
斯坦福大学的研究人员推出Diffusion Self-Distillation,这是一种基于扩散模型的技术,用于零样本(Zero-Shot)定制化图像生成。这种方法可以在不需要额外推理阶段训练的情况下,即时定制和适应任何角色或资产在文本到图像扩散模型中的身份。与传统方法相比,Diffusion Self-Distillation提供了更精确的控制和可编辑性,这对于现实世界的应用来说至关重要。
例如,你是一名艺术家,想要创造一系列以特定角色在不同情境下的图像。使用Diffusion Self-Distillation,你可以输入一个角色的参考图像和描述这个角色在新情境下的文本提示,模型将生成保持角色身份一致性的同时展现不同表情、姿势或光照条件的图像。

主要功能和特点
- 零样本定制化:无需额外的训练数据,即可实现对特定实例的定制化生成。
- 身份保持生成:在不同上下文中保持角色或资产的身份一致性。
- 快速适应:能够迅速适应新的角色或资产,无需针对每个参考样本进行训练。
- 精确控制:提供对生成图像的精确控制,包括风格、纹理等局部特征的调整。
工作原理
Diffusion Self-Distillation的工作原理包括以下几个步骤:
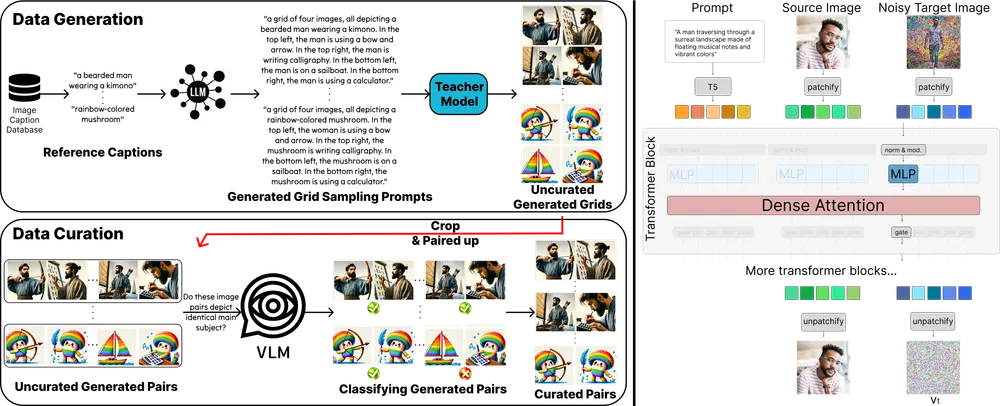
- 数据生成:利用预训练的文本到图像扩散模型和大型语言模型(LLMs)生成一系列可能保持身份一致的图像。
- 数据策展:使用视觉-语言模型(VLMs)自动策展生成的图像,筛选出具有期望身份一致性的干净图像集。
- 模型微调:将预训练的扩散模型微调为文本+图像到图像模型,使用策展的数据集进行监督学习。
具体应用场景
- 漫画和数字艺术:艺术家可以快速迭代和适应他们的作品,增强创作自由度。
- 角色生成:在游戏或电影制作中,保持角色在不同场景下的外观一致性。
- 场景重光照:改变图像的光照条件,同时保持场景内容不变。
- 资产定制:在产品设计中,根据客户需求定制产品图像,如家具、服装等。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











