 艺术家和设计师可以快速从少量图像创建复杂的3D模型,用于游戏、电影或虚拟现实体验。
- 自动化3D建模: 在电子商务中,快速生成产品的3D模型,用于在线展示和增强现实体验。
- 文化遗产保护: 对历史遗迹和文物进行3D扫描和重建,以便于研究和保护。
- 游戏开发: 快速生成游戏资产和环境的3D模型,加速游戏设计流程。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











