
基于校正流的DiT模型,如FLUX和OpenSora,在图像和视频生成领域展示了卓越的性能。然而,这些模型在反演过程中存在不准确的问题,这限制了它们在图像和视频编辑等下游任务中的有效性。为了解决这一问题,清华大学、腾讯ARC实验室和香港科技大学的研究人员提出了一种无需训练的采样器——RF-Solver,通过减少求解校正流ODE过程中的误差来提高反演精度。
RF-Solver用于改进基于矫正流(rectified flow)的生成模型在图像和视频生成、反转和编辑任务中的性能。RF-Solver通过减少解决矫正流常微分方程(ODE)过程中的误差,提高了采样质量和反转重建的准确性。此外,该团队还提出了RF-Edit,这是一个利用RF-Solver进行图像和视频编辑的框架。

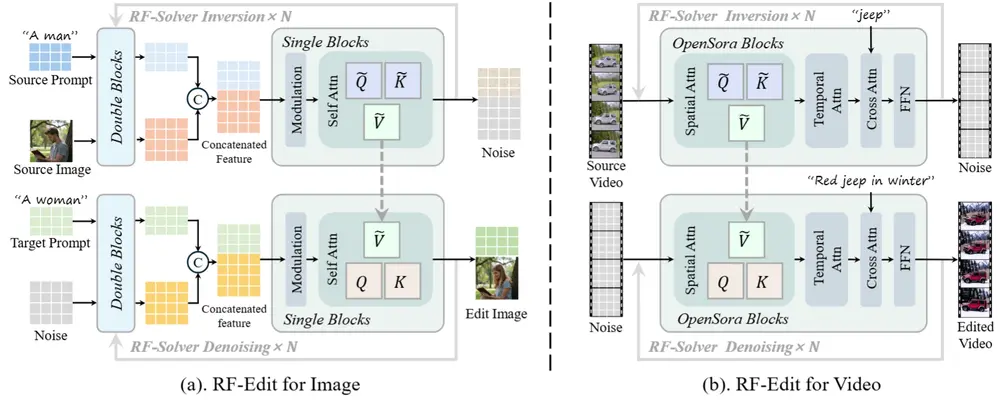
例如,在图像编辑任务中,RF-Edit能够将图像中的“一个男人”(A man)替换为“一个女人”(A woman),同时保持背景和其他无关区域不变。在视频编辑中,RF-Edit能够处理复杂的编辑要求,如将视频中的“三只狮子”中的“最左边的狮子”变为“一只白色的北极熊”,并将“另外两只小狮子”变为“橙色的虎崽。
主要功能:
RF-Solver:这是一个无需训练的采样器,能够通过减少ODE求解过程中的误差来提高矫正流模型的反转和重建精度。 RF-Edit:这是一个图像和视频编辑框架,它在编辑过程中共享自注意力层的特征,以保持源图像或视频的结构信息,同时实现高质量的编辑结果。
RF-Solver的工作原理
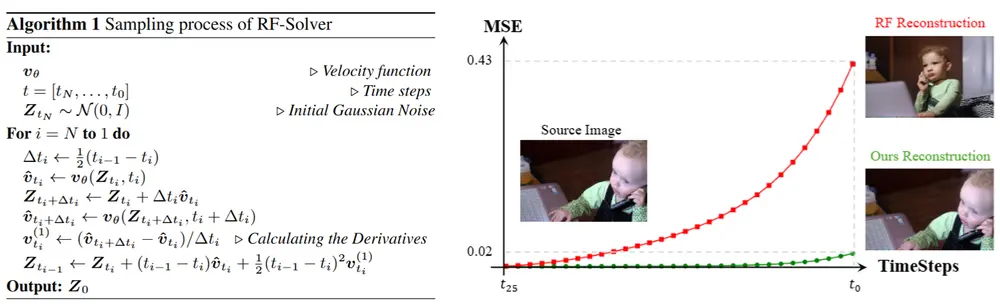
精确公式推导:研究团队首先推导了校正流ODE的精确公式。这一步骤确保了模型在求解过程中能够更准确地捕捉到数据分布的变化。 高阶泰勒展开:为了估计校正流ODE的非线性成分,研究团队采用了高阶泰勒展开。这种方法显著降低了每个时间步的近似误差,从而提高了反演的准确性。 减少近似误差:通过精确公式和高阶泰勒展开,RF-Solver能够在求解校正流ODE的过程中减少近似误差,从而提高反演精度。
RF-Edit的设计
基于RF-Solver,研究团队进一步设计了RF-Edit,这是一种专门用于图像和视频编辑的方法。RF-Edit包含以下子模块:
自注意力层特征共享:在编辑过程中,RF-Edit通过共享自注意力层特征,保留了源图像或视频的结构信息。这有助于在编辑过程中保持原始内容的连贯性和一致性。 高质量编辑结果:通过减少反演误差和保留结构信息,RF-Edit能够在保留源图像或视频的结构信息的同时,实现高质量的编辑结果。
方法的优势
兼容性:RF-Solver和RF-Edit兼容任何预训练的基于校正流的图像和视频任务模型,无需额外的训练或优化。这使得它们可以轻松应用于现有的生成模型,提高其在编辑任务中的性能。 广泛适用性:该方法在文本到图像生成、图像与视频反演以及图像与视频编辑等多个任务上进行了广泛的实验,证明了其强大的性能和适应性。
实验结果
研究团队在多个任务上进行了实验,包括:
文本到图像生成:RF-Edit在生成高质量图像的同时,能够准确地反映文本描述的内容。 图像与视频反演: RF-Solver显著提高了图像和视频的反演精度,减少了反演过程中的误差。 图像与视频编辑:RF-Edit在编辑过程中保留了源图像或视频的结构信息,实现了高质量的编辑结果。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











