
在大语言模型领域,专家混合(MoE)架构因其能在不显著增加计算量的情况下提升模型容量而受到青睐。但MoE模型在GPU间通信方面面临挑战,传统的全对全通信方法可能成为瓶颈。为此,深度求索开源第二弹DeepEP,一款专为MoE模型和专家并行(EP)设计的开源通信库。

DeepEP:MoE模型的通信优化
DeepEP通过提供高吞吐量、低延迟的GPU内核,解决了token在GPU间分发和聚合时的效率问题。它支持低精度操作(如FP8),与DeepSeek-V3论文中的技术保持一致,直接应对了在节点内和节点间扩展MoE架构的挑战。
技术优势
DeepEP提供两种主要类型的内核:
- 常规内核:针对高吞吐量场景优化,如推理预填充阶段或训练过程,利用NVLink和RDMA网络技术高效转发数据。
- 低延迟内核:专为高响应速度的推理任务设计,仅依赖RDMA,处理小批量数据,采用基于钩子的通信-计算重叠技术。
此外,DeepEP通过自适应配置提供灵活性,用户可以调整参数或设置环境变量来管理流量隔离。
性能表现
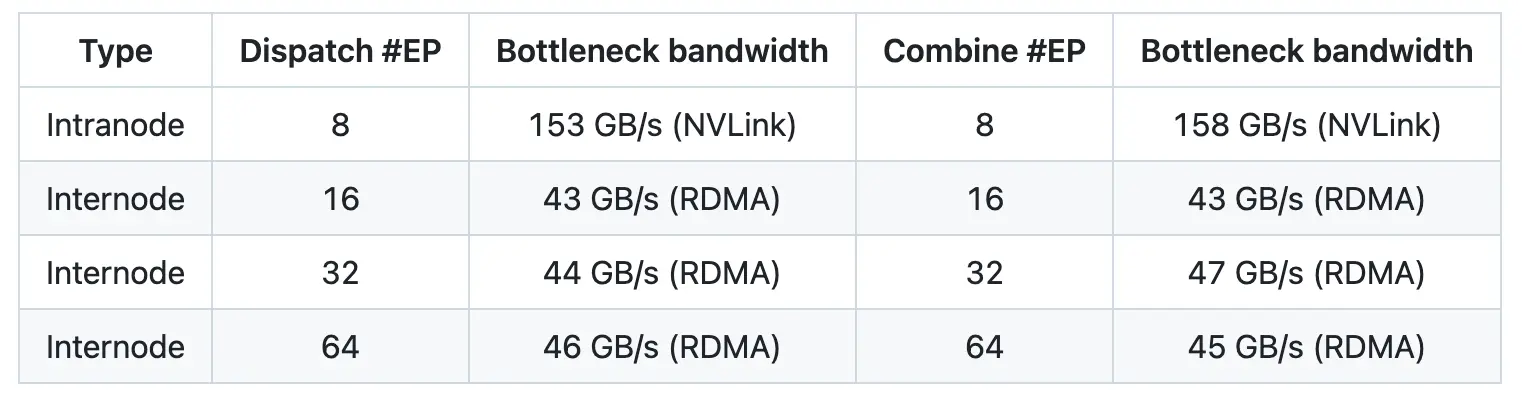
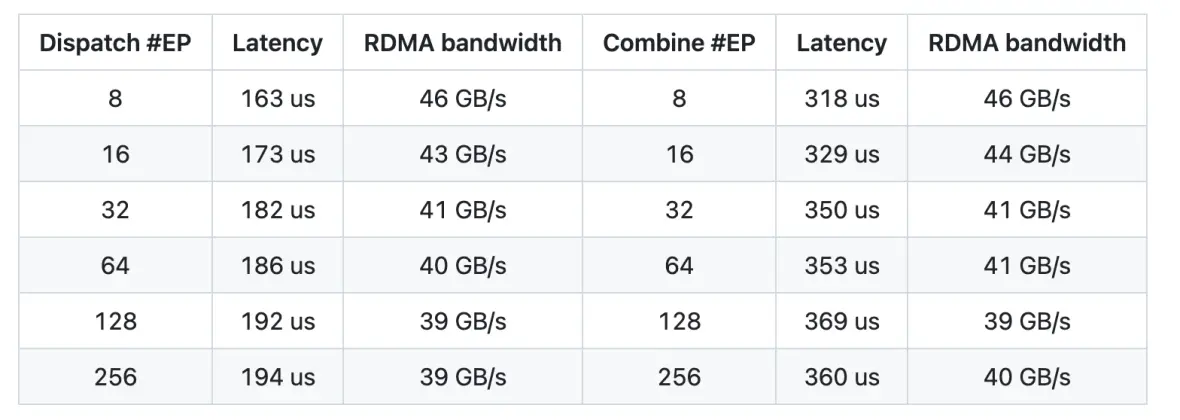
DeepEP的性能指标令人印象深刻。节点内通信吞吐量可达153GB/s,节点间使用RDMA时保持在43–47GB/s。低延迟内核在处理128个token并涉及8个专家的任务时,分发延迟可低至163微秒。
实际应用
这些优化意味着整体推理过程更加高效,支持更大的批量大小,并实现了计算与通信之间的平滑重叠。FP8支持不仅降低了内存占用,还加快了数据传输速度,这对于在资源有限的环境中部署模型至关重要。
DeepEP的贡献
DeepEP是对大规模语言模型部署领域的一项重要贡献。它通过解决MoE架构中的关键通信瓶颈,实现了更高效的训练和推理。其双内核设计为多种应用提供了灵活性,支持低精度操作,并配备了自适应配置机制,为研究人员和开发者提供了一个实用的工具,以进一步优化专家并行。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











