
视频生成是一个复杂而多样的任务,涉及多个条件的控制,如摄像机轨迹、文本提示和用户运动注释。现有的方法通常只能在特定条件下生成视频,缺乏灵活性和一致性。为了解决这些问题,浙江大学 CAD&CG 国家重点实验室、清华大学、北京航空航天大学、浙江工商大学和生数科技的研究人员提出了一种统一的控制视频生成方法—AnimateAnything,它能够实现对视频内容的精确和一致性的操控,包括相机轨迹、文本提示和用户运动注释等多种条件。这种方法特别适用于需要对视频进行精细控制的场景,如电影制作和虚拟现实。
- 项目主页:https://yu-shaonian.github.io/Animate_Anything
- GitHub:https://github.com/yu-shaonian/AnimateAnything
例如,假设你想要生成一个视频,其中包含一个棕色骏马在山坡上悠闲漫步的场景。使用AnimateAnything,你可以通过提供一张棕色骏马的参考图片和一个描述性文本提示(如"A brown stallion leisurely strolls on the hillside"),该方法能够生成一个清晰稳定的视频,同时保持与参考对象的外观细节一致性。

主要功能:
- 多条件视频操控:AnimateAnything能够处理包括相机轨迹、文本提示和用户运动注释在内的多种控制信号,实现对视频的精确操控。
- 统一运动表示:通过设计一个多尺度控制特征融合网络,将所有控制信息转换为逐帧光流,用于指导最终的视频生成。
- 频率域稳定模块:为了减少大规模运动引起的闪烁问题,提出了一个基于频率的稳定模块,通过确保视频的频域一致性来增强时间连贯性。
主要特点:
- 高精确度:通过将控制信号转换为光流,AnimateAnything能够实现对视频生成过程的精确控制。
- 灵活性:支持多种控制信号,使得视频生成更加灵活,能够适应不同的应用需求。
- 稳定性:通过频域稳定模块,有效减少了视频生成中的闪烁和不连贯问题。
方法概述
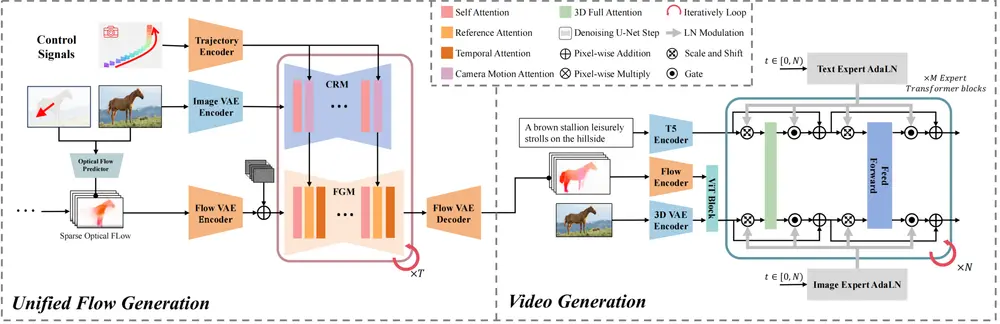
AnimateAnything 的核心思想是通过一个多尺度控制特征融合网络(Multi-scale Control Feature Fusion Network, MCFN)来构建不同条件的通用运动表示。具体步骤如下:
1、多尺度控制特征融合网络(MCFN):
- 特征提取:MCFN 从不同的控制信息中提取特征,如摄像机轨迹、文本提示和用户运动注释。
- 特征融合:通过多尺度融合机制,MCFN 将不同条件的特征融合在一起,形成一个通用的运动表示。
- 光流生成:MCFN 明确地将所有控制信息转换为逐帧的光流,这些光流作为运动先验来指导最终的视频生成。
2、基于频率的稳定模块:
- 频域一致性:为了减少由大规模运动引起的闪烁问题,提出了一种基于频率的稳定模块。该模块通过确保视频的频域一致性来增强时间连贯性。
- 频率分析:通过对视频帧的频域分析,稳定模块检测并修正可能引起闪烁的高频成分,从而提高视频的质量和稳定性。
工作原理:
AnimateAnything的工作流程分为两个阶段:
- 统一光流生成:在第一阶段,系统将不同的视觉控制信号(如箭头运动注释、相机运动和参考视频)转换为统一的光流表示,用于指导视频生成。
- 视频生成:在第二阶段,使用生成的统一光流和文本嵌入,通过视频生成模型创建最终视频。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











