新加坡科技设计大学和密歇根大学的研究人员推出新型文本到音频生成模型Tango 2,它通过直接偏好优化(Direct Preference Optimization, DPO)来提高音频生成的质量和与文本的匹配度。例如,你有一个故事或场景的描述,Tango 2能够根据这个描述生成与之匹配的音频。这就像有一个私人DJ,根据你的描述播放出完美的背景音乐。
- 项目主页:https://tango2-web.github.io
- GitHub:https://github.com/declare-lab/tango
- 模型:https://huggingface.co/datasets/declare-lab/audio-alpaca
- 数据:https://huggingface.co/declare-lab/tango2
许多基于扩散的文本到音频模型在训练时主要关注在大量提示-音频对数据集上构建日益复杂的扩散模型,却忽视了输出音频中概念或事件的存在以及它们与输入提示之间的时间顺序。开发团队的假设是,若能在模型训练中更多地关注这些方面,即使在数据有限的情况下,也能提高音频生成的性能。因此,在这项研究中,开发团队使用现有的文本到音频模型 Tango,合成了一个偏好数据集。在这个数据集中,每个提示都对应一个最佳音频输出和一些较差的音频输出,以供扩散模型学习。理论上,较差的音频输出中可能缺失了某些概念,或者这些概念的排列顺序不正确。
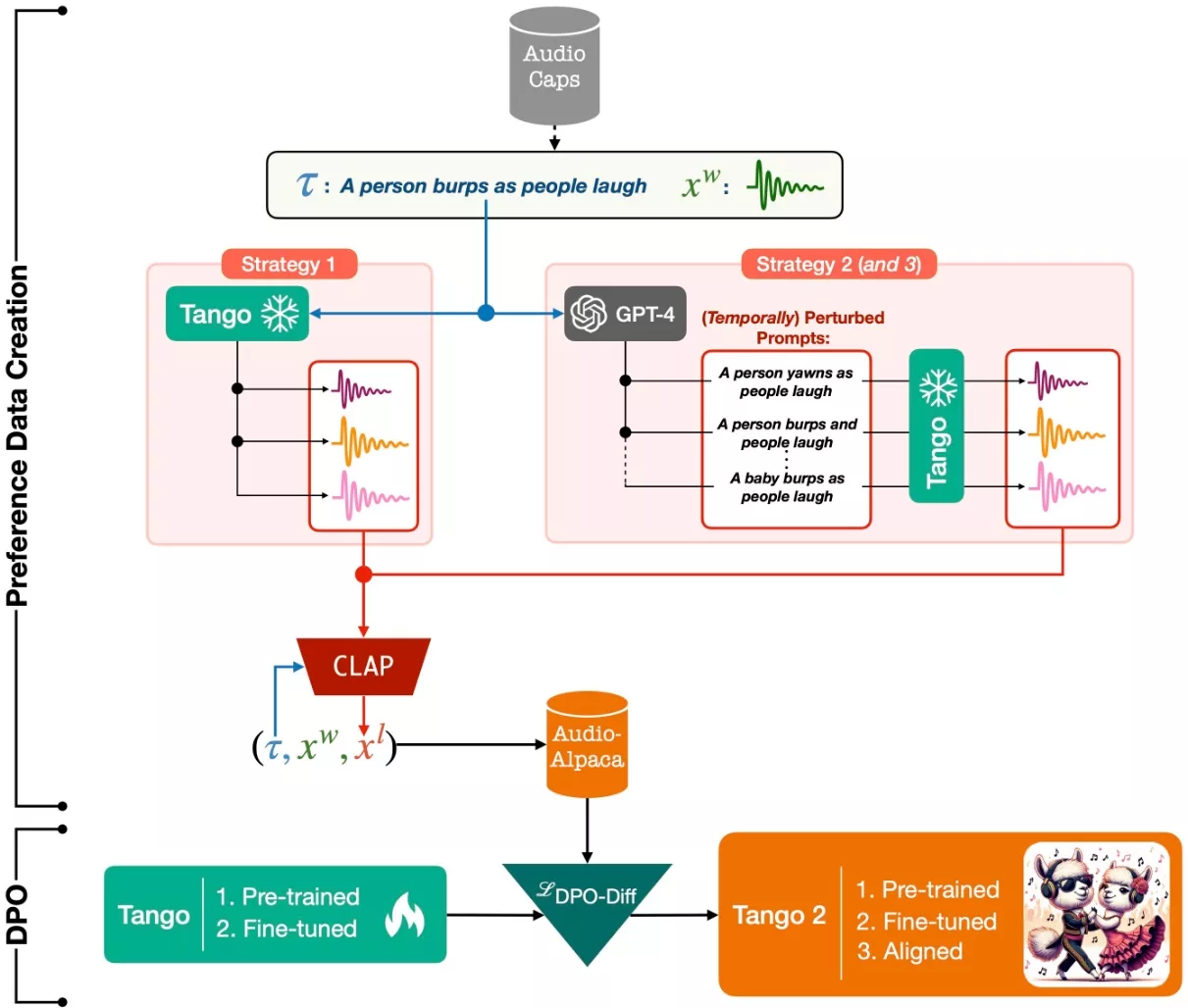
随后,开发团队使用扩散-DPO(直接偏好优化)损失函数,对这个偏好数据集进行微调,以优化公开可用的 Tango 文本到音频模型。实验结果显示,经过微调后的模型在自动和手动评估指标方面均优于原始的 Tango 模型以及 AudioLDM2,从而显著提高了音频生成的质量。
主要功能和特点:
- 高度匹配:Tango 2能够生成与文本描述高度匹配的音频,确保音频内容与文本中提到的概念和事件顺序相符。
- 偏好学习:通过使用DPO方法,模型能够从好的和不好的音频样本中学习,从而提高生成音频的质量。
- 自动化数据生成:论文提出了一种自动化生成偏好数据集的方法,这个数据集包含了好的音频样本(赢家)和不好的音频样本(输家),用于训练和优化模型。
- 性能提升:与之前的模型相比,Tango 2在客观和主观评价指标上都取得了显著的提升。
工作原理:
Tango 2的工作原理基于两个主要步骤:首先,它使用一个预训练的文本到音频模型Tango,通过三种策略生成音频样本,并将它们与原始文本描述进行比较,以创建一个包含偏好信息的数据集Audio-alpaca。然后,它使用DPO-diffusion损失函数对这个数据集进行微调,以学习如何生成更符合人类偏好的音频。
具体应用场景:
- 电影和游戏制作:在电影和游戏中,声音设计是非常重要的一环。Tango 2可以根据脚本生成背景音乐和音效,提高制作效率。
- 有声读物和播客:自动生成与文本内容匹配的音频,可以用于有声读物的制作或播客的背景音。
- 虚拟现实和增强现实:在虚拟现实和增强现实应用中,根据用户的环境和活动生成相应的音频,提升沉浸式体验。
- 教育和辅助工具:为教育内容生成音频描述,帮助视障人士更好地理解教材内容。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











